Шпаргалка по редактору "Emacs"
^H k <ключ> Краткое / полное описание ключа ^H f <функция> Описание функции ^H a <текст> Все функции с этим текстом ^H w <функция> На какой клавише висит функция
Шрифтовое оформление документа
Как известно, по умолчанию в TeX используется семейство шрифтов Computer Modern в собственном формате METAFONT. И хотя эти шрифты не только существуют во всех требуемых кодировках, но и обладают вполне приличными эстетическими качествами, всякое однообразие со временем приедается. К тому же при всех достоинствах технологии METAFONT приходится считаться с тем обстоятельством, что подготовленный с использованием шрифтов в этом формате postscript-файл нельзя будет распечатать на компьютере, где отсутствует TeX.
Поэтому всякий пользователь LyX, вероятно, рано или поздно обратит внимание на вкладку «Документ» в диалоговом окне «Формат документа», где в числе прочих опций имеется и раскрывающийся список «Шрифты», предназначенный для выбора основной текстовой гарнитуры. Так вот: к сожалению, надлежит знать, что для русскоязычного пользователя данный список бесполезен. Перечисленные в нем шрифты соответствуют пакетам из стандартной коллекции psnfss, которая обеспечивает поддержку некоего малого джентльменского набора гарнитур Type 1, прилагаемых к любому PostScript-принтеру. Естественно, все эти гарнитуры не содержат символов кириллицы, и потому при попытке их загрузки LaTeX просто выдаст предупреждение об отсутствии шрифта в требуемой кодировке, после чего переключится на стандартный Computer Modern.
Замечу, что дополнить список шрифтов нельзя: он, как и в случае с выбором входной кодировки, жестко задан в ресурсах диалога. И, в общем-то, это понятно: всё равно программа не смогла бы среди сотен пакетов LaTeX самостоятельно найти именно те, которые ведают загрузкой шрифтов. Но хоть бы предоставили пользователю возможность ввести требуемое название вручную: ведь всё, что требуется, это передать системе LaTeX имя пакета, подлежащего загрузке. Впрочем, это не исключает возможности использования нестандартных гарнитур, а только слегка ее затрудняет.
Правда, готовых шрифтовых пакетов для TeX с поддержкой кириллицы весьма и весьма немного. Самостоятельное же их изготовление представляет собой дело хотя и возможное, но достаточно нетривиальное и требующее определенных познаний. Ну а те пакеты, которые доступны в Сети, по большей части либо сделаны непрофессионально, либо вызывают сомнения с точки зрения соблюдения авторских прав. Практически единственным безупречным во всех отношениях является пакет literat, позволяющий использовать для оформления текстов гарнитуру «Литературная» производства фирмы Paratype. Так вот, если мы установим этот пакет и пожелаем использовать его в LyX, единственным выходом из положения будет прямое редактирование преамбулы LaTeX. Для этого из меню «Layout» вызываем диалог «LaTeX-преамбула», в котором и пишем:
\usepackage{literat}
После чего можем наслаждаться видом нового шрифта при просмотре DVI и на печати.
Шрифты
Шрифты - это очень важная вещь, ибо, работая, вы постоянно на них смотрите, поэтому очень важно, чтобы со шрифтами все было в порядке. По умолчанию в Red Hat Linux 8.0 идут Unicode-ные шрифты, в которых отсутствуют русские буквы. Для того, чтобы это исправить, нужно:
скачать пакет с хорошими шрифтами http://mcmcc.bat.ru/RPMS/XFree86-75dpi-fonts-4.2.0-73.i386.rpm.
поставить его командой:
rpm -Uhv XFree86-75dpi-fonts-4.2.0-73.i386.rpm
перезапустить сервер шрифтов командой:
service xfs restart
удалить в домашнем каталоге файл ".fonts.cashe-1" командой:
rm -rf $HOME/.fonts.cache-1
На данном этапе у нас уже заработает почтовый клиент Ximian Evolution.
найти где-нибудь (на вашей машине, на машине вашего приятеля, или просто директорию с микрософтовскими TTF-шрифтами) директорию C:WINDOWSFONTS или что-то в этом духе и скопировать оттуда все TTF-шрифты (файлы с расширением *.ttf) в директорию /usr/X11R6/lib/X11/fonts/TTF.
в директории /usr/X11R6/lib/X11/fonts/TTF выполнить команды:
mkfontdir
mkfontdesc
mkfontscale
В файле /etc/fonts/fonts.conf у вас должно быть записано что-то типа:
<dir>/usr/X11R6/lib/X11/fonts/Type1</dir> <dir>/usr/share/fonts</dir> <dir>~/.fonts</dir>
вам нужно туда дописать строчку:
<dir>/usr/X11R6/lib/X11/fonts/TTF</dir>
чтобы у вас в итоге получилось:
<dir>/usr/X11R6/lib/X11/fonts/Type1</dir> <dir>/usr/share/fonts</dir> <dir>/usr/X11R6/lib/X11/fonts/TTF</dir> <dir>~/.fonts</dir>
теперь перезапускаем сервер шрифтов:
service xfs restart
закрываем все программы и перезагружаем X-Window нажатием Ctrl+Alt+Backspace
Ура! В нашей системе теперь красивые шрифты и, значит, в ней будет приятно работать. Нажмите на иконку "Start Here" -> "Preferences" -> "Font" и "поиграйтесь" со шрифтами.
Все приложения использующие gtk2 можно не трогать - они теперь работают нормально. А вот приложения основанные на gtk1 - xchat, evolution и др. нужно потрогать. А именно в их настройках, отвечающих за шрифты поставить любой понравившийся шрифт и указать ему кодировку iso10646.
Синхронизация
Блокировки
Race Conditions
Разрешение блокировок
То, как справляться с блокировками уже обсуждалось в разделе Блокировки и Разрешение блокировок.
Использование команды L сильно ограничено тем, что пишущий не может помечать места, на которые будет можно сослаться в дальнейшем в командах L: команды, подобной "acnhor" в HTML нет.
Вторым ограничением является то, что некоторые POD-трансляторы пытаются умничать и "украшают" ссылки дополнительным текстом. Например, pod2latex в примере ниже преобразует обе ссылки на пункты списка:
Как справляться с блокировками обсуждалось в разделе, обозначенном как \textsf{Блокировки$|$"item\_Блокировки"} в другом месте этого документа, и в разделе, обозначенном как \textsf{Разрешение блокировок$|$"item\_Разрешение\_блокировок"} в другом месте этого документа.
Примечание переводчика: Переводя эту статью, я проделал несколько экспериментов с целью уточнить, как описанные приемы работают в кириллическом окружении. Так вот, у меня на компьютере pod2latex фрагмент приведенного выше примера превратил в следующий текст << То, как справляться с блокировками уже обсуждалось в L<разделе Блокировки$|$"item\underscore{}Блокировки"> и L<Разрешение блокировок$|$"item\underscore{}Разрешение\underscore{}блокировок">. >>. Т.е., совсем странно, я даже не стал пробовать, как это будет в dvi:( Поэтому я привожу ниже тот же параграф по-английски, для того, чтобы можно было легче понять мысль автора:). pod2html, впрочем, отработал на примере нормально (или почти нормально). А вот pod2text "сумничал": << Как справляться с блокировками обсуждалось в разделе the section Блокировки... >>
How to cope with deadlocks was discussed in the \textsf{Deadlocks$|$"item\_Deadlocks"} entry elsewhere in this document, and the \textsf{Recovering from Deadlocks$|$"item\_Recovering\_from\_Deadlocks"} entry elsewhere in this document.
подчеркнутые слова добавлены pod2latex. Ясно, что нам нужен способ получше. Этот лучший способ осуществляется с помощью формато-специфичных абзацев.
XML напоминает HTML. Фундаментальное отличие
Синтаксис DocBook/ XML напоминает HTML. Фундаментальное отличие между ними -- строгость, с которой требуется выполнение синтаксических правил. Многие HTML-браузеры в высшей степени терпимы к "незакрытым" [unterminated] элементам и обычно безмолвно игнорируют неизвестные элементы и атрибуты. Трансляторы DocBook/XML отвергают не соответствующие DTD входные данные отказываясь в этом случае выдавать какие-либо выходные данные. Отказ сопровождается подробным отчетом об обнаруженных ошибках.
DocBook/XML имеет несколько "наречий", отличающихся интерпретацией закрывающих тэгов. Наиболее "многословный" диалект всегда закрывает тэг <tag> с помощью </tag>. Другой вариант допускает сокращение закрывающего тэга до </>, в то время, как третий вообще разрешает опускать закрывающий тэг в пустых элементах. Я предпочитаю "выписывать" все тэги, стиль, который доказал свои преимущества для таких грубоко вложенных структур, как, например, вложенные списки. Поэтому в этой статье будет встречаться только форма <tag> ... </tag>.
Специальные символы записываются с помощью привычных соглашений об амперсанде & и точки с запятой ;, как и в HTML. Наиболее часто употребимые специальные символы:
Амперсанд, "&" Меньше чем, "<" и Больше чем, ">".
Комментарии заключаются между "спецскобками" <!-- и -->.
Абзацы Абзацы разделяются одной или более пустыми строками. Число пустых строк не влияет на окончательный вид документа -- одна пустая строка так же хороша, как и несколько. Тоже самое относится к пробелам (разделяющим отдельные слова (но разве вы этого не знали?): сотня пробелов выглядят так же, как и один. Символы новой строки, т.е. завершители строк, считаются пробелами, как и символы табуляции. Если мы применим эти простые правила к трем различным версиям двух приведенных ниже абзацев, то мы придем к выводу, что все они будут одинаково выглядеть на печати. Я добавил номера в начале каждой строки для того, чтобы указать на пустые строки, отделяющие абзацы друг от друга. Эти номера не являются частью текста.
Вариант A 1 Я короткое предложение из первого абзаца. 2 3 А я единственное предложение второго абзаца.
Вариант B 1 Я короткое предложение 2 из первого абзаца. 3 4 А я 5 единственное предложение 6 второго 7 абзаца.Group arguments together
Вариант C 1 Я короткое предложение из первого абзаца. 2 3 4 А я единственное 5 предложение 6 второго абзаца.
