Алгебра и исчисление
.
Реляционное исчисление (РИ), как и реляционная алгебра, есть абстрактный язык манипулирования реляционными данными.
РА и РИ эквивалентны в том смысле, что для любого допустимого выражения РА можно построить формулу РИ, производящую такой же результат, и наоборот. В связи с этим возникает вопрос: зачем включать в РМД и алгебру, и исчисление? Ответ кроется в разном уровне процедурности
этих механизмов.
РА представляет в явном виде набор операций, которые можно использовать для вычисления необходимого результата. Выражения реляционной алгебры имеют процедурную интерпретацию. Они сообщают системе, как из базовых отношений построить требуемое производное отношение. Оно может быть вычислено в соответствии с определениями элементарных алгебраических операций, с учетом их старшинства и возможных скобок.
В отличие от РА, РИ есть просто система обозначений для определения производного отношения в терминах других отношений. Для формул РИ процедурной интерпретации нет. Они декларативны. Формула просто определяет условия, которым должны удовлетворять кортежи результирующего отношения, – требуемые данные[25].
Например, запрос: «Получить имена поставщиков, поставляющих деталь Р2» в терминах алгебры имеет вид:
(( SPJ JOIN S) WHERE P# = ‘P2’)[Sn];
и описывает следующую процедуру:
· построить естественное соединение SPJ
и J по атрибуту S#;
· выбрать из результата кортежи, в которых P# = ‘P2’;
· выполнить проекцию результата на атрибут Sn.
Однако можно и не указывать, какие соединения, проекции и селекции строить. Можно сформулировать на некотором формальном языке фразу следующего содержания:
«Получить значения атрибута Sn для таких поставщиков, для которых в SPJ
существуют кортежи с тем же значением атрибута S# и со значением атрибута P# = ‘P2’.»
Подобной фразой можно точно указать системе характеристики интересующего нас отношения. Пусть она сама решает, какие вычисления нужно проделать для того, чтобы получить его.
Формальный язык для точной записи подобных высказываний называется реляционным исчислением. Его основой является исчисление предикатов первого порядка.
Современная РМД располагает двумя вариантами реляционных исчислений. В одном из них областями возможных значений переменных являются отношения (РИ с переменными-кортежами), а в другом – домены (РИ с переменными на доменах). Оба РИ, как и РА, обладают свойством замкнутости относительно множества отношений. То есть формулы РИ определяются над отношениями и интерпретируются как отношения. Это дает возможность строить вложенные формулы, выражая ими очень сложные запросы к реляционной БД.
Аномалия обновления значений
. Если обновляются значения атрибутов, функционально зависящих от части ПК или от неключевых атрибутов, то система не может проверить эти ФЗ, так как их невозможно объявить. Поэтому она не заметит, что поставщик из Яи «приобрел» запрещенный статус. Будут пропущены также ошибки при обновлении значений поля Jn
или Sn и т.п.
3.2.3
Аномалия вставки типа а)
. Если А ® В, то всякий раз, как встретится конкретное значение А, должно встретиться соответствующее ему значение В. Если при этом А не является возможным ключом отношения, то нет никаких ограничений на число кортежей с конкретным значением А и соответствующим ему значением В. Этим и обусловлено избыточное дублирование.
Для того чтобы система могла блокировать ввод ошибочных значений B, она должна знать о наличии ФЗ А ® В. Но если A не является возможным ключом, мы не можем объявить ФЗ А ®
В. Поэтому система не может запретить ввод значения B, не соответствующего этой ФЗ.
В нашем примере универсального отношения атрибут S# не является возможным ключом. Связанная с этим аномалия вставки типа а) обусловлена тем, что нет никакой возможности объявить ФЗ S# ® Sn, S# ® St, S# ® Sci, Sci ® St.
Аномалия вставки типа б)
. Она обусловлена тем, что вставляемые значения функционально зависят от части первичного ключа (ПК).
Для того чтобы добавить в БД сведения о новом поставщике, достаточно указать значение S#
и проверить ФЗ S# ® Sn, S# ® St, S# ® Sci, Sci ® St. Но S# – только часть ПК универсального отношения и эти ФЗ мы не можем объявить. Вставляя кортеж в универсальное отношение, нужно указать определенные значения всех атрибутов первичного ключа и проверить все объявленные таким образом ФЗ. Однако среди них нет интересующих нас зависимостей S# ® Sn, S# ® St, S# ® Sci, Sci ® St. Поэтому, даже если мы присвоим атрибутам P#, J#, Dt
какие-то значения «по умолчанию» и формально обеспечим возможность вставки кортежа, целостность данных не гарантирована.
