Выбор DTD
При переходе к использованию технологии SGML встает вопрос выбора DTD. Обычно без проб и ошибок обойтись не удается. Можно пробовать "стандартные" DTD, широко используемые в индустрии, например, или . Можно создавать свои DTD, ориентированные на типичные документы, встречающиеся в повседневной работе. Переход между DTD ввиду использования SGML-процессоров обычно безболезнен, поэтому тут возможно длительное экспериментирование.
Выделение Разметки шрифтом и цветом
При использовании терминала (или программы эмуляции терминала) и версии Emacs, поддерживающей отображение текста различным шрифтом или цветом, PSGML может использовать эти возможности для облегчения восприятия разных видов разметки. Настройки PSGML по умолчанию отображают комментарии SGML курсивом; ссылки на объект - полужирным курсивом; тэги, встроенные инструкции, SGML и DOCTYPE объявления, а также короткие ссылки - полужирным шрифтом.
Если используемая версия Emacs может работать с различными шрифтами, то скорее всего это версия редактора под UNIX с XWINDOWS терминалом. Другие версии обычно вместо различных шрифтов используют выделение цветом. Так поступает, например, EMX версия GNU Emacs 19.29.2, отображая комментарии красным, ссылки на объект желтым, и тэги и прочую разметку белым цветом на общем сером фоне.
Если была использована команда sgml-next-trouble-spot, а выделение шрифтом или цветом отсутствует, то можно задать Emacs и PSGML отображать разметку выбранным способом, добавив несколько строк к .emacs-файл. Создание этих строк можно разбить на следующие четыре этапа:
Создать "ярлыки", чтобы обозначить категории разметки. Назначить атрибуты для ярлыков. Присвоить категориям разметки ярлыки. Присвоить переменной sgml-set-face ненолевое значение, чтобы PSGML "обратил внимание" на параметры настройки ярлыков.
Ниже приводится код .emacs, демонстрирующий назначение разметки цветом для комментариев, тэгов, и ссылки на объект.
| ;;;;; Assign colors to markup. ;;;;; ; Create faces to assign to markup categories. (make-face sgml-comment-face) (make-face sgml-start-tag-face) (make-face sgml-end-tag-face) (make-face sgml-entity-face)
; Assign attributes to faces. Background of white assumed. (set-face-foreground sgml-comment-face "White") ; Comments: white on (set-face-background sgml-comment-face "Gray") ; gray. (set-face-background sgml-start-tag-face "Gray") ; Tags: black (default) (set-face-background sgml-end-tag-face "Gray") ; on gray. (set-face-foreground sgml-entity-face "White") ; Entity references: (set-face-background sgml-entity-face "Black") ; white on black. ; Assign faces to markup categories. (setq sgml-markup-faces '((comment . sgml-comment-face) (start-tag . sgml-start-tag-face) (end-tag . sgml-end-tag-face) (entity . sgml-entity-face))) ; Tell PSGML to pay attention to face settings. (setq sgml-set-face t) |
Выход из VI
Теперь, когда вы знаете как запустить vi, необходимо узнать как завершить сеанс работы с редактором. Редактор vi имеет два рабочих режима и для завершения сеанса работы необходимо перейти в командный режим. Нажмите клавишу "Escape" или "Esc" (если у вас нет такой клавиши попробуйте "^[" или "control-[") для переключения в командный режим. Если вы находясь в командном режиме нажмете клавишу "Escape" - ничего страшного. Возможно прозвучит сигнал, но редактор по-прежнему будет в командном режиме.
Команда для выхода из vi - ":q". В командном режиме наберите двоеточие и "q" и нажмите клавишу "Enter". Если вы вносили изменения в файл - редактор предупредит об этом и не позволит завершить сеанс подобным образом. Выход из редактора без сохранения изменений - ":q!".
Конечно, работая в редакторе, вы хотите сохранять результаты работы. Команда для сохранения изменений - ":w". Можно сохранить изменения и завершить сеанс работы одновременно - ":wq". Для изменения имени файла выполните - ":w filename". Например для сохранения файла с новым именем filename2 выполните : ":w filename2".
Другая возможность завершения сеанса работы с редактором - выполнение команды ":ZZ". В командном режиме выполните ":ZZ" (эквивалент команды ":wq"). Если были сделаны изменения - они будут сохранены. Это самый простой вариант.
Выравнивание текста элемента
Для выравнивания текста, как было показано выше, используется комбинация клавиш M-q (команда fill-paragraph). Эта команда выравнивает длину строк в соответствии с установленной правой границей. В тексте SGML целесообразно использовать другую команду: sgml-fill-element, вызываемую нажатием C-c C-q или выбором пункта Fill Element меню Modify.
Команда sgml-fill-element, в отличие от команды fill-paragraph, выравнивает текст только внутри одного элемента, сохраняя при этом общую структуру. Рассмотрим это на следующем примере:
| <sect1> <title>The Chase--Third Day</title> <para>But aye, old mast, we both grow old together; sound in our hulls, though, are we not, my ship? Aye, minus a leg, that's all. By heaven this dead wood has the better of my live flesh every way.</para> <para>I can't compare with it; and I've known some ships made of dead trees outlast the lives of men made of the most vital stuff of vital fathers. <emphasis>What s that he said?</emphasis> he should still go bef\ ore me, my pilot; and yet to be seen again? But where? Will I have eyes at the bottom of the sea, supposing I descend those endless stairs and all night I've been sailing from him, wherever he did sink to.</para> </sect1> |
После применения команды sgml-fill-element текст будет выглядеть следующим образом:
| <sect1> <title>The Chase--Third Day</title> <para>But aye, old mast, we both grow old together; sound in our hulls, though, are we not, my ship? Aye, minus a leg, that's all. By heaven this dead wood has the better of my live flesh every way.</para> <para>I can't compare with it; and I've known some ships made of dead trees outlast the lives of men made of the most vital stuff of vital fathers. <emphasis>What s that he said?</emphasis> he should still go before me, my pilot; and yet to be seen again? But where? Will I have eyes at the bottom of the sea, supposing I descend those endless stairs and all night I've been sailing from him, wherever he did sink to.</para> </sect1> |
Изменилась только та часть текста, которая следовала после тэга <emphаsis>, общая структура текста, включая разбивку на параграфы, осталась нетронутой. В случае применения команды fill-paragraph данный текст представлял бы собою единый блок, без разбивки на параграфы.
Выражение отношения
Выражение отношение может быть двух типов:
< Выражение> < Принадлежность> < Выражение>
< Выражение> < Лог. Операция> < Выражение>
Принадлежность:
~ - Содержится;
!~ - Не содержится.
Лог. Операция: < , < =, ==, !=, > =, > .
Например:
$1 ~ /[Oo]lga/ - Указывает на строки, первое поле которых содержит Olga или olga.
$1 > = "s" - Указывает на строки, начинающиеся с символа s или следующих за ним по порядку: t, u, v...