Специальные символы Большинству не буквенно-цифровых символов в LaTeX придается специальное значение. Это одно из свойств, приводящих новичков в ужас. Однако через некоторое время привыкаешь учитывать особенности поведения тех или иных символьных комбинаций. Я собрал несколько наиболее важных специальных символов вместе со способами вставить их в текст так, чтобы они правильно отображались на печати.
\ Начинает команду: "\dots" или "\/". Обратите внимание на то, что "\\" не вставляет в текст одиночную обратную косую черту, как могли бы подумать пишущие на C. Управляющая последовательность "\\" вставляет перевод строки, а "буквальная" обратная косая черта вставляется с помощью "$\backslash$". Для того, чтобы еще больше все запутать: "\", т.е. обратная косая черта, за которой следует пробел -- это тоже команда! Она вставляет так называемый "управляемый" пробел, т.е. такой пробел (точнее: в точности один такой пробел), который никогда не "съедается", подобно обычным пробелам, как это объяснялось в разделе "Абзацы". {} Группирует аргументы вместе. Для того, чтобы вставить собственно символ фигурной скобки, его надо "заэскейпить" с помощью обратной косой черты: "\{" или "\}". % Начинает комментарий, продолжающийся до конца строки. Комментарии продолжаются до и включают символ новой строки в ее конце. Этим комментарии в LaTeX отличаются от однострочных комментариев во всех обычных языках программирования, которые не включают символ новой строки. С точки зрения пользователя это означает, что символ новой строки можно замаскировать, заканчивая строку комментарием. Hessenberg-% Triangular % <- обратите внимание на пробел непосредственно перед символом % Reduction
Мы уже заметили, что команды Texinfo начинаются с символа "собаки" -- "@". За ним либо следует единственный небуквенный символ, либо один или несколко букв. Вот несколько команд первой группы:
@@
Вставляет собственно символ коммерческого at ("@"). @"символ
Выводит "умляут-эквивалент" символа, где под символом понимается один из символов ASCII, например "a". То же самое относится к буквам, "украшенным" акцентами (@'символ), циркумфлексом (@^символ) или цедилью (@,символ). За подробностями обратитесь к узлу "Вставка акцентов [Inserting Accents] в документации Texinfo.
а вот примеры из второй группы:
@contents
Вставляет содержание в месте вхождения команды @contents. @page
Начинает новую страницу. @findex имя-фунции
Заносит имя-функции в индекс всех функций.
Команда может требовать один, два, три и более аргументов или не требовать их совсем. Некоторые команды требуют, чтобы агрументы заключались в фигурные скобки, например команда перекрестной ссылки @xref{имя-узла, имя-перекрестной-ссылки, заголовок-раздела}. Мы уже видели команды, считающими своим аргументом остаток той строки, в которой они появляются (например, команда @setfilename).
Формат POD определяет абзацы трех разных типов. Абзацы отделяются друг от друга одной или большим числом совершенно(!) пустых строк.
Абзац с обычным текстом [Ordinary Paragraph]
Любая строка, не начинающаяся, по крайней мере, с четырех пробелов или знака равенства считается обыкновенным текстом. Пустая строка служит разделителем абзацев. Это означает, что документ записывается один абзац за другим, каждый из которых отделяется, по крайней мере, одной пустой строкой.
При окончательном выводе обычные абзацы выравниваются (если формат допускает выравнивание), при необходимости с добавлением пробелов.
Абзац с преформатированным текстом [Verbatim Paragraph]
Строки с отступом в четыре и более пробелов рассматриваются, как преформатированный текст. В окончательном виде они выводятся точно так, как набраны. Все инструкции форматирования, о которых мы будем говорить далее, в преформатированных абзацах не действуют.
Абзац-команда [Command Paragraph]
Команды начинаются со знака равенства "=" в нулевой колонке, за которым немедленно следует идентификатор. Обычно команда состоит из одной строки. Тем не менее, синтаксически команды являются абзацами, поскольку отделяются пустыми строками перед и после ними.
Siren Editor разработан компанией Siren
Siren Editor разработан компанией Siren Software, целиком основан на интерфейсе X/Motif и является интуитивным и легким в использовании. Все команды располагаются в выпадающих меню, хорошо продумана компоновка экрана и работа с мышью. Инсталляция и запуск редактора под силу даже неквалифицированному пользователю. Недостатком редактора Siren является то, что в нем отсутствует какая-либо поддержка процесса программирования, а также базовые средства форматирования текста. Поэтому Siren Editor может быть полезен, главным образом, при первичном наборе и минимальном редактировании текстов. По своей функциональности этот редактор чем-то напоминает NortonEdit из MS-DOS, который очень удобен, когда в текст надо быстро внести пару-другую изменений.
Сказ про TeXmacs, или как прикручивали шрифты TeX к графическому режиму, и что из этого получилось
Автор: Алексей Крюков, basileia@yandex.ru
Опубликовано: 02.04.2002
Оригинал: http://www.softerra.ru/freeos/17080/
В условиях острого недостатка средств визуального редактирования под Linux каждый текстовый процессор для этой операционной системы непременно становится предметом активного обсуждения в русскоязычном Интернете. Разбираются мельчайшие подробности русификации AbiWord и способы прикрутки новых шрифтов к Ted, равно как и сравнительные достоинства ApplixWord и StarWriter. Да и наша недавняя статья о LyX лишь развивает линии, намеченные предшественниками. Однако же существует программа данного класса, о которой в Сети как будто не обнаруживается почти никакой информации на русском языке. Да и на иностранных-то сайтах трудно найти что-либо, кроме рекламы, заимствованной из ее собственной документации. Имя этой программе - TeXmacs, а автора ее зовут Joris van der Hoeven.
Чем объясняется этот заговор молчания? Возможно, дело в том, что TeXmacs, что называется, обнаруживает способность работать с русскими текстами, так что тема русификации, столь важная в других случаях, не может послужить источником вдохновения. Впрочем, это, как мы увидим, только так кажется. А может быть, пользователей Linux сбивает с толку название программы, недвусмысленно указывающее на то, что она должна иметь отношение к TeX и Emacs. Ну а у этих двух явлений, при всей их разноплановости, общая черта по крайней мере одна: неисчерпаемость. Так что писать о них надлежит не коротенькие заметки в Сети, а толстенные талмуды.
Редактор SlickEdit фирмы MicroEdge известен
Редактор SlickEdit фирмы MicroEdge известен как "быстрый" редактор для разработчиков под MS-DOS. Однако его реализация под UNIX с точки зрения скорости и интерфейса оставляет желать лучшего. Более того, на некоторых из заявленных платформ редактор функционирует неустойчиво. Представляет интерес поддержка редктором таких языков программирования, как С, С++, Pascal, COBOL, dBase, Modula-3, Assembler. Макроязык имеет синтаксис, схожий с языком REXX, использующимся на мейнфреймах IBM и в OS/2. Рекомендовать SlickEdit можно лишь тем, кто имел с ним дело на других платформах.
Сохранение и выход
^\ Выход из режима "VI" в режим "EX". Редактор EX - строковый редактор, на основе которого построен редактор VI. Команда редактора EX для возврата в VI :vi. Q Выход из режима "VI" в режим "EX". Редактор EX - строковый редактор. Команда редактора EX для возврата в VI :vi. ZZ Выход из редактора с сохранением изменений.
Сохранение результатов редактирования
Чтобы сохранить уже существующий файл, который был подвергнут редактированию просто нажмите C-x C-s (или выберите из меню Files пункт Save Buffer) для запуска команды save-buffer. Чтобы сохранить вновь созданный файл под новым именем, нажмите C-x C-w (или выберите из меню Files пункт Save Buffer As...) для запуска команды write-file. Emacs попросит ввести имя файла. При необходимости можно воспользоваться кнопкой Backspace, чтобы стереть предложенный путь и набрать новый:
| Write file: c:\pathname\ |
Сокращения
В руководстве будут использованы следующие сокращения :
^X обозначает "control" символ. Например : ^d - удерживая клавишу "control" нажать соответствующий символ. Для этого примера используется клавиша "control" в сочетании с буквой "d".
Сортировка
Сортировка XML-тегов в XSLT выполняется посредством элемента <xsl:sort select="sort_by_this_attribute"> Этот элемент должен размещаться внутри xsl:apply-templates (сортировка может производиться так же и в элементе xsl:for-each прим. перев.). Сортировка может выполняться как по самим xml-тегам, так и по их атрибутам, порядок сортировки можно задавать по возрастанию или по убыванию (если символы нижнего регистра должны предшествовать символам верхнего регистра или наоборот).
Для демонстрации сортировки я использовал пример альбома с фотографиями, в который добавил элемент <xsl:sort>:
<xsl:apply-templates select="//photo"> <xsl:sort select="file" order="descending"> </xsl:apply-templates>
Здесь изменен порядок следования фотографий в выходном html-документе. Теперь xslt сначала упорядочит все элементы photo из xml-файла, а затем передаст их элементу template-match, вот почему xsl:sort должен находиться внутри элемента xsl:apply-templates.
Файлы xsl и html примера вы можете взять здесь:
sort.xsl. xslt-преобразование sort.html. отсортированный список
Создание макрокоманд
Разумеется, макрокоманды на встроенном языке NEdit можно создавать обычным образом, т. е. путем написания их кода "руками", благо особенности языка вполне внятно документированы в системе справки. Однако есть и другой способ, который для начала может оказаться более простым, - это протоколирование действий. Для этого требуется (рис. 1):
включить режим протоколирования (через меню Macro - Learn Keystrokes или комбинацию клавиш Alt+K); произвести с клавиатуры (но не с помощью мыши!) все необходимые действия в той последовательности, в какой мы хотим их сохранить; завершить режим протоколирования (меню Macro - Finish Learn или повторным нажатием клавиш Alt+K); в случае ошибки при наборе команд - прервать протоколирование (меню Macro - Cansel Learn) и, включив его еще раз, повторить требуемые действия уже без ошибок.
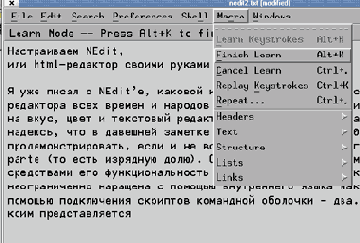 |
Рис. 1. Протоколирование макрокоманд в редакторе NEdit. |
Запротоколированная последовательность действий будет функционировать в течение данного сеанса работы с Nedit; первый раз ее можно вызвать через меню Macro - Reply Keystrokes, а в дальнейшем через Macro - Repeat. Однако при следующем запуске Nedit она будет утрачена.