Таким образом, аномалии обновления типа б) обусловлены тем, что в схеме отношения имеются атрибуты, функционально зависящие от части первичного ключа.
База данных
. Модель ПО реализуется в базе данных в виде конкретных наборов значений свойств объектов и указателей связей между экземплярами объектов. На концептуальном уровне можно представлять БД как коллекцию экземпляров записей. Типы записей соответствуют объектам ПО, поля записей – свойствам объектов, экземпляры записей – экземплярам объектов[2].
Предметная область как часть реального мира изменяется во времени. Появляются и исчезают экземпляры объектов, изменяются значения их свойств, возникают и разрушаются экземпляры связей. Могут возникать новые объекты и исчезать имевшиеся. Все эти изменения должны отражаться в информационной модели ПО. Модель должна быть динамической, т.е. отражающей текущее состояние ПО.
База данных
есть динамическая информационная модель своей ПО, адекватно отражающая ее состояние в любой момент времени.
Эта модель используется бизнесом для принятия оперативных решений, анализа эффективности деятельности, определения стратегии и т.д.
База данных «Поставщик-Деталь-Изделие»
. Наша БД хранит сведения о ПОСТАВЩИКах, поставляемых ими ДЕТАЛях, ИЗДЕЛИях, для которых поставляются ДЕТАЛи и ПОСТАВКАх, выполненных ПОСТАВЩИКами. Данные размещены в четырех отношениях. Концептуальная схема БД приведена на рис. 2.3.
Прямоугольники представляют схемы отношений, дуги – связи отношений, имена над прямоугольниками – названия объектов ПО или фактов. В прямоугольники вписаны имена атрибутов – характеристик объектов. Символы в квадратных скобках – псевдонимы атрибутов, введенные для удобства ссылок.[14]
Диаграмма отражает логические взаимосвязи данных, обусловленные требованиями ПО. Однако, если ограничиться только определениями отношений, то в нашу БД можно будет уложить что угодно. Значения атрибутов должны удовлетворять некоторым ограничениям. Эти ограничения задаются действующими в ПО правилами (бизнес-правилами).
 |
Рис. 2.3 База данных «Поставщик – Деталь – Изделие» (S-P-J)
Бизнес-правила и ограничения целостности
. Пусть в нашей ПО действуют следующие правила:
· номер поставщика уникален;
· номер изделия уникален;
· номер вида детали уникален;
· номер поставщика должен иметь вид ‘Sх’, где х любая последовательность цифр;
· номер вида изделия должен иметь вид ‘Jх’, где х любая последовательность цифр;
· номер вида детали должен иметь вид ‘Pх’, где х любая последовательность цифр;
· значение статуса поставщика может быть только целым, кратным 5 в диапазоне 5 ¸100;
· цвет детали должен выбираться из определенного списка;
· названия городов должны выбираться из определенного списка;
· красные детали хранятся только в Яе;
· если город поставщика Яя, то его статус 50;
· конкретный поставщик может в течение одного дня поставить конкретную деталь для конкретного изделия только однажды;
· количество деталей в одной поставке не может быть меньше 100 или больше 1000;
· месячный объем поставки любой детали не может превосходить 10000.
Если в нашей БД есть, например, кортеж {(номер поставщика, ‘S1’), (название поставщика, ‘Рога и копыта’), (статус, 100), (город размещения, ‘Черноморск’)}[15], то он имеет вполне осмысленную интерпретацию в терминах ПО, если значение S# = ‘S1’ встречается только в этом кортеже и Черноморск включен в список городов. Если такого названия нет в списке, то и кортеж осмысленной интерпретации не имеет.
Если мы просуммируем значения поля Qt во всех строках таблицы SPJ, в которых значение P# = ‘P1’, а значения дат лежат в интервале от 01.03.98 до 31.03.98, и увидим, что эта сумма больше 10000, то либо наши данные ошибочны (этого не должно быть по правилам), либо кто-то из служащих нарушил правила.
Подобных правил в любой ПО очень много. Они подчас бывают очень сложными и действуют независимо от способа хранения данных – на бумаге, на диске, … Если они соблюдаются, то гарантирована интерпретируемость данных. Как все правила, они формальны. Их можно сформулировать в виде предикатов и реализовать алгоритмы вычисления значений этих предикатов на текущих значениях хранимых данных.
Иными словами, существует принципиальная возможность
автоматической проверки правил целостности данных.
Проверить истинность данных автомат не может. Интерпретируемый кортеж {‘S1’, ‘Рога и копыта’, 100, ‘Черноморск’}
может вводить в заблуждение, если не существует в Черноморске фирмы с таким названием.