Вырезание и копирование
Наиболее часто используемая команда для вырезания текста "d". Эта команда удаляет текст из файла. Использует аргумент count. Команда "dd" удаляет текущую строку. Рассмотрим несколько примеров :
d^
удаляет символы от текущей позиции курсора до начала строки. d$
удаляет символы от текущей позиции курсора до конца строки. dw
удаляет символы от текущей позиции курсора до конца слова. 3dd
удаляет три строки от текущей позиции курсора вниз.
Действие команды "y" (копирование) подобно действию команды "d", но она не удаляет текст, а только копирует его в буфер.
Вырезание и вставка/удаление текста
" Назначение буфера. Используется с буквой или цифрой. D Удалить от текущей позиции курсора до конца строки. P Вставить текст из буфера в позицию перед курсором. Если не определен буфер командой ", используется буфер общего назначения. X Удалить символ перед текущей позицией курсора. Y Копировать текущую строку в буфер. Если не определен буфер, используется буфер общего назначения. d Удалить. "dd" - удалить текущую строку. Аргумент count определяет количество удаляемых строк. Если не определен буфер командой ", используется буфер общего назначения. p Вставляет текст после текущей позиции курсора. Если не определен буфер командой ", используется буфер общего назначения. x Удаляет символ в позиции курсора. Аргумент count определяет количество удаляемых символов. Символы будут удалены после текущей позиции курсора. y Копировать. "yy" - копировать текущую строку. Аргумент count определяет количество копируемых строк. Если не определен буфер командой ", используется буфер общего назначения.
Вывод /Печать/
Формат оператора печати:
PRINT [< список выражений> ] [ > < выражение1> ]
Если в списке выражения находятся через запятую, то значения этих выражений выводятся на output (печатаются) через символ-разделитель OFS (по умолчанию пробел). Если же выражения стоят через пробел, то на печати происходит их конкатенация.
Значение < выражения1> рассматривается как имя файла. Само его присутствие означает печать в файл. Если вместо ``> '' стоит ``> > '', то это означает добавление к уже существующему файлу. Можно использовать в одной программе максимально до 10 output файлов.
Оператор форматированной печати:
PRINTF формат [,список выражений] [ > выражение1]
формат: символьная строка в двойных кавычках. Идентичен формату, используемому в функции printf в языке ``С''. Формат может содержать:
обычные символы, они копируются на output.
escпоследовательности, представляющие неграфические символы, например, "\n" - новая строка.
спецификации для вывода аргументов, они следуют после символа ``%''. Число спецификаций должно быть равно числу аргументов. (Если оно меньше числа аргументов, то лишние аргументы игнорируются, если же больше - то это ошибка)
Вывод результатов проверки
После того, как команда nsgml отредактирована, и нажата клавиша Enter, PSGML разбивает экран пополам, чтобы создать новое окно для буфера под названием *sgml validation*. Вид команды, выполняющей проверку, отобразится в этом окне.
Если в окне минибуфера появится слово "done", то это означает, что программа проверки не нашла ошибок в тексте документа.
Если же ошибки все-таки обнаружены, то программа проверки перечислит их в окне буфера *sgml validation*. PSGML отсортирует сообщения и позволит быстро найти ошибки, обнаруженные в тексте. Рассмотрим пример. Добавим две ошибки к совершенно правильному тексту и посмотрим как будут выглядеть сообщения об ошибках.
Ниже приводится текст документа, который полность соответствует DocBook DTD, за исключением двух пунктов. Во-первых, в элемент emphasis помещен беспризорный открывающий тэг <sect1>, а во-вторых, в элемент <para> вставлен недопустимый атрибут hair со значением red:
| <!DOCTYPE chapter PUBLIC "-//Davenport//DTD DocBook V2.4.1//EN"> <chapter> <title>Gone Whalin </title> <sect1> <title>The Carpet-Bag</title> <para>I stuffed a <emphasis>shirt<sect1></emphasis> or two into my old carpet-bag, <emphasis>tucked</emphasis> it under my arm, and <emphasis>started</emphasis> for Cape Horn and the Pacific.</para> <para hair=red>Quitting the good city of old Manhatto, I duly arrive in New Bedford.</para> <para>It was on a Saturday night in December.</para> |
Нажмите C-c C-v, чтобы отправить данный образец на проверку. Сообщения об ошибках будут выглядеть следующим образом:
| nsgmls:whalin.sgm:6:43:E: document type does not allow element "SECT1" here nsgmls:whalin.sgm:6:54:E: "SECT1" not finished but containing element ended nsgmls:whalin.sgm:6:54:E: end tag for "SECT1" omitted, but OMITTAG NO was specified nsgmls:whalin.sgm:6:37: start tag was here nsgmls:whalin.sgm:9:15:E: there is no attribute "HAIR" nsgmls:whalin.sgm:11:57:E: end tag for "SECT1" omitted, but OMITTAG NO was specified nsgmls:whalin.sgm:4:1: start tag was here nsgmls:whalin.sgm:11:57:E: end tag for "CHAPTER" omitted, but OMITTAG NO was specified nsgmls:whalin.sgm:2:0: start tag was here |
Данные сообщения об ошибках дают два полезных урока, связанных с программированием вообще:
Эффект ряби, когда одна ошибка тянет за собой целый шлейф сообщений об ошибках, может вызвать у неискушенных пользователей панику. Сохраняйте хладнокровие. Ведь в данный образец внесено только две ошибки. Возможно в следующий раз, когда в окне сообщений появится сообщение о восьми ошибках, на самом деле они будут вызваны только двумя ошибками. Emacs имеет специальную команду и быструю клавишу, которая осуществляет переход в ту строку текста, которая привела к сообщению об ошибке.
next-error (комбинация C-x ') - команда Emacs, осуществляющая переход в строку, где была обнаружена ошибка. Эта команда не является специфической командой PSGML. Она используется программистами для обнаружения строк в их исходном тексте программ, в которых компилятор нашел ошибки. По команде next-error курсор переходит в окно документа и перемещается в строку, содержащую ошибку. При этом в окне буфера сообщений об ошибках, *sgml validation*, соответствующее сообщение становится первым в списке (см. рис. Поиск ошибок в тексте с помощью команды .).
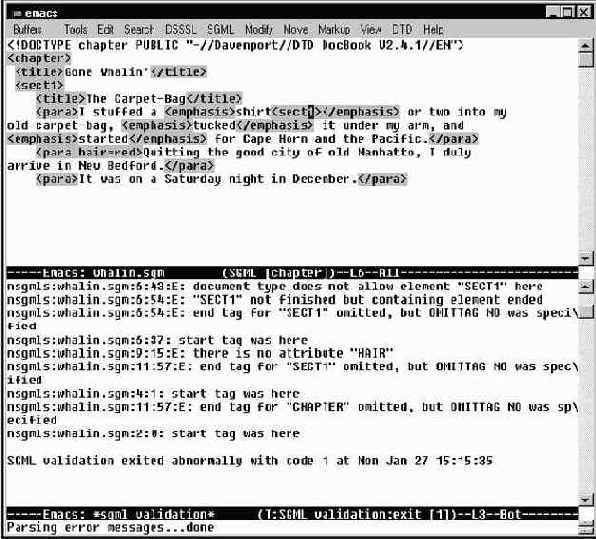
Поиск ошибок в тексте с помощью команды next-error.
