ПОДРОБНОЕ ОБСУЖДЕНИЕ ЛОГИКИ УПРАВЛЕНИЯ
Рассмотрим сначала пример программы Р на языке ПЛ/1 (точнее, исходный модуль Р на языке ПЛ/1), которая включает плюс или более предложений SQL. Язык ПЛ/1 здесь взят для определенности. Суммарный процесс остается, по существу, неизменным и для других языков. Прежде чем программа Р может быть скомпилирована компилятором ПЛ/1, она должна быть обработана прекомпилятором (рис. 2.2). Примечание. Если Р содержит также какие-либо предложения CICS (вида ЕХЕС, СICS...;), то она должна быть также обработана препроцессором СICS. Прекомпилятор DB2 и препроцессор CICS могут исполнятся при этом в любом порядке.
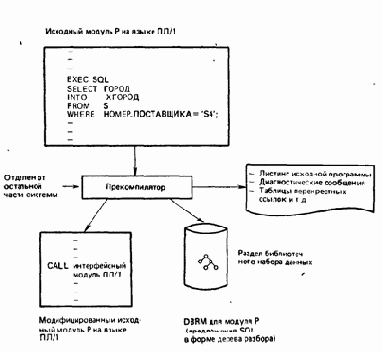
Рис. 2.2. Прекомпиляция
Как указывалось в предыдущем разделе, прекомпилятор DB2 удаляет все найденные им в Р предложения SQL и заменяет[7]
их предложениями CALL языка ПЛ/1. (Эти предложения CALL осуществляют обращения к интерфейсному модулю ПЛ/1—см. ниже.) Предложения SQL он использует при этом для построения модуля запросов к базе данных
(DBRM) программы Р, который хранится вне этой программы как раздел библиотечного набора данных. В DBRM содержится копия первоначальных предложений SQL вместе с внутренней формой этих предложений в виде дерева разбора. Прекомпилятор формирует также листинг исходной программы, содержащий первоначальный исходный текст программы, диагностические сообщения, таблицы перекрестных ссылок и т. д.
Далее, модифицированный исходный модуль на языке ПЛ/1 компилируется и редактируется обычным образом за исключением того, что интерфейсный модуль языка ПЛ/1, который предоставляется системой DB2, должен быть частью входной информации для редактора связей. Условимся называть результат этого шага «загрузочным модулем Р на языке ПЛ/1».
Теперь мы подошли к шагу генератора планов прикладных задач (рис. 2.3).
В действительности, этот компонент является оптимизирующим компилятором. Он преобразует запросы высокого уровня к базе данных (на самом деле, предложения SQL) в оптимизированную машинную программу. Входной информацией для генератора служит множество, состоящее из одного или более DBRM. Таких модулей запросов будет несколько, если первоначальная программа на ПЛ/1 состоит более чем из одной внешней процедуры, т. е. включает несколько исходных модулей. Результат работы генератора, т. е. скомпилированный им код, называется планом прикладной задачи и он хранится в системной базе данных, называемой каталогом[8]
( о каталоге более подробно пойдет речь в главе 7). Таким образом, главные функции генератора типов прикладных задач состоят в следующем.
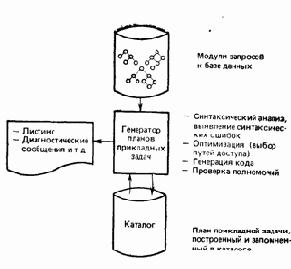
Рис. 2.3. Генератор планов прикладных задач
Выявление синтаксических ошибок
Генератор планов прикладных задач исследует предложения SQL во входных DBRM, осуществляет их синтаксический анализ и выдает сообщения обо всех синтаксических ошибках, которые он обнаружил. Такие проверки необходимы несмотря на то, что подобные проверки уже выполнялись прекомпилятором, поскольку прекомпилятор отделен от остальной части системы DB2. Его исполнение возможно, даже если DB2 недоступна. Он может даже исполняться на другой машине, и его выходные данные автоматически не защищаются. Поэтому нельзя предполагать, что входные данные генератора представляют собой достоверные результаты работы прекомпилятора — пользователь мог построить недопустимый «DBRM» с помощью некоторого другого механизма.
Оптимизация
Важной составной частью генератора планов прикладных задач является оптимизатор.
Функция оптимизатора состоит в том, чтобы выбрать для каждого обрабатываемого им манипулятивного предложения SQL оптимальную стратегию реализации этого предложения. Напомним, что предложения манипулирования данными, например SELECT, специфицируют только то, что хочет получить пользователь, а не как добраться до этих данных. Путь доступа, позволяющий добраться к этим данным, будет выбираться оптимизатором. Таким образом, программы независимы от таких путей доступа (дальнейшее обсуждение этой важной проблемы см. в заключении этого раздела).