Целостность
данных и адекватность данных – не одно и то же. Данные могут быть целостными, но при этом не соответствующими действительности. Обеспечение адекватности – проблема пользователя, поддержание целостности может быть проблемой СУБД.
Правила, о которых мы только что говорили, являются специфическими в том смысле, что они применяются к одной конкретной БД. Их называют внешними
ограничениями целостности (ОЦ) данных.
Внешние ОЦ
– это обусловленные требованиями конкретной ПО правила, соблюдение которых обеспечивает интерпретируемость хранимых данных.
Замечание 4.
Поддержание правил бизнеса, которые отображены в БД как правила целостности данных, – обязанность младшего и среднего звена администрации предприятия. Поэтому одна из важнейших задач проектировщика БД – выявить все бизнес-правила и максимально полно представить их в системе. Только при этом условии проект будет действительно полезным.
Все БД, основанные на РМД, кроме специфических правил (внешних ОЦ), подчиняются еще общим
правилам целостности. Эти правила называются внутренними ОЦ РМД. Однако, прежде чем обсуждать их, введем важнейшие понятия возможного, первичного и внешнего ключей отношения.
Целостность сущности
. Правило целостности сущности часто формулируют как требование уникальности значений первичного ключа. Однако, на самом деле это не так. Требование целостности сущности состоит в том, что каждый кортеж любого отношения должен быть идентифицируем. Иначе говоря, в БД не должна храниться информация о чем-то таком, что мы не можем идентифицировать.
Это требование связано с проблемой представления незнания в БД. В реальной жизни в базу данных нередко приходится включать кортежи, содержащие неизвестные значения некоторых атрибутов.
Например:
· поставщик зарегистрирован, а статус его еще не определен;
· руководство фирмы еще не решило, в каком городе разместить производство изделия;
· известна дата смерти исторического деятеля, а дата рождения затерялась в глубине веков и т.п.
В подобных случаях соответствующим атрибутам присваиваются так называемые Null-значения.
Null
– это специальный маркер, показывающий, что значение данного атрибута в настоящий момент неизвестно и, возможно, будет введено впоследствии. Null не «ноль», не «пробел», и вообще, Null не имеет типа. Этим маркером может быть помечен любой атрибут любого кортежа.
Null
обладает следующими свойствами:
· всякое сравнение с участием Null
дает результат Null;
· все Null-значения различны;
· отрицание Null – тоже Null.
Если какой-либо из атрибутов, входящих в состав первичного ключа отношения, принял значение Null, то представленный этим кортежем экземпляр объекта ПО невозможно идентифицировать. Очевидно, нет смысла хранить в БД такую комбинацию значений.
В самом деле, что означает утверждение: «номер поставщика неизвестен»? Мы еще не присвоили ему номер? Мы не знаем, присвоен ему номер или нет? Нам неизвестно, идет ли речь об уже зарегистрированном в БД поставщике или о каком-то другом? И т.д.
Во всех случаях, прежде чем заносить
информацию в БД, необходимо идентифицировать эту информацию, т.е. задать определенное значение первичного ключа. Если допустить возможность неопределенных значений первичного ключа, то будет разрушен механизм адресации РМД.
Правило целостности сущности: ни один компонент первичного ключа отношения не может принимать неопределенное значение.
Это, как и требование целостности домена, метаправило. Оно означает, что в схеме конкретной РБД должны быть определены первичные ключи всех отношений. Тогда РСУБД не допустит появления кортежей с Null-значениями соответствующих атрибутов.
Декомпозиция универсального отношения
. Очевидный выход, избавляющий от избыточного дублирования данных, состоит в расщеплении (декомпозиции) отношения USPJ на четыре взаимосвязанных отношения – S, P, J, SPJ. Каждое из этих отношений является проекцией USPJ
на соответствующие группы атрибутов[27]:
S = (USPJ[S#, Sn, St, Sci]) RENAME SCi AS Ci;
P = (USPJ[P#, Pn, Co, We, PCi]) RENAME Pci AS Ci;
J = (USPJ[J#, Jn, Jci]) RENAME Jci AS Ci;
SPJ = USPJ[S#, P#, J#, Dt, Qt];
Ниже приведены значения этих отношений для рассматриваемого примера.