Посторонний тэг sect1 стал причиной пяти сообщений об ошибках, а атрибут hair - только одной. Сообщение без буквенного кода кода после второго номера не является самостоятельным сообщением об ошибке, а несет в себе дополнительную информацию для предыдущей ошибки. Последовательно нажимая C-x ' можно отследить все "множественные" ошибки.
Если ошибок больше нет, и при этом нажать C-x ', то в окне минибуфера появится сообщение:
| No_more_errors |
Несмотря на небольшой размер, Ted
Несмотря на небольшой размер, Ted достаточно производительное приложение, удобное в использовании и стабильное ( я тестировал версии 2.5 и 2.8 ). В версии 2.5 была обнаружена ошибка - удаление пустых строк клавишей del влекло за собой завершение работы приложения, но в версии 2.8 ошибка была устранена.
Хотелось бы чтобы в приложение были добавлены следующие возможности : автосохранение, выпавнивание одновременно по левой и правой границе, обтекание изображения текстом.
Также было бы неплохо конвертировать Ted в GTK и QT (GTed и KTed).
Но даже в настоящее время Ted является прекрасным приложением, с помощью которого можно решать реальные задачи. Эта заметка, как и предыдущие написанные мной, созданы с помощью Ted и ни один издатель не испытывал проблем с преобразованием этих файлов. Это говорит о многом.
Warning
Что представляет собой конфигурирование сообщений при закрытии файла или выходе из редактора. Здесь имеется всего два переключателя. Первый отвечает за выдачу предупреждения о несохраненности изменений в закрываемом файле, второй же - разрешает или запрещает сообщение о изменении установок по умолчанию при закрытии программы. На мой взгляд, оба - далеко не лишние, и не худо бы включить их по умолчанию.
Предпоследний пункт нашей программы -
Whatrus
whatrus v.3.11.
Руководство пользователя.
Назначение.
Программа whatrus служит для определения используемой в файле кодировки: альтернативной (кодовая страница 866, для DOS), koi8 (для UNIX), Macintosh и Windows (кодовая страница 1251).
Описание.
Использование:
whatrus [-s] <file_name>
Флаг '-s' используется для подавления вывода на экран любых сообщений.
Операционная система windows запускает whatrus в отдельном окне, которое должно закрываться после окончания программы. Чтобы окно не закрывалось, и пользователь мог увидеть результат работы, whatrus после определения кодировки ждет нажатия любой клавиши. Если этого не требуется, используйте флаг '-s'.
Пример использования.
Пример для windows. E:\EX>whatrus \\server\d\files\readme.txt WIN detected.
Коды возврата.
255: произошла ошибка 0: кодировка не распознана определена кодировка: 11: альтернативная (кодовая страница 866, для DOS) 12: КОИ-8 (для UNIX) 13: Windows (кодовая страница 1251) 14: Macintosh
whatrus.html
Документ создан Паращенко Олегом
Последние изменения - 15 ноября 1998 года
Whatrus-e
whatrus v.3.11 manual
Description.
Whatrus is intended for recognizing encoding in file: alternative (for DOS, codepage 866), KOI-8 (for UNIX), Macintosh and Windows (codepage 1251).
Synopsys.
whatrus [-s] <file_name>
Flag '-s' is used to avoid messages.
Windows operating system runs whatrus in a separate window which should be closed after program finished. To keep window and to let user to see result whatrus after recognition waits for key pressed. To avoid this use flag '-s'.
Example.
Example for windows. E:\EX>whatrus \\server\d\files\readme.txt WIN detected.
Return codes.
255: error occured 0: encoding not recognized recognized encoding: 11: alternative (for DOS, codepage 866) 12: KOI-8 (for UNIX) 13: Windows (codepage 1251) 14: Macintosh
whatrus-e.html
Document created by Oleg A. Paraschenko
Last changes - 15 November 1998
Windows
Понимается под этим, как нетрудно догадаться, управление окнами, правда, довольно ограниченное. Во-первых, можно раделить окно с текущим документом на две независимо скроллируемые части (Split Window, Ctrl+2). Только по горизонтали, но зато сколько угодно раз: исходное окно делится ровно пополам, затем каждая половина - еще пополам, и так далее, насколько хватит разрешения экрана.
Для снятия разделения предназначен пункт Close Pane (Ctrl+1). При этом закрывается та часть окна, в которой находится курсор.
Наконец, в пункте Windows солдержится список открытых в текущем сеансе документов. Каждый из них открывается или создается (через пункты меню File - Open или File - New, соответственно) в своем окне с полным набором его атрибутов (управляющими элементами, меню, строкой состояния и так далее). Однако все они принадлежат текущему сеансу, и, скажем, изменение настроек сказывается на них всех. А переключение между окнами, кроме принятого в данном оконном менеджере, можно осуществить и через их список в пункте меню Windows.
В заключение раздела - несколько слов о
WodrPerfect 2000 для MS Windows
Не рекомендуется -
WodrPerfect 2000 для MS Windows имеет ограниченную поддержку SGML и DocBook 3.00. WordPerfect для Линукс не имеет поддержки SGML.
x
[] [] [ъЮутКтЦИьы] [рруЮЕ] [АшутЦНИьы] []
XML-инициативы набирают силу
Популярность расширяемого языка разметки Extensible Markup Language (XML) неуклонно растет, свидетельством чему разработка ведущими производителями ПО, ориентированного на Web (в их числе компании Microsoft, Netscape и Oracle), связанных с этим языком стратегических инициатив.
Хотя точные спецификации XML пока не утверждены, он вызывает большой интерес, поскольку позволяет разработчикам готовить настраиваемые наборы дескрипторов для создания в Web межплатформенных приложений, которые не зависят от данных. Кроме того, их можно сделать более структурированными, чем позволяет популярный в настоящее время "чистый" HTML.
Просветительская кампания корпорации Microsoft, связанная с XML, откроется выступлением Билла Гейтса на конференции Seybold San Francisco '97, которая будет проходить с 29 сентября по 3 октября.
Кроме того, Microsoft намерена анонсировать поддержку XML в инструментальных средствах, ориентированных на Web, таких как FrontPage и Visual Interdev.
Импульсом к началу активных действий послужила передача компаниями Microsoft, ArborText и Inso табличного XML-языка стилей, Extensible Style Language (ESL), на рассмотрение в консорциум W3C. Язык ESL расширяет так называемый механизм вложенных таблиц стилей (Cascading Style Sheets); в частности, он имеет такие возможности, как переупорядочивание XML-данных по мере их отображения.