Чтобы этого не случилось, следует сохранить созданную последовательность команд в виде пунктов меню Macro. Для этого, успешно завершив протоколирование данного макроса, отправляемся в меню Preferences, выбираем там пункт Default Settings, а в нем - опцию Customize Menu. Выбрав эту опцию, обнаружим пункт Macro Menu, вызывающий панель Macro Commands (рис. 2).
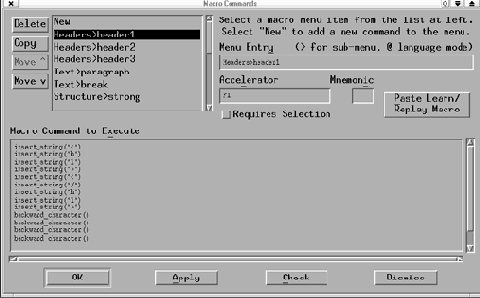 | |
| Рис. 2. Панель Macro Commands. |
В списке доступных команд (в левой части панели) фиксируем курсор на пункте New. В поле Menu Entry задаем название команды и, при необходимости, название более высокого уровня для группы сходных команд, например, таким образом:
Group commands>Command1
(без пробелов перед знаком > и после него). Здесь же можно приписать команду к какому-либо из доступных языковых режимов. Например,
Group commands>Command1@SGML/HTML
будет указывать, что данная команда активизируется только при выборе языкового режима SGML/HTML.
Затем заполняем поле Accelerator. Здесь за командой можно закрепить какую-либо клавишу (из числа, например, функциональных, или Windows-клавиш) или их комбинацию: например, сочетание клавиш Alt или Ctrl (возможно, еще в сочетании с Shift) с какой-либо буквой, желательно имеющей мнемонический смысл. Для этого нужно просто зафиксировать курсор в поле Accelerator и нажать требуемую клавишу (например, F12) или их комбинацию (допустим, Ctrl+литера). Следует только внимательно следить, чтобы эта комбинация не использовалась для вызова штатных функций NEdit: не исключено, что при этом она не будет вызывать ни старого, ни нового закрепленного действия.
Вслед за этим можно заполнить поле Mnemonic, введя в него какую-либо букву из имени нашей команды (так, как оно указано в поле Menu Entry). При вызове меню буква эта будет подчеркнута и теоретически может использоваться для быстрого вызова команды (в сочетании с клавишей Alt). Однако на деле это работает далеко не всегда. Вернее, почти всегда не работает, поскольку большинство букв латинского алфавита уже задействованы для штатных команд NEdit.
Наконец, последнее из предварительных действий - включение, если требуется, переключателя Requires Selection. Он предназначен для команд, которые осуществимы только с предварительно выделенными фрагментами (это, например, копирование, вырезание и т.д.).
А вот теперь нажимаем экранную клавишу Paste Learn/Replay Macro (в правой части панели). И текст макроса волшебным образом появляется в поле Macro Command to Execute, где его можно любым образом отредактировать, дополнить, сократить и т.д. После чего нажимаем клавишу OK, выходя из режима редактирования Macro Menu, - и можем испробовать новую функцию на практике. Если все работает нормально - сохраняем текущую ситуацию через меню Preferences - Save Defaults. Изменения при этом, как уже говорилось, фиксируются в секции
nedit.macroCommands:
файла . nedit из пользовательского каталога. Там же их можно отредактировать вручную.
Таким образом можно насытить меню редактора NEdit командами для выполнения часто требующихся действий, отсутствующих в штатном комплекте (например, как будет показано ниже, для ввода тегов HTML). Однако в некоторых случаях этого может оказаться недостаточно. Иногда возникает потребность в систематическом исполнении каких-либо внешних программ, например, команд оболочки. Конечно, в этом случае можно задействовать стандартное окно терминала либо обратиться к строке мини-терминала, вызываемой через меню Shell - Execute Command, или к клавишной комбинации (Alt+X). Можно еще прибегнуть к непосредственному вводу команд в поле редактирования NEdit с последующим их запуском (через меню Shell - Execute Command Line). Однако все это не обеспечит достаточно комфортной работы.
К тому же подчас необходимо, чтобы команда оболочки выполнялась по отношению к редактируемому в данный момент в NEdit документу (пример - команда ispell для проверки орфографии). И тут нам на помощь приходит еще одна возможность повышения функциональности Nedit - встраивание команд оболочки.
Создание PDF документов с использованием DocBook

Резюме:
Эта заметка рассказывает об использовании DocBook для разработки PDF - документов, утилитах для редактирования DocBook документов и перевода их в PDF - документы. В заметке не рассказывается об инсталляции утилит - они просто перечисляются, эта заметка предназначена опытным пользователям ОС Linux.
В первой части рассказывается о формате DocBook документов. После введения я расскажу об утилитах, необходимых для преобразования DocBook документов в PDF формат для просмотра их программой Acrobat.
Создание разделов.
Как и в LaTeX, могут быть определены разделы и подразделы. txt2html использует эти операторы для автоматического создания ссылок в оглавлении документа. Возможно три уровня
%section Name of a section
%subsection Name of a subsection
%subsubsection Name of a subsubsection
Создание споисков.
The item keyword is used для создания списков. Например, список покупок:
3 eggs
pint of milk
1/2 pound of cheese
was created as follows:
%item 3 eggs
%item pint of milk
%1/2 pound of cheese
Списки
В состав LaTeX входит три окружения для создания списков:
Список из ненумерованных пунктов [item list], иногда также называемый "bulleted list", т.е. список с "кружочками" нумервованный список и список описаний.
Они соответствуют ненумерованному списку, нумерованному списку и списку определений в HTML или спискам =item *, =item 1 и =itemтермин в POD.
Собственно элементы списка вводятся командой "\item" и могут состоять из нескольких абзацев.
В списке описаний необязательный параметр, задаваемый команде "\item" -- "\item[термин]" -- указывает термин. Последующий текст служит определение термина.
Примеры:
Список из ненумерованных элементов Что может сделать для Вас emacs: \begin{itemize} \item Вырезание и вставка блоков текста \item Переформатирование и выравнивание абзацев \item Проверка правописания в документах \end{itemize}
Нумерованный список Первый запуск emacs \begin{enumerate} \item Запускаем emacs из командной строки: \texttt{\$ emacs} emacs покажет экран запуска, а затем переключится в буфер под названием \texttt{*scratch*}. \item Нажмите клавишу~Control, а затем нажмите~H. Внизу экрана появится приглашение или окно emacs. \texttt{C-h (Введите ?, чтобы увидеть другие опции)-} \item Для того, чтобы запустить учебник emacs, нажмите~T . \end{enumerate}
Список описаний Некоторые команды emacs: \begin{description} \item[C-x C-c] Выйти из emacs. \item[C-x f] Открыть файл. \item[C-x r k] Стереть [kill] прямоугольник, заданный отметкой и указателем, т.е. активной областью [active region]. \end{description}
Внутри такой таблицы, аргументом @ item служит весь текст от самой команды @item до конца строки. Обратите внимание на это отличие от ненумерованных и нумерованных списков! Определением в таком "списке определений" должно занимать не более одной строки. Текст после такой @item-строки и до следующего элемента @item или конца таблицы становится описанием термина. Описание может состоять из нескольких абзацев, содержать другие списки и т.д.
Поскольку иногда нам нужны дополнительные термины на отдельных строках. Поскольку @item помещает свой аргумент на одной строке, для этого требуется другая команда: @itemx помещает дополнительный термин непосредственно под уже существующим. Команда @itemx допустима только сразу после команд @item или @itemx.
Copyright (C) 2002, Christoph Spiel.
Copying license http://www.linuxgazette.com/copying.html
Published in Issue 76 of Linux Gazette, March 2002
Команда переводчиков:
Владимир Меренков, Александр Михайлов, Иван Песин, Сергей Скороходов, Александр Саввин, Роман Шумихин, Александр Куприн, Андрей Киселев
Со всеми предложениями, идеями и комментариями обращайтесь к Сергею Скороходову (). Убедительная просьба: указывайте сразу, не возражаете ли Вы против публикации Ваших отзывов в рассылке.
Сайт рассылки: http://gazette.linux.ru.net
В Интернете эту статью пока взять негде, ждите второй половины:)
Список использованной литературы
GSwitchIt - переключатель раскладок клавиатуры.
http://mcmcc.bat.ru/ - довольно интересный ресурс McMCC по неправильной (с моей точки зрения) русификации (это не касается русификации X WIndow - она выполнена правильно).
RH Linux 8.0 Cyrillic Edition - целый дистрибутив с опять-таки неправильной русификацией.
Сравнение
Создадим идентичные ( теоретически ) файлы - два в редакторе WordPad в формате RTF и DOC и один в формате RTF в редакторе PressWork 2 от GTS.
Изображение 1. Кликните на изображении для детального просмотра.

Теперь попробуем открыть эти файлы разными приложениями : StarOffice, WordPerfect8, Maxwell, Abiword и Ted :
-StarOffice открыл файлы и заменил шрифт BibleScript на Helmet. Вид документов сохранился.
-WordPerfect и RTF формат : Arial был заменен на Univers, Courier на Courier 10cp, Times и BibleScript на CG Times. Вид документов ( кроме размера шрифта Courier ) сохранился. Файл в формате DOC открылся более успешно.
-Maxwell (версия 0.53) открыл ( причем плохо ) только Linux RTF файлы. Несмотря на то, что предусмотрена возможность открытия файлов в формате DOC - ничего не получилось.
-Abiword (версия 0.75 beta) достаточно корректно открыл и RTF и DOC.
-Ted прекрасно открыл Windows - RTF файл заменив BibleScript на Helvetica и любой RTF - файл созданный перечисленными выше Linux приложениями.
Изображение 2. Ted и WordPad - файл - похоже, что задача решена успешно. Кликните на изображении для детального просмотра.

Сравнительное решение задач с помощью SED и AWK
Система UNIX обладает несколькими утилитами, которые обрабатывают входной поток данных и позволяют также решать некоторые задачи редактирования: grep , egrep , fgrep , lex и awk . Мощная и многофункциональная утилита awk также может быть применена для простого редактирования текстов, поскольку также основана на использовании регулярных выражений. Однако, как видно из примеров, приведенных ниже, время решения задач с помощью sed значительно меньше по сравнению со временем, затрачиваемым awk . Неинтерактивный редактор sed обеспечивает выполнение в пакетном режиме большинства функций редактирования редактора ed и является оптимальным при решении несложных задач пакетного редактирования.