Рассмотрим в качестве примера предложение SELECT из исходного модуля Р на языке ПЛ/1, приведенного на рис. 2.2. Даже в этом очень простом случае имеется, по крайней мере, два способа выполнения требуемого поиска: 1) путем физически последовательного просмотра (хранимой версии) таблицы S до тех пор, пока не будет найдена запись для поставщика S4; 2) если имеется индекс по столбцу НОМЕР_ПОСТАВЩИКА этой таблицы, что, вероятно, будет иметь место по причинам, которые подробно обсуждаются в Приложениях А и В, то используя этот индекс и, таким образом, непосредственно приходя к записи S4. Оптимизатору предстоит выбрать, какую из этих двух стратегий принять. Обычно оптимизатор будет делать свой выбор на основе следующих соображений: на какие таблицы ссылается данное предложение SQL (их может быть более одной), насколько велики эти таблицы, какие имеются индексы, каковы селективные их возможности, каким образом данные физически группируются на диске, какова форма фразы WHERE в запросе и т. п. Генератор планов прикладных задач будет далее генерировать машинный код, который тесно связан с
выбранной оптимизатором стратегией, т. е. в большой степени зависит от нее. Если, например, оптимизатор принимает решение использовать индекс X, то в плане прикладной задачи будут иметься команды машинного языка, которые явно обращаются к индексу X.
Генерация кода
Это процесс фактического построения плана прикладной задачи.
Проверка полномочий
Генератор планов прикладных задач осуществляет также проверку полномочий. Иными словами, он проверяет, позволяется ли лицу, выполняющему генерацию (т. е. пользователю, вызывающему генератор — см. главу 14), производить требуемые в DBRM операции, которые должны быть включены в план прикладной задачи. Вопросы санкционирования доступа будут подробно рассматриваться в главе 9.
Мы подошли, наконец, к процессу исполнения. Поскольку первоначальная программа теперь в действительности разбита на две части (загрузочный модуль и план прикладной задачи), эти две чисти должны быть на стадии исполнения каким-либо образом снова собраны вместе. Рассмотрим, как она работает (см. рис. 2.4).
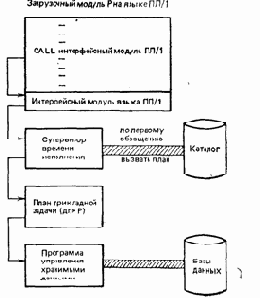
Рис. 2.4. Процесс исполнения
Сначала в основную память загрузится загрузочный модуль Р на языке ПЛ/1 и он обычным образом начиняет исполняться. В конце концов, он достигает первого обращения к интерфейсному модулю языка ПЛ/1. Этот модуль получает управление и в свою очередь передает управление супервизору стадии исполнения. Далее, супервизор стадии исполнения производит поиск плана прикладной задачи в системном каталоге, загружает его в основную память и передает ему управление. План прикладной задачи в свою очередь вызывает программу управления хранимыми данными, которая выполняет необходимые операции над фактически хранимыми данными и возвращает результаты в подходящем виде программе на языке ПЛ/1.
До сих пор в нашем обсуждении умалчивался один чрезвычайно важный момент, который мы теперь поясним. Прежде всего, как уже говорилось, DB2—это компилирующая система.
В отличии от нее большинство других систем управления базами данных и, без сомнения, все системы нереляционного типа, насколько известно автору, являются, по существу, интерпретирующими.
Далее, компиляция, несомненно, имеет преимущества с точки зрения производительности. Она почти всегда будет давать лучшие характеристики времени исполнения, чем интерпретация. Однако она страдает следующим важным недостатком: возможно, что решения, принятые в процессе компиляции «компилятором» (фактически генератором планов прикладных задач), более не имеют силы на стадии исполнения. Эту проблему иллюстрирует следующий простой пример.
1. Предположим, что программа Р компилируется в понедельник, и генератор планов прикладных задач принимает решение использовать в стратегии для Р индекс, например, индекс X. Тогда план прикладной задачи для Р будет включать, как говорилось ранее, явные обращения к X.
2. В четверг некоторый обладающий полномочиями пользователь издает предложение DROP INDEX X;
3. В пятницу некоторый пользователь пытается исполнить программу Р. Что при этом происходит?