"В наших планах, касающихся Internet, языку XML отводится стратегическая роль", - подчеркнул Том Джонстон, менеджер по маркетингу компании Microsoft.
Компания Netscape Communications, еще один сторонник XML, в середине сентября выпустила реализующий дерево гиперссылок апплет Java, который, как утверждает ведущий специалист компании Раманатан Джуха, позволяет просматривать информационное наполнение, описываемое при помощи Resource Definition Framework (RDF).
По его словам, RDF - это модель данных, предложенная консорциумом W3C, которая представлена в синтаксисе XML. Она является производной Meta Content Framework компании Netscape и предоставляет для апплетов браузера такие данные, как подробные карты узлов и описание каналов распространения, а также информацию, необходимую для реализации ряда возможностей, например осуществления родительского контроля и поддержки цифровых подписей. В пользу RDF уже высказались такие провайдеры информационного наполнения, как AltaVista, ABCNews.com, Knight Ridder, Time и Yahoo.
По некоторым данным, Netscape также планирует вскоре выпустить синтаксический анализатор для XML.
Джон Тайгу, старший системный программист DataChannel, отметил, что Oracle, Sybase, Microsoft и DataChannel уже давно работают над созданием языка разметки баз данных, опирающегося на XML. Этот язык мог бы радикально упростить использование баз данных в Web.
Кроме того, DataChannel создает Xapi-J, спецификацию для представления данных, извлеченных лексическими анализаторами XML, в программах на Java и JavaScript. По словам Тайгу, Xapi-J поддерживает несколько синтаксических анализаторов, в том числе XML Parser компании Microsoft, а также аналогичный продукт Netscape.
"Язык XML - это пока нечто эфемерное. За исключением DataChannel никто не может предложить реального инструментария. Но пользователи ждут его с нетерпением, - подчеркнул Дж. Морджентал, аналитик по вопросам Java в исследовательской компании NC.Focus. - Благодаря протоколу HTTP у нас в руках оказался фантастический механизм распространения. Теперь XML обеспечивает вам возможность предоставить структуру на основе данных".
XML — это семейство технологий

XML — это способ записи структурированных данных

XML — это текст, но он не предназначен для чтения

XML - модульная технология

XML немного похож на HTML

Также как и в HTML, в XML используются тэги (слова, заключенные в '<' и '>') и атрибуты (вида имя="значение"). Но если в HTML фиксируется смысловое значение каждого тэга и атрибута и часто то, как текст между ними будет выглядеть в браузере, в XML тэги используются только для логической разметки данных, и их интерпретация оставляется на усмотрение обрабатывающей программы. Другими словами, если вы встречаете "<p>" в XML-файле, то не стоит думать, что это параграф. В зависимости от контекста, это может быть цена (price), параметр (parameter), человек (person)... (вообще, кто сказал, что это должно быть слово, начинающееся с "p"?)
XML нов, но не совсем

XML — основа для RDF и Семантической Сети

XML: свобода, ограниченная только фантазией
Неважно, какую платформу для своих веб-приложений вы выбираете— Sun, Linux или Microsoft, в любом случае ваши веб-сервисы будут общаться на XML
Технология XML продолжает свое наступление на системы хранения, выборки и передачи данных. На сегодня существует несколько хороших парсеров — в том числе для Java (от IMB, Apache и Sun).
| Термины |
| XML (eXtensible Markup Language) — расширяемый язык разметки. Язык, в котором текст чередуется с элементами разметки, маркерами. |
DTD (Document Type Definition) — язык описания схемы данных, применяемый в первой версии XML.
XSDL (XML Schema Definition Language). Новый и рекомендуемый способ формального описания структуры XML-документа. Для описания структуры, естественно, применяется нормальный XML. Структура может быть применена дважды — как шаблон для порождения документа и как правило валидации, то есть проверки документа на предмет соответствия схеме.
DOM (Document Object Model). Спецификация высокого уровня, представляющая документы в виде структуры агрегированных объектов. Реализация DOM представляет собой парсер высокого уровня.
SAX (Simple API for XML). Базовый парсер XML. Набор функций низкого уровня, основанных на вызове пользовательского кода в момент возникновения событий — таких как «получено начало/конец элемента», «получен текст» и так далее.
Microsoft, как ни странно, тоже не стала изобретать «полностью свой XML», а в соответствии с рекомендациями предлагает Parser & SDK. Ввиду возможности использования готового и бесплатного кода, применение XML, с точки зрения разработчика, является привлекательным способом хранения и доступа к данным.
XML умышленно многословен

XML в 10 тезисах
XML, XLink, Namespace, DTD, Schema, CSS, XHTML ... Если вы впервые столкнулись с XML, трудно даже понять, с чего начать. Этот короткий обзор представляет собой попытку охватить основные идеи XML, чтобы новичок мог увидеть концепцию в целом, не путаясь в деталях. Если же вы кому-то представляете XML, почему бы не начать с этих 10 тезисов?
XML ведет HTML к XHTML

Xsltproc
Процессор xsltproc включен в состав большинства дистрибутивов, синтаксис вызова похож на вызов процессора saxon:
[danguer@perseo xslt]$ xsltproc hello.xsl hello.xml > hello.html
Я знаю о существовании и других процессоров, таких как sablotron, но я ими не пользовался, а потому не могу рекомендовать их вам ;-).
YUI 1.0 (бета-версия)
Разработанный Инженерно-Технической Компанией в Ижевске текстовый редактор YUI распространяется в исполняемом виде как freeware и находится в стадии бета-тестирования. Заявлено, что бета-версии редактора имеются для платформ MS-DOS, BSD, Solaris, INTERACTIVE и Linux. Интерфейс реализован в стиле Turbo Vision, поэтому YUI внешне очень напоминает Borland С++ З.х. Однако назвать этот продукт редактором для разработчиков нельзя: в нем отсутствует какая-либо поддержка процесса программирования, да и базовые средства форматирования представлены не в полной мере. Продукт достаточно сырой и, по моему мнению, пока может представлять чисто академический интерес. Поэтому маловероятно, что YUI в ближайшее время привлечет внимание разработчиков и квалифицированных пользователей.
z
[] [] [ъЮутКтЦИьы] [рруЮЕ] [АшутЦНИьы] []
За и против
За
DocBook -- официальный стандат W3C Доступ к тексту из программ (в том числе -- определяемых пользователем) Богатая и выразительная разметка текста
Против
Медленная обработка Формат DocBook очень "многословен". Если не использовать специальный редактор, то объем вводимого вручную текста очень велик.
За и против формата POD
За
Простота Быстрота создания окончательной версии из исходного текста
Против
Отсутствие таблиц В стандартной поставке отсутствует программа для генерации указателей и оглавления.
Зачем нужен этот документ?
Этот документ предназначен для тех пользователей Linux, которые хотят узнать о Emacs и научиться работать с ним.