Средства форматирования
Существует множество средств работы с SGML текстами. Бóльшую их часть составляют средства форматирования -- экспорта SGML в другие форматы для печати, просмотра и т.п. Выходные форматы могут быть любыми, завися лишь от доступного программного обеспечения и нужд пользователя. Например, я использую конвертеры в HTML, RTF и LATEX.
SGML-процессоры могут быть устроены по-разному. Существует несколько поколений таких средств (стоит вспомнить, что SGML отсчитывает уже второй десяток лет своей истории). Обычно они включают:
анализатор, разбирающий SGML документ, проверяющий корректность документа и строящий некоторое внутреннее представление иерархии элементов документа;
ядро, предоставляющее базовые функции работы с SGML (возможно, объединенное с анализатором в единую программу);
набор спецификаций, задающих ядру программы для конкретной обработки документа.
Синтаксический разбор SGML довольно сложен, поэтому полноценных анализаторов существует немного. Эталонным считается пакет .
Спецификации, или стили, пишутся на предлагаемом ядром языке программирования. Есть SGML-процессоры, программируемые на языках Perl, Tcl, диалектах Lisp, и т.п. Каждый процессор предлагает собственное представление иерархии документа и собственные примитивы работы с ним.
Такое положение призван изменить недавно принятый стандарт DSSSL (Document Style Semantics and Specification Language). Он специфицирует единый язык и интерфейсы SGML-процессоров. Используемый в нем язык программирования близок к популярному функциональному языку Scheme.
Средства KDE - Kedit, Kwrite, Katy
Графическая среда KDE включает в себя два штатных текстовых редактора Kedit (именуемый в русском варианте простым) и Kwrite (названный по русски расширенным).
Первый из них - это закаленное и отточенное орудие для набора текстов. И особенно - для их придумывания. Поскольку Kedit содержит большинство функций для набора текстов и их простейшего редактирования: выделение, копирование, вставка, поиск и замена. И - ничего лишнего для их форматирования. А также имеет почти все необходимые и все достаточные настройки.
Манипуляции с текстами в Kedit осуществляются посредством строки меню и инструментальной панели. В последней - кнопки для файловых операций (создание, открытие, запись), редактирования (копирование, вставка, вырезание), печати и почты. Панель, правда, не настраиваемая.
Пунктов меню - три (не считая help): Файл, Редактирование, Настройка. В первом - создание и открытие (в том числе из списка недавних) файла, его сохранение (и под другим именем тоже) и закрытие. Можно открыть файл из удаленного источника и сохранить в таковом. Здесь же - печать, отправка и прием почты, выход. А также - создание нового окна: Kedit - редактор однооконный, для каждого нового документа требуется запустить его отдельную копию.
В пункте Редактирование - копирование, вставка (которая возможна и стандартным способом, средней клавишей мыши) и вырезание, выделение (всего), вставка даты. Здесь же - поиск, замена, проверка правописания, переход на строку.
Настройки - достаточно богаты для такого простого на вид инструмента. Можно настроить гарнитуру шрифта и его начертание, кегль и, при необходимости, кодировку. Поддаются переопределению цвета шрифта и фона (можно выбрать их стандартной палитры или назначить собственный), параметры Spellchecker'а (выбор словаря и кодировки, по умолчанию используется стандартные для ispell), граница (в знаках) для переноса слов и т.д. Для сохранения установок в следующем сеансе их следует запомнить (подпункт Записать установки).
В общем, инструмент более чем пригодный для набора текстов. Из принципиальных недостатков я отметил бы только отсутствие возможности делать закладки в тексте, и отстутствие функции Undo/Redo. Навигация несколько затруднена невозможностью перейти в начало или конец текста (например, с помощью привычных клавиш Control+Home и Control+End). Не предусмотрен многооконный режим - для работы с несколькими документами нужно открывать соответствующее количество экземпляров программы. Нет также подсветки синтаксиса, но это уже - из области роскошного.
Редактор Kwrite чрезвычайно сходен по интерфейсу с Kedit. Название редактора Kwrite вызывает ассоциацию с приснопамятным по временам Windows 3.xx Write. Однако функционально он отличен от редакторов общего назначения типа Kedit, поскольку предназначен для написания не столько просто текстов, сколько текстов исходных.
С точки зрения интерфейса Kwrite очень сходен с Kedit, обнаруживая строку меню и панель кнопок (рис. 11). Пункты меню почти те же - Файл, Редактирование, Настройки, плюс Закладки.
В пункте Файл - создание, открытие (в том числе Open Recent) и сохранение (в том числе Save as), печать, Новое окно (открытие пустого окна) и Новый вид (открытие второй копии того же документа в новом окне): как и Kedit, Kwrite не является многооконным редактором в полном смысле слова, требуя отдельного своего экземпляра для каждого файла. Кроме того, есть вставка существующего файла в текущий. Ну и выход, конечно.
В пункте Редактирование - стандартные Вырезать, Копировать, Вставить, а также Undo и Redo (отсутствующие в Kedit), поиск, замена, переход на строку. Кроме того, здесь есть ввод отступа строки и и его отмена, и всякого рода выделение (всего, отмена и обращение выделения).
Добавленный против Kedit пункт Закладки содержит три очевидные подпункта - установка, добавление и уничтожение закладок.
А вот настройки в Kwrite существенно отличаются от таковых в Kedit. Перво-наперво, в нем можно установить раскраску синтаксиса какого-либо языка - C, C++, Java, HTML и т.д. Далее, в подпункте По умолчанию устанавливаются гарнитура, размер, кодировка и цвет шрифта, как для нормального текста, так и для различных типов данных. Затем - Раскраска, где настраиваются цвета для языковых конструкций. Так, если ранее была выбрана раскраска HTML, здесь можно определить цвета не только для тэгов, но и для атрибутов и их значений, в результате чего html-код может принять сколь угодно пестрый вид.
Подпункт собственно Настройки - это возможность установить ограничение длины строки (при включении переноса по словам), величину табуляции, уровни отмены, всякого рода отступы, а также параметры выделения (в том числе множественно и вертикальное выделение, иногда - очень полезная возможность).
Еще одна очень интересная возможность - изменение символа конца строки: помимо свойственного Unix LF, можно установить DOS'овский CR-LF или Mac'овский CR.
Также в пункте настройки можно определить горячие клавиши для большого количества команд - перемещения курсора, файловых операций, редактирования, выделения, поиска, замены и перехода. Назначение прочих подпунктов - понятно без комментариев.
Панель кнопок предназначена для производства стандартных операций с файлами, редактирования, отмены и возврата.
Из обзора возможностей Kwrite и его настроек видно, что это типичный редактор для программиста. Что подчеркивается, скажем, отсутствием функции проверки орфографии и даже печати. Однако и для набора длинных связанных текстов он вполне пригоден. А орфографию можно всегда проверить и в любой внешней программе, просто в ispell, наконец.
Кроме штатных, для работы в KDE предназначен такой редактор, как Katy - очень простой, но удобный. Его отличительная особенность - многооконность, переключение между загруженными документами осуществляется с помощью закладок.
Текущая версия Katy (0.2.3), вероятно, еще не вполне функциональна. Об этом можно судить по тому, что разработчиками он позиционируется как аналог такого редактора для Windows, как UltraEdit, но существенно не дотягивает до него по своим возможностям.
Интерфейс Katy достаточно стандартен для KDE-приложений. Управление осуществляется через меню или почти дублирующую его функциональную панель. В меню - пункты:
File, содержащий стандартные операции с файлами (создание, открытие, сохранение и прочие, включая печать); здесь привлекает внимание возможность сохранения всех открытых файлов (Save All), а также установка конца строки - с стиле Unix, DOS или MacOS; Edit, также достаточно обычен по набору функций (Undo и Redo, копирование, вырезание и вставка, поиск и замена); стоит отметить только возможность принудительного переключения регистров (с нижнего на верхний и наоборот, а также инвертирование); View - это просто переключатели скрытия/показа инструментальной панели и статусной строки; Options - минимальные настройки (гарнитура и кегль шрифта, его кодировка, величина табуляции).
Полезно, что закладка каждого измененного, но не сохраненного файла маркируется звездочкой.
Из недоработок бросаются в глаза отсутствие переноса слов и подсветки синтаксиса, что весьма необычно для редактора, претендующего на статус развитого. Кроме того, Katy не может похвастаться и стабильностью.
Разумеется, описанными примерами список текстовых редакторов графического режима не исчерпывается. Поэтому более или менее кратко затронем
Ссылки
1. 2. Quick Reference: DocBook Elements 3. Emacs major mode for DocBook 4. <a href="http://nwalsh.com/docbook/dsssl/index.html">The Modular DocBook Stylesheets 5. 6. OpenJade 7. JadeTeX 8. 9. DocBook: The Definate Guide on SGML variant
| Webpages maintained by the LinuxFocus Editor team © Egon Willighagen LinuxFocus.org 2000 Click here to report a fault or send a comment to Linuxfocus |
Translation information: |
| en | -> | -- | |
| en | -> | ru |
2000-07-05, generated by lfparser version 1.5
Адрес оригинала заметки: www.eng.hawaii.edu/Tutor/vi.html
Загрузить VIM, популярную версию редактора VI из http://www.vim.org/
Вопросы и комментарии направляйте ben@wiliki.eng.hawaii.edu (Ben Y. Yoshino)
Last updated on Tuesday, December 10, 1996
Updated on Thursday, July 27, 1995
Updated on Monday, October 3, 1994
Copyright © 1996 University of Hawaii, College of Engineering, Computer Facility
All rights reserved.