При этом происходит следующее. Когда уничтожается индекс, DB2 исследует все планы прикладных задач в каталоге с тем, чтобы установить, какие из них зависят от этого индекса, если они вообще зависят от индексов. Каждый из таких планов, который он обнаружил, помечается как «недействительный». Когда супервизор стадии исполнения осуществляет выборку такого плана для исполнения, он обнаруживает маркер «недействительный» и поэтому вызывает генератор планов прикладных задач для продуцирования нового плана, т. е. для того, чтобы выбрать какую-либо иную стратегию доступа, а затем перекомпилировать первоначальные предложения SQL, которые были сохранены в каталоге, в соответствии с этой новой стратегией. Если перекомпиляция была успешной, старый план заменяется в каталоге новым, и супервизор стадии исполнения продолжает работу уже с новым планом. Таким образом, весь процесс перегенерации (или «автоматического связывания», как его называют) является «прозрачным для пользователя». Единственный эффект, который может наблюдаться,— это незначительная задержка исполнения первого предложения SQL в программе.
Заметим, что та перекомпиляция, о которой здесь говорилось, это перекомпиляция SQL, а не ПЛ/1. Перекомпилируется не программа на языке ПЛ/1, которая стала недействительной вследствие уничтожения индекса, а лишь план прикладной задачи.
Теперь можно видеть, каким образом становится возможной независимость программ от физических путей доступа, или более определенно, каким образом возможно создавать и уничтожать такие пути доступа без необходимости в то же время изменять программы. Как указывалось ранее, предложения манипулирования данными языка SQL, например SELECT и UPDATE, никогда не включают какого-либо явного упоминания о таких путях доступа. Вместо этого в них просто указывается, в каких данных заинтересован пользователь. Выбор пути, позволяющего добраться до этих данных, а также замена его другим путем, если старый путь более не существует,— это обязанности системы, а в действительности—генератора планов прикладных задач. Будем говорить, что система типа DB2 обеспечивает высокую степень физической независимости данных: пользователь и пользовательские программы не зависят от физической структуры хранимой базы данных. Достоинство такой системы—весьма значительное достоинство—состоит в том, что можно делать изменения в физической базе данных, например по соображениям производительности, не имея необходимости делать какие-либо соответствующие изменения в прикладных программах. В системе, не обладающей такой независимостью, прикладные программисты вынуждены уделять довольно значительную часть времени—доля 50 процентов является весьма типичной—для внесения в существующие программы изменений, которые становятся необходимыми просто вследствие изменений в физической базе данных. Напротив, в системе типа DB2 эти программисты могут сосредоточиться исключительно на производстве новых прикладных задач.
Ещё один момент, касающийся предыдущего вопроса. Наш пример был связан с уничтоженным индексом и это, вероятно, наиболее частый случай на практике. Однако аналогичная последовательность событий имеет место при удалении любого объекта, а не только индекса, а также когда отменяются полномочия пользователя (см. главу 9). Поэтому, например, уничтожение какой-либо таблицы приведет к тому, что все планы, которые обращаются к этой таблице, будут помечены как недействительные. Конечно, автоматическая перегенерация будет работать лишь в том случае, если ко времени, когда ее следует выполнять, была создана другая таблица с тем же именем, что и у старой (и, вероятно, не тогда, когда имеются значительные различия между старой и новой таблицами).
В заключение данной главы отметим, что SQL всегда компилируется в DB2 и никогда не интерпретируется, даже если предложения в запросе вводятся через интерактивный интерфейс DB2I или через QMF. Иными словами, если ввести, например, предложение SELECT с терминала, то этот оператор будет компилироваться, и для него сгенерируется план прикладной задачи. Далее этот план будет исполняться. Наконец, после того как исполнение будет завершено, этот план будет удален. Практический опыт показал, что даже в интерактивном случае при компиляции почти всегда достигается лучшая общая производительность, чем при интерпретации. Достоинство компиляции состоит в том, что процесс физического доступа к требуемым данным осуществляется скомпилированной программой, т. е. программой, которая хорошо приспособлена для конкретного запроса, а не универсальной интерпретирующей программой. Недостаток состоит, конечно, в том что имеются затраты, связанные с компиляцией, т. е. с подготовкой этой хорошо приспособленной программы. Но указанное преимущество почти всегда перевешивает этот недостаток, причем иногда поразительным образом. Только в случае чрезвычайно простого запроса затраты на выполнение компиляции могут быть больше, чем потенциальная экономия. В качестве примера мог бы служить следующий простой запрос: «Осуществить выборку записи поставщика для поставщика S1». Здесь запрашивается единственная конкретная запись при заданном значении для поля, которое уникально идентифицирует эту запись. Обратим внимание, что такой запрос в действительности совсем не использует средств уровня множеств языка SQL.