Этот документ не является специфичным только для . Его можно использовать для работы с Emacs из других дистрибутивов Linux, в других вариантах операционной системы Unix, а также с Emacs для Microsoft Windows.
Этот документ предназначен для тех пользователей Linux, которые хотят узнать о Emacs и научиться работать с ним.
Этот документ не является специфичным только для . Его можно использовать для работы с Emacs из других дистрибутивов Linux, в других вариантах операционной системы Unix, а также с Emacs для Microsoft Windows.
Задание структуры документа
В зависимости от documentclass LaTeX знает о трех или четырех уровнях заголовков. В класс article три уровня разделов, в то время, как в классе book сожержит главу в качестве четвертого заголовка самого верхнего уровня.
\chapter{Название главы} % только в классах book и report
\section{Название раздела}
\subsection{Название подраздела}
\subsubsection{Заголовок подраздела подраздела }
Обратите внимание, что как и в POD, который обсуждается в Части I, команды секционирования работают подобно разделителям. Они не группируют текст с помощью маркировки начала и окончания раздела, но простое их появление задает деление текста на группы. Как вы увидите в следующем месяце, в DocBook все иначе.
Задание структуры и разбиение на разделы
Как и в TeX'е, мы просто набираем текст, разделяя абзацы пустыми строками. В зависимости от используемых средств трансляции абзацы получаться с выключкой или даже выравненными по ширине.
Главные команды секционирования введены в разделе Тело документа. Команды @node групируют вводимый текст и разбивает его на куски, пригодные для чтения с экрана. Сопровождающие их TeX-подобные команды секционирования делают то же самое, но при печати. В частности, Texinfo предлагает следующие команды разделов: chapter, section, subsection и subsubsection.
Пожалуйста не забывайте, что -- для упрощения дальнейшего сопровождения -- за каждой командой @node должна следовать одна из команд секционирования при печати.
Заголовок
Заголовок -- необязательная часть файла Texinfo, но она появляется во всех докумнетах. В ней по меньшей мере содержится имя выходного файла для просмотра на экране и заголовок, который используется при выводе на печать.
Имя выходного файла задается командой @setfilename output-filename. Я советую добавлять к имени-выходного-файла расширение .info, поскольку файлы с расширением удобнее для работы -- просто представьте результат ls *.info! Вся строка справа от @setfilename является аргументом команды, так что никаких коментариев после имени выходного файла. Кошмар!
Заголовок устанавливается командой @settitle заголовок-документа. Как и раньше, весь текст до конца строки является аргументом команды. Заголовок (как он задан командой @settitle ) используется для печати колонтитулов. Он не имеет ничего общего с названием документа, которое ставиться на первой странице (если таковая имеется).
Простейший заголовок выглядит так:
@setfilename example.info
@settitle Пример Texinfo
Другие полезные в заголовках команды:
@afourpaper и @afourwide
По умолчанию в Texinfo размер бумаги полагается равным 8,5 дюймов на 11 дюймов. За пределами Северной Америки размеры бумаги принято указывать в соответствии с DIN -- Deutsche Industrie Norm -- Германским промышленным стандартом. Командыљ@afourpaper и @afourwide изменяют область вывода текста в соответсвии с размером бумаги DIN A4, при этом @afourwide делает область печати несколько шире, что, впрочем, не означает перехода к альбомной ориентации листа.
Совет: никогда не вредно проверить размер бумаги перед печатью "импортного" документа.
@setchapternewpage on | off | odd
on Каждая глава будет начинаться с новой страницы. Страница и колонтитулы форматируются для односторонней печати. Это настройки по умолчанию. off Новая глава не будет начинаться с новой страницы, вместо этого добавляется дополнительное пустое пространство. Используются колонтитулы для односторонней печати. odd Начинает главы на нечетных страницах. Колонтитулы форматируются для двухсторонней печати ("recto verso").
Имейте в виду, что команда @setchapternewpage even не определена.
@paragraphindent asis | number
asis
Не менять имеющийся отступ. number
Использовать абзацный отступ в number пробелов. number может быть и нулем.
Совет: Все разработки GNU поставляются с документацией в формате Texinfo. Если вы хотите распечатать ее сами, то сначала лучше изменить заголовок файлов Texinfo в соответствии с применяемым размером бумаги (Letter, A4) и используемым оборудованием (принтер для двусторонней печати и т.д.).
Загрузка пакета fontenc
Пакет fontenc предназначен для указания внутренней кодировки шрифта TeX, которую надлежит использовать при компиляции документа, и загружается строкой вида
\usepackage[(список кодировок)]{fontenc}
«Переходником» к загрузке данного пакета в LyX служит параметр \font_encoding, который можно задать либо вручную в конфигурационном файле, либо через поле «TeX encoding», расположенное в диалоге «Preferences…» (вкладка «Outputs», на ней вкладка «Другие»). Любопытно, что создатели LyX не только вынесли сей параметр в глобальные настройки программы (полагая, очевидно, что у пользователя не возникнет потребности в его частом изменении), но и «спрятали» его на вкладке, не имеющей отношения к установкам языкового окружения. По умолчанию предлагается использовать кодировку T1, которая ныне является стандартом для языков Западной Европы. Можно (но не рекомендуется) установить \font_encoding в «default» – в этом случае пакет fontenc не загрузится вообще, и LaTeX будет использовать устаревшую 7-битную кодировку OT1. Существования кириллических кодировок авторы не предусмотрели, однако использовать их не составит труда, поскольку сам LyX не интересуется значением \font_encoding, а только передает его пакету fontenc.
Возможно, у читателя возникнет недоумение: зачем понадобилось создавать специальные кодировки для TeX, когда изобилие существующих кодовых страниц и так служит источником неразберихи. Дело заключается в том, что система TeX по традиции предъявляет определенные требования к своим шрифтам. Например, в них должны быть латинские лигатуры и полный набор акцентов-модификаторов, причем всё это хозяйство обычно размещается в таблице символов в диапазоне 0–32 (на использование данной области в TeX не существует запрета, поскольку нет и потребности в управляющих кодах). Есть свои предпочтения по отношению к типографским символам: некоторые из них непременно должны присутствовать в таблице, другие же выносятся в специальные символьные шрифты. Освободившееся место используется для дополнительных букв, в результате чего, например, кодировка T1, хотя она и основана на западноевропейской кодовой странице iso-8859-1, фактически включает также и символы центральноевропейского набора.
С этими требованиями и должны сообразовываться кодировки TeX для кириллицы. Таковых существует несколько. Особенно хотелось бы предостеречь от использования кодировки LCY, основанной на cp866. Еще недавно эта кодировка была фактическим стандартом для постсоветского пространства. Однако ныне на смену ей пришла серия кодировок T2, существующая в трех ипостасях (T2A, T2B, T2C). Все три кодировки совместимы между собой и с cp1251, на которой основаны; различие же их заключается в средней области таблицы (128–191). В T2A здесь размещены символы славянских алфавитов из cp1251, сдобренные «азиатской кириллицей», в то время как в других двух кодировках «азиатская кириллица» царствует безраздельно. Существует также «идеологически чистая», но весьма громоздкая кодировка X2, которая включает все кириллические буквы из кодировок серии T2 (а также символы старой орфографии), но зато не содержит латинского алфавита.