| Webpages maintained by the LinuxFocus Editor team © Ben Y. Yoshino LinuxFocus.org 2000 Click here to report a fault or send a comment to Linuxfocus |
Translation information: |
| en | -> | -- | |
| en | -> | ru |
2000-07-05, generated by lfparser version 1.5
Примеры (пример 'card', был написан до того как я начал работу над этой статьей, надеюсь он будет вам полезен):
http://gazette.linux.ru.net/lg89/misc/danguer/cards.html
http://gazette.linux.ru.net/lg89/misc/danguer/cards.xml
http://gazette.linux.ru.net/lg89/misc/danguer/cards.xsl
http://gazette.linux.ru.net/lg89/misc/danguer/hello.html
http://gazette.linux.ru.net/lg89/misc/danguer/hello.xml
http://gazette.linux.ru.net/lg89/misc/danguer/hello.xsl
http://gazette.linux.ru.net/lg89/misc/danguer/hello_style.html
http://gazette.linux.ru.net/lg89/misc/danguer/hello_style.xml
http://gazette.linux.ru.net/lg89/misc/danguer/hello_style.xsl
http://gazette.linux.ru.net/lg89/misc/danguer/hello_style_variables.html
http://gazette.linux.ru.net/lg89/misc/danguer/hello_style_variables.xsl
http://gazette.linux.ru.net/lg89/misc/danguer/variables.html
http://gazette.linux.ru.net/lg89/misc/danguer/variables.xsl
http://gazette.linux.ru.net/lg89/misc/danguer/variables_select.html
http://gazette.linux.ru.net/lg89/misc/danguer/variables_select.xml
http://gazette.linux.ru.net/lg89/misc/danguer/variables_select.xsl
http://gazette.linux.ru.net/lg89/misc/danguer/sort.xsl
http://gazette.linux.ru.net/lg89/misc/danguer/sort.html
http://gazette.linux.ru.net/lg89/misc/danguer/documents.xml
http://gazette.linux.ru.net/lg89/misc/danguer/documents.xsl
http://gazette.linux.ru.net/lg89/misc/danguer/documents.html
http://gazette.linux.ru.net/lg89/misc/danguer/documents_for.html
http://gazette.linux.ru.net/lg89/misc/danguer/documents_for.xml
http://gazette.linux.ru.net/lg89/misc/danguer/documents_for.xsl
http://gazette.linux.ru.net/lg89/misc/danguer/documents_choose.xsl
http://gazette.linux.ru.net/lg89/misc/danguer/documents_choose.html
Ссылки на меня :-)[по результатам /var/log/httpd/referer.log]
Содержание
Last changed 02-01-2000.
Ссылки по теме
— статья о проблемах русских кодировок в Сети
— официальный сайт кодировки Unicode
Заметки об извращениях — подробно о русских кодировках
Почтовый декодер Арт. Лебедева — расшифровывает письма, пришедшие в неизвестных науке кодировках
"Крестоносцы" — статья "КомпьюТерры" о проблемах с кодировками
Стандартные PC-клавиши
Ctrl+Insert: копирование выделенного (первичным методом) фрагмента в буфер; аналогично действию меню Edit - Copy или клавишной комбинации Ctrl+C; введено для совместимости со стандартом клавишных комбинаций приложений Motif.
Shift+Ctrl+: помещение выделенного (первичным методом) фрагмента в позицию курсора.
Delete: действует обычным образом, то есть удаляет символ после позиции курсора.
Ctrl+Delete: удаляет часть строки от позиции курсора до конца.
Shift+Delete: удаление выделенного фрагмента с помещением его в буфер (подобно команде Cut в большинстве Windows-приложений); аналогично действию через меню Edit - Cut или комбинации клавиш Ctrl+X).
Shift+Ctrl+Delete: удаление выделенного первичным методом фрагмента, то же, что просто Delete.
Home: перемещение курсора в начало строки.
Ctrl+Home: перемещение курсора в начало документа.
End: перемещение курсора в конец строки.
Ctrl+End: перемещение курсора в конец документа.
PageUp: перемещение курсора назад на один экран (экранную страницу).
Ctrl+PageUp: довольно заковыристая комбинация, перемещает курсор в пределах абзаца (или истинной строки) влево на столько знаков, сколько имеет место на текущей экранной строке; или, при других опциях переноса слов, на один экран по горизонтали влево.
PageDown: перемещение курсора вперед на один экран (экранную страницу).
Ctrl+PageDown: то же, что и комбинация Ctrl+PageUp, но перемещает курсор, соотвественно, вправо.
F10: якобы активизирует меню для выбора пунктов с клавиатуры посредством клавиш управления курсором и т.д. В моей версии не работает.
Standarts
Существует несколько стандартов описания сharset и способов их кодирования :
Character Mnemonics & Character Sets
ISO 2022
ISO 9945-2
UNICODE (ISO10646) UCS-2, UTF-7, UTF-8
(???)
Описание наборов символов , , в формате POSIX.
Что касается имен
зарегистрированных Charset-ов, то смотри .
Страница отзывов
У каждой заметки есть страница отзывов. На этой странице вы можете оставить свой комментарий или просмотреть комментарии других читателей.
| talkback page |
| Webpages maintained by the LinuxFocus Editor team © Andre Pascual, FDL LinuxFocus.org Click here to report a fault or send a comment to Linuxfocus |
Translation information: |
| fr | -> | -- | |
| fr | -> | de | |
| de | -> | en | |
| en | -> | ru |
2000-11-06, generated by lfparser version 2.1
Структура документа
Как уже говорилось, документы DocBook должны соответствовать заданной в DTD структуре. В начале каждого документа выбирается конкретная DTD:
<!DOCTYPE (1) book (2) PUBLIC "-//OASIS//DTD DocBook XML V4.1//EN" (3) "/usr/share/sgml/db41xml/docbookx.dtd" (4) [ ] (5) >
Для наглядности я разбил заключенное между "<" и ">" выражение на строки и пронумеровал их.
В части (1) говорится, что мы собираемся выбрать DTD. Часть (2) определяет элемент , который становится корневым элементом нашего документа. В части (3) идентификатор PUBLIC сообщает транслятору местоположение DTD на данном конкретном компьютере. Квадратные скобки, составляющие часть (5), могут содержать так называемые определения сущностей [entity definitions], но, поскольку в введении мне не хочется вдаваться в детали, эта часть оставлена пустой.
Итак, наш текст начинается с корневого элемента, в данном случае с book. То, какие элементы могут появится внутри определяется в DocBook DTD. Это может быть, например, bookinfo или chapter. Исчерпывающий перечень разрешенных элементов можно узнать из "Всеобъемлющего руководства". Элементы, которые могут появится внутри bookinfo или chapter определены в DocBook DTD, как и все другие элементы. Единственный способ составления правильного [valid] документа -- следование предписаниям DTD.
Хотя в первый момент правила могут показаться обременительными (Правила? Черт бы их побрал, эти правила!), но они играют ключевую роль в доступе к документам из программ. Поскольку документ соответствует DTD, то вся последующая обработка может использовать это обстоятельство. Какая радость для пишущих программы-обработчики! Признаю, что число элементов и их взаимоотшения понять непросто. Впрочем, эти взаимоотношения вполне логичны: глава [chapter] может содержать один или несколько (вводных) абзацев и один или несколько разделов первого уровня [level 1 sections]. С другой стороны, ни один раздел не может включать главу -- что было бы нелепо. Изучению DocBook может также помочь экземляр "Всеобъемлющего руководства", "поселившийся" рядом с клавиатурой. Ниже приводится краткая подборка часто используемых тэгов.
Вот совсем коротенький, но полный документ DocBook.
<!DOCTYPE book PUBLIC "-//OASIS//DTD DocBook XML V4.1//EN" "/usr/share/sgml/db41xml/docbookx.dtd" []> <book> <bookinfo> <title>XYZ (версия 0.8.15) Руководство пользователя</title> </bookinfo> <chapter id = "chapter-introduction"> <title>Введение</title> <para> Это глава содержит краткое введение в XYZ. </para> <sect1 id = "section-syntax"> <title>Syntax</title> <para> Раздес содержит обзор синтаксиса языка XYZ. </para> </sect1> <sect1 id = "section-core-library"> <title>Основная библиотека</title> <para> Использование некоторых основных библиотечных функций возможно даже если программа XYZ не загружает дополнительные библиотеки. </para>
</sect1> </chapter> <chapter id = "chapter-commands"> <title>Команды</title> <sect1 id = "section-interactive-commands"> <title>Команды диалогового режима</title> <para> ... </para> <sect2 id = "section-interactive-commands-argumentless"> <title>Команды, не требующие аргументов</title> <para> ... </para> </sect2> </sect1> <sect1 id = "section-non-interactive-commands"> <title>Команды, доступные в пакетном режиме</title> <para> ... </para> <sect2 id = "section-non-interactive-commands-argumentless"> <title>Команды, не требующие аргументов</title> <para> ... </para> </sect2> </sect1> </chapter> </book>
Структурирование текста
В главе "Настройка переменных редактора Emacs" говорилось о том, что переменная sgml-indent-step позволяет осуществлять автоматическое структурирование тэгов PSGML, путем смещения вложенных элементов на требуемое количество символов вправо. В Emacs существует команда, которая в режиме PSGML выравнивает тэги. Это команда indent-region, соответствующая комбинация клавиш - M-C-\.
Рассмотрим пример. Ниже приводится текст, в котором структурирование выполнено случайным образом.
| <sect2> <title>A Bosom Friend</title> <para>We then turned over the book together, and I endeavored to explain to him the purpose of the printing, and the meaning of the few pictures that were in it.</para> <figure> <title>A Sample Figure</title> <graphic fileref="giftest.gif" format="gif"></graphic> </figure> <para>Thus I soon engaged his interest; and from that we went to jabbering the best we could about the various outer sights to be seen in this famous town.</para> |
Выделите данный текст как блок и нажмите M-C-\. PSGML обработает выделенный фрагмент, сделав структуру элементов более понятной:
| <sect2> <title>A Bosom Friend</title> <para>We then turned over the book together, and I endeavored to explain to him the purpose of the printing, and the meaning of the few pictures that were in it.</para> <figure> <title>A Sample Figure</title> <graphic fileref="giftest.gif" format="gif"></graphic> </figure> <para>Thus I soon engaged his interest; and from that we went to jabbering the best we could about the various outer sights to be seen in this famous town.</para> |
Структурные тэги [Sectioning Tags]
Структурные тэги делят документ на логические части -- главы, разделы, абзацы и т.д.
chapter (глава), sect1 (раздел уровня 1), ..., sect6
<chapter id = "метка">
заголовок
за которым следуют
абзацы или разделы уровня N+1
</chapter>
Определяет раздел. Обычно, элемент-глава или элеметн-раздел несет атрибут id, который дает возможность ссылаться на данный элемент, например так: <xref linkend = "метка"></xref>.
para (абзац)
<para>
текст абзаца
</para>
Формирует абзац из нескольких строк текста. Этот элемент -- "рабочая лошадка" многих документов.
programlisting (листинг программы)
<programlisting role = "язык">
текст программы
</programlisting>
Воспроизводит значительный отрывок программного текста с сохранением разбиения на строки. Предполагается, что программа написана на языке, указанном в атрибуте role. Имейте в виду, что внутри programlisting все специальные символы сохраняют свое значение!