Из сказанного вытекает, что наиболее целесообразным в большинстве случаев является использование кодировки T2A. Она и в самом деле по умолчанию загружается пакетом поддержки русского языка (о котором речь ниже) в том случае, если ни одна из кириллических кодировок не упомянута в опциях пакета fontenc. Так что исходное значение параметра \font_encoding, собственно говоря, можно оставить без изменений. Однако же явное указание кодировок является одним из признаков хорошего тона при работе с LaTeX, поэтому не будет ошибкой заменить T1 на T2A. Впрочем, правильнее всего будет передать пакету fontenc сразу два значения, разделив их запятой, например: \font_encoding "T1,T2A"
Такое решение следует настоятельно рекомендовать тем пользователям, которым приходится включать в свои документы фрагменты текста на западноевропейских языках. Абсолютно необходимым оно будет также в том случае, если для кириллицы используется кодировка, не содержащая латинского алфавита (как X2).
Загрузка пакета inputenc
Пакет inputenc служит для указания кодовой страницы исходного файла и загружается командой
\usepackage[(список кодировок)]{inputenc}
Нечего и говорить, сколь важен данный пакет для русскоязычных пользователей: именно он (в паре с fontenc) дает возможность одинаково успешно пропускать через компилятор LaTeX файлы, подготовленные в различных операционных системах и при различных установках кодовой страницы.
В отличие от внутренней кодировки TeX, кодировка исходного файла задается в LyX для каждого документа отдельно. Для этой цели нужно открыть вкладку «Язык» диалогового окна «Формат документа». На ней обнаруживаем раскрывающийся список «Language» (естественно, надо убедиться, что его значение выставлено правильно, иначе дальнейшее не имеет смысла). Ну а чуть ниже как раз и расположен другой список, под названием «Кодировка». В общем-то, на его содержание грех жаловаться (налицо все кодировки кириллицы), однако же нельзя не удивиться тому, что данный список жестко задан в ресурсах соответствующего диалога, и, соответственно, способа пополнить его не существует. Ведь со стороны авторов по меньшей мере наивно было бы предполагать, что они в состоянии предусмотреть все кодовые страницы, с которыми могут пожелать работать пользователи.
С другой стороны, понятно, почему названия кодировок нельзя было взять из системы. Дело в том, что опции пакета inputenc суть не что иное, как названия совершенно определенных файлов (они имеют расширение .def), которые должны подчиняться соглашению 8.3 ради сохранения совместимости с версиями TeX для других платформ. Поэтому длинные имена вроде «microsoft-cp1251.def» (и даже «iso-8859-5.def») были бы здесь неприемлемы. Однако же следовало хотя бы предоставить пользователю возможность ввести требуемое имя кодировки вручную.
Впрочем, вместо явного задания входной кодировки можно выбрать в списке опцию «auto» (а именно она выставлена там по умолчанию). Тогда LyX сам подберет кодировку, исходя из выбранного языка документа и руководствуясь при этом своей базой данных, которая хранится в файле languages в его программном каталоге. Только следует иметь в виду, что при использовании «автоматического» режима LyX загрузит соответствующие входные кодировки не только для основного языка документа, но и вообще для всех языков, встретившихся в нем. И, соответственно, входная кодировка будет динамически переключаться в разных местах на протяжении документа. Пользы от этого, впрочем, мало по уже упомянутой причине: нет возможности заодно менять и кодовую страницу экранного шрифта. Если же вы всё-таки хотите воспользоваться этой возможностью, то файл languages придется предварительно отредактировать, поскольку кодировки в нем по необъяснимой причине приведены под общепринятыми именами, а не под «псевдонимами», понятными LaTeX. В противном случае компилятор сможет нормально воспринимать чисто русские документы в koi8-r, но непременно споткнется на названиях латинских кодовых страниц серии iso-8859.
Наконец, в списке кодировок можно выбрать опцию «default». В этом случае пакет inputenc не загрузится вообще, и, соответственно, никакой перекодировки исходного файла при его компиляции осуществляться не будет. Данный номер пройдет безнаказанно только для русского (но не украинского!) текста в cp1251, поскольку именно на ней основана серия кодировок T2. Однако в любом случае пренебрежение необходимостью явно указывать входную кодировку следует считать признаком дурного тона.
Чтобы закончить разговор о о диалоге «Формат документа» и его вкладке «Язык», упомянем о том, что на ней имеется также группа опций «Quote style» (то есть «Стиль кавычек»). LyX, как и всякий уважающий себя текстовый процессор, умеет автоматически расставлять парные кавычки при наборе текста. Так вот, правила русской пунктуации требуют использовать двойные кавычки-«елочки», то есть кавычки французского стиля, именуемые в международной терминологии guillemots. Именно их и надлежит выбрать в раскрывающемся списке. Не смущайтесь даже в том случае, если вместо нужных символов увидите в нем вопросительные знаки (а если ваша основная кодировка – koi8, то ничего другого вы и не увидите, потому что типографские знаки препинания отсутствуют в ней как класс). Всё равно в тексте документа кавычки будут отображаться в виде двойных угловых скобок, как это и принято в исходниках LaTeX. Ну а в откомпилированном для печати файле они примут нормальный вид.
Загрузка пакета многоязыковой поддержки
Мне уже приходилось несколько раз упоминать о таком показателе, как язык документа. Настала пора рассказать о том, для чего он требуется LyX. Ведь не для проверки же орфографии: реализация этой последней в LyX не имеет никакого отношения к его взаимодействию с LaTeX. Однако правильная установка языка совершенно необходима хотя бы для правильного выбора внутренней кодировки: ведь, загрузив список кодировок в опциях пакета fontenc, мы еще не указали, к какой части документа надлежит применить каждую из них. Это как раз и должны сделать пакеты поддержки соответствующих языков. Но самое главное их назначение заключается в том, чтобы дать LaTeX указание использовать надлежащий алгоритм переноса. Кстати говоря, чтобы LaTeX мог осуществлять перенос слов на русском языке (равно как и на любом другом), его надлежит определенным образом сконфигурировать. Как это сделать – читайте в руководствах по LaTeX: LyX к данной процедуре не имеет никакого отношения, и, соответственно, ее нет возможности обсуждать в рамках посвященной ему статьи.