Syntax Highlighting, Statistics Line, Incremental Search Line и Show Line Numbers
Это - просто переключатели, с помощью которых можно показать или скрыть:
подсветку синтаксиса (Syntax Highlighting) языка, соответствующего данному режиму; строку состояния (Statistics Line); строку поиска (Incremental Search Line); нумерацию строк (Show Line Numbers).
Правда, для пункта Syntax Highlighting настройке поддается также Recognition Patterns и Text Drawing Styles. Что такое первое - я пока не разобрался, а второе - это приписывание каждому элементу языковых конструкций цвета и шрифтоначертания. Для языка HTML, например, можно определить различные цвета тэгов, их атрибутов и значений последних, комментариев, метатэгов и так далее.
Так же легко понять смысл следующего настраиваемого элемента -
Таблицы.
Создание простых таблиц с помощью txt2html делается с использованием ключевого слова, определяющего начало иконец таблицы, а также ключевого слова, определяющего каждую колонку. Знак | разделяет колонки. Например, таблица:
| Average height | Average weight | Red eyes | |
| Males | 1.9 | 0.003 | 0.4 |
| Females | 1.7 | 0.002 | 0.2 |
была создана строкой:
%table
%row | Average height | Average weight | Red eyes
%row Males | 1.9 | 0.003 | 0.4
%row Females| 1.7 | 0.002 | 0.2
%table
Talk
Начиная с OpenBSD 2.9, в программе talk, появилась поддержка русских символов. Другие, более старые версии talk не поддерживали русские символы. Для решения этой проблемы была создана программа bazar. Программа оформлена в виде порта с использованием файлов из /usr/src/usr.bin/talk от OpenBSD. Загрузить порт bazar можно .
Программа bazar полностью совместима с talk, но содержит следующие дополнения:
Добавлен скроллинг в окна Поддерживаются русские символы Добавлена возможность перекодировки koi8-r <> windows-1251
TED

Резюме:
Одно из главных препятствий перехода от Windows к Linux - несовершенство переноса данных между платформами. Если в области графических изображений это не проблема, то что касается документов и данных Microsoft Office это так.
Кто - нибудь обязательно возразит, что StarOffice 5.2 прекрасно взаимодействует с файлами Word и Excel, да это так, но всегда ли есть необходимость запускать такое мощное приложение для того, чтобы просмотреть или изменить простой файл Word или WordPad.
Как раз для этого и создан TED.
TED 2.la
Редактор TED разработан английской фирмой Eagle Dynamics, имеющей представительство в Москве, и на сегодняшний день является единственным полностью русифицированным профессиональным текстовым редактором для UNIX, распространяемым в России. Редактор работает как на текстовых терминалах, так и под Х Windows, при этом CUA-интерфейс делает его похожим на редактор MultiEdit для MS-DOS или среду разработки Borland IDE. Это единственный из всех редакторов, у которого имеется документация на русском языке (два тома). TED ориентирован как на профессиональных разработчиков, так и на неподготовленных пользователей, может быть легко перенастроен в соответствии с индивидуальными вкусами. Редактор распространяется практически на любых платформах UNIX. Единственным, но несущественным, по мнению автора, недостатком редактора является отсутствие развитого макроязыка, что, впрочем, компенсируется возможностью создания командных и клавишных макро.
Ted как орудие бюрократа и головотяпа
О чем - в продолжении, которое, как всегда, следует
Технология XML свободна от лицензирования, платформо-независима и хорошо поддерживаема

Revised 13 Nov. 2001 (last update: $Date: 2001/12/20 10:34:31 $)
Created 27 Mar 1999 by Bert Bos
Перевод: В.Ярошевич, 10 декабря 2001 года
(Previous version)
© 1999-2000 ® (MIT, INRIA, ), All Rights Reserved.
Текстовые буферы в редакторе VI
Редактор vi предоставляет пользователю 36 буферов для хранения информации и также буфер общего назначения. Удаленный или скопированный текст помещается в буфер общего назначения. Многие пользователи vi редко используют другие буферы. Но можно использовать так называемые "поименованные" буферы. Для их применения используется команда ". Эта команда используется в сочетании с буквой или цифрой для определения буфера. Например : команда "mdd использует буфер m для вырезания в него текущей строки. Команды p или P используются для вставки текста. Команда "mp вставит содержимое буфера m за текущей позицией курсора. Эти буферы могут быть использованы командами, рассматриваемыми в следующих двух разделах.
Текстовые процессоры
Здесь материалов будет существенно меньше. Во-первых, текстовых процессоров под Linux просто меньше, чем текстовых редакторов. Во-вторых, самые могучие из процессоров, по доброй традиции последних лет, выступают не самостоятельно, а в составе офисных комплектов, которые будут предметом следующей саги. И в третьих, многие программы, которые могли бы занять достойное место в этом разделе, находятся в процессе разработки и не могут считаться пока полнофункциональными.
Каково, на мой взгляд, предназначение текстового процессора? От ответа на этот вопрос будет зависеть и их оценка, а потому задержусь на нем чуть подробнее.
Можно наметить три сферы приложения текстовых процессоров:
первая - делопроизводство, то есть составление документов, которые должны быть оформлены в соответствие с определенными, обычно жесткими, требованиями; вторая - объединение и доведение до кондиционного вида неких материалов, подготовленных в текстовых и графических редакторах: третья - использование текстовых процессоров как универсального средства работы с текстовой информацией.
Рассмотрим их по очереди, начав с последней; поскольку именно для этого применяются текстовые процессоры подавляющим большинством пользователей, во-первых, и потому, что именно на это ориентированы все развитые коммерческие их представители - во-вторых.
Мне представляется, что это - самый нерациональный подход, который только можно себе представить. Почему - нетрудно ответить. Как известно, пятиборцы (да простят меня представители этого, очень мной любимого, вида спорта) - это те, кто все умеет делать. Плохо. И потому ожидать, что программа будет одинаково хорошо выполнять столь противоречивые функции, как просто ввод текста и его редактирование, форматирование, вставку рисунков и таблиц с их точным позиционированием (а подчас и обработку, и даже подготовку иллюстраций), сравнение версий с точки зрения содержания и оформления - было бы наивно. Каждый, кто пробовал набирать текст в PageMaker или верстать оригинал макет в Word - вероятно, спорить со мной не будет. Во всяком случае, то, что книжки, сверстанные в Word, безошибочно опознаются с первого взгляда (и не своими высокими оформительскими достоинствами) - медицинский факт, как сказал бы О.Бендер.
Даже если представить себе непредставимое (подобно квадратному трехчлену) и создать программу, в равной степени хорошо выполняющую все перечисленные (но далеко не все, которые могут реально потребоваться) функции удалось бы - страшно представить, каких аппаратных ресурсов потребует такой монстр. Впрочем, страшно-то страшно, но можно: именно тех, каких требуют современные развитые коммерческие текстовые процессоры. Что, впрочем, не означает, что они хоть в какой-то мере приблизились к туманному идеалу.
Хотя, справедливости ради, нужно заметить: такой цели - приблизиться к идеалу - перед этими продуктами создатели и не ставили. Ведь основное, я бы сказал - сакральное, предназначение коммерческих офисных приложений - облегчение не труда, а кошелька пользователя. Первейшая обязанность которого, как известно - постоянные upgrade аппаратуры в соответствие с требованиями нового софта...
Однако я отвлекся, пора перейти ко второй сфере применения текстовых процессоров. То есть обработке уже написанного. Обработка эта может быть двоякого рода - с точки зрения содержания и представления, что требует различных функций.
Обработка с точки зрения содержания требует средств редактирования - раз, и средств сравнения и контроля версий - два. Первая задача достаточно успешно решается, не выходя за рамки текстовых редакторов. Вторую, значение которой при коллективной работе трудно переоценить, теоретически также можно попробовать решить средствами текстовых редакторов, по крайней мере наиболее развитых. Однако это потребует дополнительных усилий - штатные средства такого рода в них мне неизвестны. И потому функции контроля и коллективной работы - это единственное, что хоть как-то примиряет меня с программными монстрами типа Word или WordPro. Благо самому этими средствами пользоваться почти не приходится...
Обработка с точки зрения оформления - понятие чрезвычайно обширное. С одной стороны, под него попадает несложное шрифтовое оформление и центрирование заголовков перед выводом на печать докладной записки, с другой - сложная верстка, вплоть до оригинал-макета для типографского воспроизведения. О первой крайности - чуть ниже, а вот для второй человечеством специально придуманы т.н. настольные издательские системы. Зато все промежуточные варианты обработки для представления - создание и ранжирование рубрик, составление оглавлений и предметных указателей, разметка иллюстративного и табличного материала - это именно и по преимуществу вотчина текстовых процессоров.
Наконец, сфера делопроизводства. Речь идет, разумеется, не о документообороте министерства или транснационального концерна. А о тех планах, отчетах, этапах, сметах, служебных записках, которые каждый из нас пишет но сто раз на дню и имя которым - легион. Ведь, как доказано практикой, повсеместное внедрение электронного документооборота привело к росту документооборота бумажного в геометрической прогрессии. Что понятно: раньше, чтобы напечатать бумагу в трех экземплярах, нужно было напрячься и каждый лист проложить копиркой, а сейчас - отправил на принтер хоть сто копий - "и сидишь себе, болтаешь ножками, сам сачкуешь, а она работает" (А.Галич).