Но предположим, что этот этап благополучно минул. Тогда наша задача состоит в том, чтобы дать знать LyX, какой синтаксис использовать для загрузки поддержки требуемых языков. Делается это в диалоге «Preferences…» на вкладке «Lang Opts» (на ней вкладка второго уровня «Язык»). Наиболее важным здесь является поле под названием «Package». Еще сравнительно недавно поддержка русского языка в LaTeX обеспечивалась за счет загрузки различных версий пакета russian, не имевших ничего общего, кроме названия. Соответственно, в поле «Package» нам пришлось бы прописать что-то вроде \usepackage{russian}. Далее на вкладке имеются поля «Command start» и «Command end» для указания команд, которые должны отмечать начало и конец блока на том или ином языке. В данном случае они, скорее всего, приняли бы вид \begin{$$lang} и \end{$$lang}, где вместо $$lang программа подставляла бы значения «russian» и «english». Кроме того, возможно, пришлось бы пометить флажки «Auto begin» и «Auto finish», чтобы команды \begin{russian} и \end{russian} автоматически вставлялись в начало и конец документа LaTeX.
Ныне же в стандартную поставку LaTeX входит пакет babel, обеспечивающий поддержку всех европейских языков, включая и русский. Именно этот пакет по умолчанию используется LyX, и потому нам нет причин отвергать предлагаемые им установки: команда загрузки пакета – \usepackage{babel}, команда переключения языков – \selectlanguage{$$lang}. Следует отметить лишь одну тонкость: стандартный синтаксис загрузки пакета babel предусматривает включение списка требуемых языков в качестве опций. Например, так:
\usepackage[english,german,russian]{babel}
Однако babel в состоянии воспринимать и названия языков, указанных еще до его загрузки в числе глобальных параметров документа. LyX поступает с ними именно так, чем и объясняется предлагаемая по умолчанию загрузка пакета babel без всяких опций. В качестве основного babel использует тот язык, который был загружен последним, и LyX прекрасно об этом знает, так что в активизации опций «Auto begin» и «Auto end» нет необходимости.
В ходе работы над текстом показатель языка можно устанавливать и изменять через диалоговое окно «Стиль символов». Список доступных языков достаточно обширен и, кроме того, его можно дополнить, так как берется он всё из того же файла languages. Естественно, надо убедиться, что нужный вам язык действительно поддерживается пакетом babel. LyX выделяет на экране фрагменты текста на иностранном (то есть не совпадающем с основным для данного документа) языке, подчеркивая их синей линией. Данный режим можно и отключить, но лучше этого не делать: представьте-ка себе, что может получиться на печати, если вы по ошибке пометили русский текст как английский, да еще и забыли об этом. Обратное же обычно допустимо, так как большинство кириллических кодировок содержит и латинские буквы. Тем не менее, явное указание показателя языка (хотя бы для фрагментов длиной в несколько строчек) считается признаком хорошего тона. И последнее: для часто используемых языков имеет смысл назначить горячие клавиши, например:
\bind "F11" "language russian" \bind "F12" "language english"
Как и многие другие, эти команды могут быть помещены в конфигурационных файлах LyX, но наиболее подходящее для них место – пользовательский bind-файл. Ну а LyX в процессе генерации документа LaTeX обязательно проверит файл на предмет использованных языков и приведет их список в преамбуле.
LyX будет приятным сюрпризом для
LyX будет приятным сюрпризом для пользователей LaTeX и SGML, потому что он имеет те же основы. Пользователи, которым нужно очень высокое качество печати, оценят мощность LyX-LaTeX. Только пользователи, которым нужен полный контроль над точным окончательным результатом могут быть разочарованы.
Возможности языка DocBook XML велики.
Возможности языка DocBook XML велики. Например преобразование в другие форматы. Эта заметка представляет краткое вступление. Вопросы можно задать на странице отзывов для данной статьи. Дополнительная информация в ссылках [8] и [9]. Обратите внимание, что последний пункт в разделе "Ссылки" в формате DocBook!
Остались без обсуждения следующие возможности DocBook :
расширенное значение библиографической информации ; ссылки к другим разделам, примерам. Возможно это темы для следующих заметок.
Заключение (субъективное).
Несколько слов о том, что и в каком случае удобно использовать. Как универсальное средство могу рекомендовать phpMyLingvo. Почему? Работая в веб-браузере, вам не нужно задумываться о том какая именно операционная система стоит на том конце, откуда приходит html-код. Вы просто набираете адрес и начинаете веб-сёрфинг. Поэтому, если у вас гетерогенная сеть, то попробуйте именно phpMyLingvo. Кроме этого, веб-интерфейс имеет ещё одно неоспоримое преимущество -- вы можете работать в текстовом режиме (если у вас, конечно, есть соответствующий веб-браузер -- links, lynx и т.п.).
Если вы не привыкли работать с веб-браузерами, тогда в вашем распоряжении GtkDic/PtkDic или JaLingo. По функциональным возможностям первый обгоняет второго. Это неоспоримо. Но если вам хочется поработать с симпатишым Lingvo-подобным клиентом, то JaLingo подходит тут идеально. Правда, в его случае есть один недостаток -- нужно выкачать из Интернета пакет j2re. А это иногда кусается.
В любом случае решайте сами. Хотите почувствовать себя гедонистом -- возьмите JaLingo. Нет времени настраивать на каждой рабочей станции доступ к словарям -- вам по пути с phpMyLingvo. Хотите использовать печать, обратный поиск и возможность добавлять новые статьи -- работайте с GtkDic/PtkDic.
Умф. Вот, в принципе, и всё. Надеюсь, что-то вам приглянется. Если так, то не забудьте написать о своих впечатлениях автору (или авторам) программы. Удачи и красивых переводов!
Заключительные замечания.
txt2html - это более чем простой скрипт- менее 170 строк. Его можно легко расширить добавлением других html команд, например для создания фрэймов: показывающих оглавление рядом с текстом, а не вверху. Пожалуйста, присылайте мне Ваши коментарии или предложения на эту тему и я постараюсь сделать такие добавления в скрипт.
Замена текста
C Заменить от текущей позиции курсора до конца строки. R Заменить текст до нажатия клавиши "Escape". S Заменить всю строку. c Заменить. "cc" заменяет текущую строку. Аргумент count определяет количество строк. r Заменить символ в позиции курсора. Аргумент count определяет количество символов. s Заменить символ в позиции курсора и перейти в режим вставки текста. Аргумент count определяет количество символов. Символ ($) будет установлен на последнем символе для замены.
Запись и выполнение макросов.
Emacs может запоминать, а затем воспроизводить, последовательности комбинаций клавиш. Начало и конец записи осуществляется нажатием комбинации C-x, а далее должна следовать одна из круглых скобок. Комбинация C-x ( запускает команду start-kbd-macro - начало записи макроса, а заканчивает запись комбинация C-x ) (end-kbd-macro) - конец записи.
Комбинация C-x e запускает команду call-last-kbd-macro. Данная команда запускает последний записанный макрос.
Если нужно создать несколько макросов, то создаваемым макросам нужно присвоить имена. Для этого из командной строки в окне минибуфера (комбинация M-x) запускается команда name-last-kbd-macro. После нажатия ввода, редактор предложит ввести имя макроса. Допустим это имя - testmacro, тогда из командной строки (комбинация M-x) для запуска данного макроса нужно будет набрать testmacro и нажать ввод.