Вот со сферы такого, с позволения сказать, локального, документооборота мы и начнем. Для чего рассмотрим
Текстовые редакторы для ОС UNIX
А. Фомичев andy@eagle.msk.su, Eagle Dynamics, Москва
17.04.1994
|
|
Известно, что программисты достаточно легко меняют язык программирования или даже операционную систему, но чрезвычайно редко и весьма неохотно меняют любимый текстовый редактор. Этот факт можно объяснить тем, что для любого разработчика текстовый редактор является непосредственной средой обитания, где готовятся тексты программ и документация, откуда осуществляетея взаимодействие с различными компонентами операционной системы (файловой системой, интерпретатором команд, процессами и т. п.). Пользователь настраивает эту среду в соответствии со своими требованиями и вкусами, со временем у него вырабатыеетея определенный стиль работы с редакторе, многие действия доводятся до полного аетоматизма. Поэтому любая перемена означает изменение привычек, а это никогда не проходит безболезненно. Зачастую первоначальный выбор редактора обусловлен лишь отсутетвием в текущий момент какой-либо альтернативы. Цель данной статьи - сориентироеать всех, кто недавно перешел в ОС UNIX из более дружественных" операционных систем и стоит на перепутье в выборе подходящих программных средств. Здесь будет сделан обзор как коммерческих текстовых редакторов, так и редакторов, предлагаемых бесплатно, в той или иной степени ориентированных на разработку программ. Постараюсь показать, что при веей ограниченности выбора альтернативы vi вее же есть!
В последнюю пару лет в России (что, впрочем, соответствует и общемировым тенденциям) можно наблюдать все более возрастающий интерес к операционной системе UNIX со стороны государственных служб, финансовых и управляющих структур (министерств, департаментов, ассоциаций, инспекций и т. д.), а также коммерческих организаций (банков, акционерных обществ, бирж и прочих). Всеобщая компьютеризация, похоже, из показухи переросла в насущную потребность, без которой стало практически невозможно успешно вести какие-либо дела внутри страны, не говоря уже о выходе на международный рынок. Прошли те времена, когда предприятию достаточно было приобрести пару-другую компьютеров типа IBM РС-286 и установить на них несколько программ для расчета зарплаты, учета складской продукции и т. п., состряпанные за пару месяцев умельцами, использующими незабвенный Clipper, dBase, Clarion или другие "подручные" средства. Сегодня признаком хорошего тона является наличие в организации нескольких UNIX-машин, объединенных в сеть, с установленным лицензионным программным обеспечением, стоимость которого, к слову, сравнима со стоимостью самого вычислительного оборудования. Такое положение дел может только радовать.
Причины возрастания популярности ОС UNIX, на мой взгляд, следующие. Во-первых, характер требующих решения задач (автоматизация офиса, банковской деятельности или производства, управление коммуникациями) диктует необходимость использования многопользовательской, многозадачной, сетевой и открытой для наращивания операционной системы. Наиболее развитой и распространенной операционной системой такого класса, безусловно, является UNIX. Во-вторых, за последние годы значительно снизились цены как на вычислительное оборудование, так и на сами операционные системы UNIX, с одновременным возрастанием их возможностей и производительности. Ну и, в-третьих, это, вероятно, дань моде - "чем я хуже?".
Зачастую можно наблюдать ситуацию, когда переход на платформу UNIX наконец-то осуществлен, штат имеется, цели вроде бы ясны, а вот со средствами достижения этих целей туговато. Пользователь, будь то программист, администратор или оператор по набору текстов, работавший раньше в MS-DOS и имевший в своем распоряжении несколько текстовых редакторов и программных сред на выбор, ощущает дискомфорт при общении с "недружественным" UNIX'ом из-за отсутствия в последнем подобного выбора. Имеющиеся средства (как правило, это уже морально устаревший редактор vi или, в лучшем случае, Emacs) оставляют желать лучшего, будучи недружелюбными, сложными в освоении, и, как иногда кажется, нелогичными, лично я не могу понять, почему, например, команда "l" в vi означает "курсор вправо". Получается, что "нормально" работать в UNIX могут только хакеры, которым, в принципе, ничего кроме vi и не надо ("vi жил, vi жив, vi будет жить"), а также те, кто прошел курс обучения vi или Emacs или нашел в себе мужество перекопать документацию для того, чтобы выяснить, например, что сохранить файл в Emacs можно, нажав Ctrl+X Ctrl+W. Невольно возникает вопрос: не лучше ли потратить время на изучение языка 4GL или освоение электронной банковской системы, чем на изнурительное изучение Emacs или vi, чья "криптография" не только поражает, но и подавляет!? Справедливости ради заметим, что в свое время Emacs сыграл свою роль мощного средства разработки, да и сейчас пользуется популярностью у большого числа программистов - поэтому не будем его категорично отвергать. Да и у нелюбимого мною (которому, кстати, исполнилось уже 16 лет) есть, по крайней мере, одно достоинство - он присутствует, наверное, в любой реализации UNIX и иногда оказывается единственным доступным средством.
Ну, а теперь перейдем от лирики к прагматике. На вопрос "Можно ли найти под UNIX'ом что-нибудь приличное в классе текстовых редакторов общего назначения?" я с полной ответственностью отвечаю: "Да, можно!". Сделаю оговорку: термином "текстовый редактор" я обозначаю программный продукт, ориентированный на подготовку текстов (писем, отчетов, исходных кодов программ) и работающий с файлами в стандартноформате ASCII, без вставки каких-либо специальных символов. В данной статье я сознательно не буду упоминать так называемые "текстовые процессоры" типа WordPerfect и "настольные издательские системы" типа FrameMaker, поскольку продукты этих категорий, во-первых, решают несколько другие задачи, а, во-вторых, значительно дороже текстовых редакторов. Кроме того, по скромному мнению автора, лучше и дешевле Макинтошей или персональных компьютеров IBM РС, оснащенных системой MS Windows, для настольных издательских целей еще ничего не придумано. Так зачем же стучаться в открытую дверь?!
Итак, все текстовые редакторы для UNIX можно условно разделить на три категории:
- редакторы, разработанные специально под ОС UNIX; редакторы, перенесенные в UNIX из других платформ;
- эмуляторы "родных" редакторов из других операционных систем.
При этом часть редакторов распространяется в исполняемом виде или в исходных кодах как продукт категории "public domain", то есть бесплатно. Преимущества использования продуктов "public domain" очевидны: экономия денег, возможность адаптации под свои требования. Но налицо и недостатки: практическое отсутствие печатной документации, какой-либо поддержки со стороны производителя, затрата человеческих ресурсов на адаптацию и сопровождение. Из данной статьи Вы узнаете, где можно приобрести как коммерческие текстовые редакторы, так и распространяемые свободно.
Тело документа
Тело документа Texinfo представляет собой смесь команд секционирования, используемых при печати (части TeX-публикации: главы, разделы, подразделы и т.д.) и команд группировки, используемых при просмотре на экране (собственно Info: узлы [nodes]). Теоретически, каждая из этих двух "ипостасей" может задавать свою структуру документа. Такая ситуация, однако, может изрядно обескуражить читателя, а это, вероятно, не входит в план написания технической документации.
Я изложу упрощенный подход к созданию тела документа, в котором структура он-лайновой и печатной версий максимально близки. Ценой незначительного ограничения возможностей навигации это избавляет пишущего от головной боли ручной разбивки документа для экранного просмотра. Упрощенная метода требует, чтобы структура информации в Info-версии соответствовала структуре печатной версии.
Структура Info определяется командами @node node-name, в то время как структура печатного документа задается -- среди прочего -- командами @chapter chapter-title, @section section-title и @subsection subsection-title. Команда @node всегда появляется первой. Вот некоторые примеры:
@node Введение @chapter Введение
или
@node Итеративные-процессы @section Итеративные процессы
или
@node Численная стабильность @subsection Численная стабильность итеративных алгоритмов
Аргумент команды @node присваевает узлу имя node-name. Имя состоит из одного или более слов. Пробелы в node-name вполне допустимы, но точка .'', запятая ,'', двоеточие :'' и апостроф ' -- запрещены. В имени узла также рекомендуется избегать команд (чего-либо, начинающегося с "@"). Имена узлов чувствительны к регистру. В документе Texinfo каждый узел должен иметь уникальное имя. Существует соглашение, по которому слова в именах узлов начинают с заглавной буквы, как это делается в именах глав и разделов (автор имеет в виду традицию англоязычной типографики, согласно которой все значимые слова -- существительные, прилагательные и глаголы, но не предлоги и артикли, пишут с заглавной буквы. прим. пер.).
Узел может либо содержать исключительно данные (а именно текст, таблицы, иллюстрации и перекрестные ссылки), либо узел должен определять меню навигации. Далее узлы "первого рода" я называю терминальными, а узлы второго рода -- узлами-меню.
Терминальные узлы
Структура терминального узла такова
@node имя-узла
@section заголовок-секции
текст-узла-главы
я воспользовался командой @section, как примером команды секционирования.
Терминальные узлы -- плоть документа. В них заключена вся информация, которая видна читателю. текст-узла-главы обычно содержит один или более абзацев, таблиц и т.д.
Узлы-меню
Узлы-меню обеспечивают "децентрализованные" оглавления (что уже является мета-информацией), из которых можно быстро "перескочить" к любому из перечисленных в меню разделов.
Структура узла-меню схожа с терминальным узлом за исключением того, что узел-меню заканчивается определением меню навигации. Меню навигации вставляется исключительно в Info-версию и никогда не появляется в печатной версии.
@node имя-узла
@chapter заголовок-главы
необязательный-вводный-текст-и-для-узла-и-для-главы
@menu
* Имя узла для первого раздела :: Синопсис первого раздела
* Имя узла для второго раздела :: Синопсис второго раздела
...
* Имя узла для последнего раздела :: Синопсис последнего раздела
@end menu
Меню навигации заключается "в скобки"
@menu
@end menu
и каждая строка между ними превращается в пункт меню. Каждый пункт должен начинаться с символа "звездочки" *'', за которым следует имя узла, на который этот пункт указывает [target node]. Далее идет двойное двоеточие ::'', а за ним может помещаться необязательное краткое описание "указУемого" раздела:
* Имя раздела :: Необязательное описание раздела
Корень документа Один узел-меню играет особую роль в каждом документе Texinfo: главный узел, которому "принадлежат" все остальные. Корень документа называется узлом Top и определяется двумя командами: @node Top
@top имя-корневого-узла
Поскольку корневой узел оказывается первым каждый раз, когда документ загружается для просмотра на экране (если нет явного указания начинать просмотр с какого-либо иного узла), то желательно включить в него вводный текст. Такой вводный текст обычно не годится для печатной версии. Не забыли, что в печатной версии вообще нет меню? Поэтому нам надо исключить вводный текст из печатной версии, что достигается с помощью команд условной трансляции: парных команд @ifinfo и @end ifinfo. Несложный корневой узел выглядит следующим образом:
@ifinfo
@node Top
@top Пример
Это пример документа Texinfo.