При выходе из Emacs большинство макросов (именованных и нет), определенных в данной сессии, будут утрачены. Как этого избежать будет показано в конце главы.
ЗАПОМИНАНИЕ / ВСПОМИНАНИЕ
^Y Вспомнить символы / yank M-y Вспомнить предыдущие символы ^@ Запомнить угол региона. (set-mark-command) ^W Удалить с запоминанием ^X x Запомнить в регистре M-d Удалить слово с запоминанием kill-word M-w Запомнить регион ^X x R Запомнить регион в регистре (copy-to-register) ^X g R Вспомнить регистре (insert-register)
Запуск:
$ cc -o example example.c $ export =%N <-- (не забыть поменять назад)
$ ./example
Содержание
Last change : 08-10-1999
Запуск и завершение работы в Emacs
Чтобы запустить редактор Emacs просто введите в командной строке
| emacs |
или, если это позволяет окружение, дважды щелкните на соответствующей иконке.
После запуска редактора (без имени файла в качестве параметра) на экране отображается информация о версии Emacs (см. рис. Окно редактора Emacs.).
Окно редактора Emacs.
Нижняя строка, в которой написано "For informafion about..." (см. рис. Окно редактора Emacs.), называется окном "минибуфера" (minibuffer). Пользователь вводит в этом окне соответствующие команды, а редактор выводит в это окно различные сообщения. Например, сообщение о необходимости сохранения файла при выходе.
Прямо над окном минибуфера располагается "строка состояния" (mode line), в которой присутствует справочная информация: имя редактируемого файла (или буфера), информация об установках редактора и т.п.
В строке состояния, помимо прочего, указывается какой "расширенный" (major) режим задействован для данного буфера. Расширенный режим позволяет установить набор специфических команд для какого-либо типа файлов. Напротив, "обычный" (minor) режим использует вполне определенный набор установок.
Возможность настройки расширенного режима позволяет настроить Emacs для работы с текстами программ различных языков программирования. На самом деле, данное руководство посвящено описанию расширенного режима - режима работы с PSGML.
При запуске Emacs в качестве параметра можно указать имя файла. Для этого в командной строке нужно набрать:
| emacs myfile.txt |
Если файл с таким именем не существует, редактор создаст его.
Что же такое буфер? Буфер - это область памяти, отводимая редактором под документ. При открытии редактор считывает содержимое файла и помещает его в память компьютера. Вот почему все несохраненные изменения будут утрачены при "зависании" компьютера или его выключении. Обычно буферы имеют те же имена, что и загруженные в них файлы.
Чтобы закончить сеанс работы с Emacs нажмите C-x C-c (Ctrl+c при нажатой Ctrl+x). Если версия Emacs имеет меню, то выберите пункт Exit Emacs в меню File. Если в файл не был изменен, то Emacs закроется и на экране появится командная строка (или просто закроется окно редактора). Если в файле имеются несохраненные изменения, Emacs выведет в окно минибуфера сообщение:
| Save file c:/pathname/filename.ext? (y, n, !, ., q, C-r or C-h) |
Т.е. Emacs задаст вопрос, что ему делать с этим файлом. Варианты ответов: n - выйти без сохранения, y - сохранить. Нажмите C-h, чтобы вызвать встроенную подсказку.
Если на запрос был дан ответ n, то редактор даст еще один шанс сохранить изменения и выдаст сообщение:
| Modified buffers exist; exit anyway? (yes or no) |
Запуск PSGML
Каким образом Emacs узнает о необходимости загрузки режима PSGML? Это может быть осуществлено тремя способами:
Во-первых, это режим автоматической загрузки, он включается при редактировании файла с расширением .sgml или .sgm. Во-вторых, это режим ручной загрузки. В командной строке минибуфера (M-x) нужно ввести имя режима (в данном случае - sgml-mode). Ручная загрузка полезна при редактировании файлов SGML, которые не имеют расширения .sgml или .sgm. В-третьих, это командный режим. Следующая строка в верхней части файла сообщает Emacs о необходимости автоматической загрузки PSGML:
| <!-- -*- sgml -*- --> |
При запуске Emacs с PSGML и загрузке документа, PSGML не станет анализировать документ (если переменным sgml-auto-activate-dtd и sgml-set-face заранее не присвоены значения "t") пока не будет выполнена одна из команд определенной категории. Из-за этого, в частности, нельзя выполнять автоматическое форматирование текста, которое облегчает визуальное восприятие текста при редактировании документа. Например, не происходит выравнивание уровней вложенности элементов или отсутствует отображение разметки различными шрифтами или цветом. Одна из команд, которая способна заставить работать PSGML, это команда sgml-next-trouble-spot, которая может быть вызвана нажатием C-c C-o или через пункт Next Trouble Spot меню Move. В настоящее время PSGML еще не является полноценным синтаксическим анализатором (недостатки, как будет показано в главе "Обнаружение ошибок разметки", достаточно легко устранимы). PSGML может выявить достаточно большое количество потенциальных ошибок через синтаксический анализ, в то время, как часть из них может быть обнаружена еще на стадии визуального форматирования.
Наиболее часто встречающаяся проблема, с которой сталкивается команда sgml-next-trouble-spot связана с тэгами. Это может быть неизвестный вид тэга, или неверное расположение тэга в тексте, или непарные скобки тэга. Если ошибок не обнаружено, то курсор перемещается в конец документа, заканчивает визуальное форматирование, и отображает в окне минибуфера сообщение Ok.
С большим числом элементов DTD, подобный синтаксический анализ может потребовать времени. При этом в окне минибуфера будут отображаться сообщения типа "Parsing doctype" и "Garbage collecting" (сочный термин для процедуры реорганизации оперативной памяти). Ускорить данный процесс можно, если предварительно сохранить DTD в виде специальной откомпилированной версии, которую PSGML загружает гораздо быстрее. Данная процедура осуществляется запуском команды sgml-save-dtd из командной строки минибуфера M-x. PSGML предложит сохранить откомпилированную версию текста в том же самом каталоге с тем же самым именем, что и у редактируемого документа, но с расширением .ced. Если название каталога или имя файла будет изменено, то затем, при запуске команды sgml-load-dtd, нужно будет вводить полное имя пути откомпилированного файла. Если PSGML сохранят откомпилированный файл с заданным по умолчанию именем и каталогом, то при последующем редактировании этого документа, он будет сам находить эту откомпилированную версию.
Значения переменных
Переменные могут интерпретироваться как числовые или строковые. Они принимают значения в зависимости от контекста, например:
x = 1, x воспринимается как число;
x = " ", x - строка;
x + "abc" - результат операции интерпретируется как число независимо от того, было ли х числом или строкой. Если строка не может быть интерпретирована как число ("abc"), то ее значение становится 0.
Строка может содержать максимально до 256 символов.