@end ifinfo
@menu
* Имя первой главы:: Синопсис первой главы
* Имя второй главы:: Синопсис второй главы
* Имя третьей главы:: Синопсис третьей главы
@end menu
Вот мы и готовы написать полный документ Texinfo.
\input texinfo @setfilename example.info @settitle Texinfo Example
@ifinfo @node Top @top Пример Это пример документа Texinfo. @end ifinfo
@menu * Введение:: Определения, Меры, Сложность * Исчисление полиномов:: Изучение обычных операций @end menu
@node Введение @chapter Введение В этой главе обсуждаются концепции, в дальнейшем используемые в разных частях этого документа. Более того, здесь вводятся мера эффективности и мера ограничения сложности.
@menu * Определения:: Основы * Меры эффективности:: Как измерять эффективность * Ограничения сложности:: Типичные ограничения сложности @end menu
@node Определения @section Определения ...
@node Меры эффективности @section Меры эффективности ...
@node Ограничения сложности @section Ограничения сложности ...
@node Исчисление полиномов @chapter Исчисление полиномов ... @bye
Терминология
GML (Generalized Markup Language) разработан в недрах вездесущей корпорации IBM. Его наследник SGML (Standard Generalized Markup Language) принят в 1986 году в качестве международного стандарта для определения независимых от устройств ввода/вывода, независимых от вычислительной среды методов представления текстов в электронной форме. Более точно, SGML -- это метаязык, то есть средство формального описания языка, в данном случае, языка разметки.
Исторически слово разметка использовалось для описаний аннотаций или других обозначений внутри текста, предназначенных для указаний составителю или "верстальщику" того, как именно конкретное место должно быть напечатано или сверстано. Примеры включают подчеркивание волнистой чертой, обозначающее курсив, специальные значки для пропуска фраз или их печати конкретным шрифтом, и так далее. Когда форматирование и печать текстов стали автоматизированными, этот термин стал охватывать все виды специальных кодов разметки, вставляемых в электронные тексты для управления форматированием, печатью или другой обработкой.
Обобщая, разметку, или кодировку, определяют как любое средство сделать явным интерпретацию текста. На банальном уровне все напечатанные тексты кодированы в этом смысле: знаки препинания, использование заглавных букв, расположение букв по странице, даже интервалы между словами можно считать в какой-то степени разметкой, функция которой -- помочь человеку, читающему текст, определить, где кончается одно слово и начинается другое, или как идентифицировать особенности структуры, такие как заголовки, или простые синтаксические единица вроде подчиненных предложений. Кодирование текста для компьютерной обработки, в принципе, как расшифровка манускрипта с пергамента, -- процесс делания явным неявного или подразумеваемого, процесс указания пользователю того, как должно интерпретироваться содержимое текста.
Под языком разметки понимают набор соглашений о разметке, применяемых для кодирования текстов. Язык разметки должен специфицировать, какая разметка допустима, какая разметка обязательна, как отличить разметку от текста и что разметка значит. SGML предоставляет решения для первых трех задач, отдельная документация обычно необходима для последней.
TeX
Необязательно
TeX (рифмуется с blech!) это популярный язык разметки, который используют многие люди, особенно в математическом мире. Я до сих пор помню многие Calculus экзамены, которые были написаны на TeX. Это также один из первых языков разметки, который до сих пор используется (другой это формат *roff используемый в man страницах). TeX следует концепциям схожим с SGML. Так ка TeX визуализирует свои файлы в DVI (Device Independent - "независящий от устройства") который может быть в свою очередь визуализирован в другой формат. К сожалению DVI не так то легко конвертировать во что-либо, кроме языков печати (PostScript,PCL),что делает сложным генерацию HTML. TeX устанавливается или доступен в большинстве дистрибутивов Линукс. TeX также прилагается практически ко всем дистрибьюциям как LaTeX или TeTex. Любой из них подойдет вам.
Text Fonts
Этому вопросу я всегда придавал первостепенное значение. Во-первых, из соображений эстетических (грешным делом, люблю красивые шрифты), во-вторых, по причине плохого зрения. Так вот, с точки зрения выбора экранных шрифтов NEdit заслуживает аплодисментов.
При вызове пункта Text Fonts возникает панель с предложением определить основную гарнитуру (по умолчанию - нормального, то есть не курсивного и не полужирного, начертания) и отдельно - гарнитуры для каждого из начертаний (опять же, курсивного, полужирного, и полужирного курсивного). Впрочем, можно нажать экранную клавишу Fill Highlight Fonts from Primary - и тогда все прочие, кроме нормального, начертания унаследуют его гарнитуру.
В строке Primary Font (как, впрочем, и в любой другой) определить гарнитуру (и прочие параметры) экранного шрифта можно вводом вручную, с указанием всех требуемых атрибутов. Однако проще нажать экранную клавишу Browse и выбрать из списка всех доступных системе шрифтов. Каковой осуществляется в панели о трех колонках; в них необходимо явным образом отметить все три доступные для выбора атрибута - Font (то есть гарнитуру), Style (начертание, но нашему) и Size (сиречь кегль), иначе последует сообщение о некорректном определении шрифта.
Что характерно (вернее, не характерно для большинства текстовых редакторов, оперирующих обычно только моноширинными гарнитурами): хотя по умолчанию в списке присутствуют моноширинные шрифты, можно включить также показ шрифтов пропорциональных, и использовать их в свое удовольствие.
Подчеркну, но таким образом можно определить шрифт только для экранного представления набираемого текста. На шрифты интерфейсных элементов, а также системы помощи это не окажет никакого воздействия. Разумеется, и они могут быть подобраны по вкусу, но об этом - несколько ниже.
Thomas Adam
Меня зовут Thomas Adam. Мне 18, и в настоящее время я готовлюсь к A-Levels (= вступительные экзамены в университет). Живу на маленькой ферме в округе Дорсет в Англии. Я большой энтузиаст Linux, и помогаю в школе со всеми делами, связанными с его повседневным использованием. Linux использую уже около шести лет. Когда я не работаю с Linux, то играю на пианино, люблю пешие прогулки и кататься на мотоцикле.
Типы документов
SGML вводит понятие типа документа, и, соответственно, определения типа документа
(document type definition, DTD). Документы считаются типизированными, так же, как и другие обрабатываемые компьютерами объекты. Тип документа формально определяется его составными частями и их структурой. Определение, например, отчета может быть таким, что он состоит из заголовка и, возможно, автора, за которыми следует аннотация и последовательность одного или более абзацев. Любой документ в отсутствие заголовка, в соответствии с этим формальным определением, не будет формально являться отчетом, так же как не будет им являться и последовательность абзацев, за которой следует аннотация, невзирая на то, насколько похож на отчет такой документ с точки зрения читателя-человека.
Поскольку документы относятся к известным типам, можно использовать специальную программу, называемую анализатором (parser), для того, чтобы обработать документ, утверждающий, что он относится к конкретному типу, и проверить, действительно ли все элементы, требуемые для данного типа документов, присутствуют и находятся в правильной последовательности. Что еще более важно, разные документы одного типа могут обрабатываться унифицированным образом. Можно писать более интеллектуальные программы, использующие знания, заключенные в информационной структуре документа.
Титульная страница
Сделать приличную титульную страницу легко. Команда @titlepage, а также дополнительные команды [sub-commands] @title, @subtitle (необязательно) и @author, берут на себя заботы о компановке титульной страницы. Если вы хотите, чтобы материал, следующий за титулом, располагался на нечетной странице -- нужно добавить разрыв страницы непосредственно после @end titlepage.
Пример:
@titlepage
@title Образец документа Texinfo
@subtitle Пробуем, как Texinfo форматирует текст
@author Joanne H. Acker
@page @c -- начинаем последующий текст с нечетной страницы
@end titlepage
Тэги корневого раздела [Root Section]
Эти теги определяют самый "внешний" элемент любого документа.
book
<book> I<абзацы или главы>
</book>
article
<article> I<абзацы или разделы первого уровня [level 1 sections]>
</article>
Тэги, образующие списки [List-Making Tags]
Создают списки трех обычных типов.
Пункты списка [items] и определения [definitions] обычно образуются из одного или более абзацев, но могут содержать и листинги программ. Термины [terms] обычно состоят из одного или более слов, но не абзацев.
Неупорядоченный список [Itemized List]
<itemizedlist>
<listitem>
Первый элемент списка
</listitem>
<listitem>
Второй элемент списка
</listitem>
...
</itemizedlist>
Нумерованный список [Enumerated List]
<enumeratedlist>
<listitem>
Первый пункт
</listitem>
<listitem>
Второй пункт
</listitem>
...
</enumeratedlist>
Список описаний/определений [Description List]
<variablelist>
<varlistentry>
<term>первый термин </term>
<listitem>
первое определение
</listitem>
</varlistentry>
<varlistentry>
<term>второй термин</term>
<listitem>
второе определение
</listitem>
</varlistentry>
...
</variablelist>
Тэги прямого форматирования [Inline Markup Tags]
emphasis (выделение)
<emphasis>выделяемый текст</emphasis>
Делает небольшую часть документа, обычно -- единичное слово, выделяющейся на фоне окружающего текста.
filename (имя файла)
<filename>имя файла или каталога</filename>
Слово оформляется, как имя файла.
literal
<literal>литерал</literal>
<literal role = "классификатор">что-либо, передаваемое буквально, без обработки</literal>
Помечает слово, как литеральное выражение (т.е. выражение, не обрабатываемое транлятором, а передаваемое "на выход" в неизмененном виде). Используйте этот тэг в лишь в самом крайнем случае, когда не годится ни один из более конкретных тэгов. Для того, чтобы успокоить нечистую совесть, literal часто дополняется атрибутом role, который более точно описывает, что он собой прествавляет.
replaceable (заменяемое)
<replaceable>замещающее имя</replaceable>
Помечает мета-переменную.
title (заголовок)
<title>заголовок</title>
Содержит имя раздела или другого формального элемента, например таблицы.