| S | P | ||||||||||||||||||
| S# | Sn | St | Ci | P# | Pn | Co | We | Ci | |||||||||||
| S1 | Иван | 50 | Яя | P3 | шайба | Ж | 20 | Ош | |||||||||||
| S2 | Петр | 100 | Ош | , | P1 | гайка | К | 10 | Яя , | ||||||||||
| S3 | Джон | 50 | Яя | P8 | болт | Ч | 30 | Яя | |||||||||||
| S8 | Боб | 50 | Томск | P2 | винт | С | 40 | Ош |
| J | SPJ | ||||||||||||||
| J# | ... | S# | P# | J# | Qt | Dt | |||||||||
| J1 | ... | , | S1 | P3 | J1 | 1000 | ... | ||||||||
| J2 | ... | S1 | P1 | J1 | 1000 | ... | |||||||||
| S1 | P8 | J1 | 500 | ... | |||||||||||
| S2 | P3 | J2 | 1000 | ... , | |||||||||||
| S3 | P2 | J2 | 2000 | ... | |||||||||||
| S3 | P1 | J2 | 1000 | ... | |||||||||||
| S8 | P8 | J2 | 500 | … |
Нетрудно убедиться в том, что в этих отношениях сохранены все отмеченные ФЗ. Естественное соединение этих проекций
USPJ = (((((SPJ JOIN S) RENAME Ci AS Sci)
JOIN P) RENAME Ci AS Pci)
JOIN J) RENAME Ci AS Jci;
восстановит универсальное отношение без всяких потерь информации. Кроме того, в этой структуре объявлены все ФЗ, за исключением S.Ci ® St.
Здесь нет аномалий удаления. Из отношения SPJ
можно удалять кортежи без проблем. При удалении кортежей других отношений достаточно соблюдать правила ссылочной целостности, которые объявлены определениями отношений (см. п. 2.4.2). Нет также аномалий вставки типа б).
Сведения о непоставлявших поставщиках, непоставлявшихся деталях и о не получавших поставок изделиях можно заносить в соответствующие отношения.
Аномалии вставки типа а) и обновления значений сохраняются для отношения S. Это обусловлено наличием необъявленной ФЗ между неключевыми атрибутами S.Ci ® St.
Можно попытаться избавиться от цепочки транзитивных зависимостей S# ® Ci ® St, заменив S его проекциями. При этом не должны быть потеряны ФЗ, и естественное соединение проекций должно восстанавливать исходное отношение. Для иллюстрации проблем, которые здесь могут возникнуть, рассмотрим возможные варианты декомпозиции.
Вариант 1.
SST= S[S#, Sn, St]; CS=S[S#, Ci];
Эти проекции для реализации USPJ, приведенной в п. 3.1.2, имеют вид:
|
SST |
CS |
||||
|
S# |
Sn |
St |
|
S# |
Ci |
|
S1 |
Иван |
50 |
; |
S1 |
Яя |
|
S2 |
Петр |
100 |
S2 |
Ош |
|
|
S3 |
Джон |
50 |
S3 |
Яя |
|
|
S8 |
Боб |
50 |
S8 |
Томск |
|
SST JOIN CS |
|||
|
S# |
Sn |
St |
Ci |
|
S1 |
Иван |
50 |
Яя |
|
S2 |
Петр |
100 |
Ош |
|
S3 |
Джон |
50 |
Яя |
|
S8 |
Боб |
50 |
Томск |
Здесь сохранены ФЗ S# ® Сi, S# ® St, S# ® Sn. Однако зависимость Ci ® St утрачена. Значения атрибутов Ci и St в проекциях можно менять независимо.
Вариант 2.
SST = S[S#, Sn, St]; STC = S[St, Ci];
Это плохой вариант. Здесь утеряна зависимость S# ® Ci. Поэтому возможна потеря информации при восстановлении исходного отношения. В самом деле, эти проекции имеют вид:
|
SST |
STC |
||||
|
S# |
Sn |
St |
|
St |
Ci |
|
S1 |
Иван |
50 |
50 |
Яя |
|
|
S2 |
Петр |
100 |
100 |
Ош |
|
|
S3 |
Джон |
50 |
50 |
Томск |
|
|
S8 |
Боб |
50 |
|
SST JOIN STC |
|||
|
S# |
Sn |
St |
Ci |
|
S1 |
Иван |
50 |
Яя |
|
S2 |
Петр |
100 |
Ош |
|
S3 |
Джон |
50 |
Яя |
|
S1 |
Иван |
50 |
Томск |
|
S3 |
Джон |
50 |
Томск |
Это совсем не похоже на исходное отношение. Мало того, что в нем появились ложные кортежи. Атрибут S#
утратил свойство потенциального ключа. Это следствие того, что общие атрибуты отношений STS, STC не являются их потенциальными ключами.
Вариант 3.
SC = S[S#, Sn, Ci]; CS=S[Ci, St];
Эти проекции имеют вид:
|
SC |
CS |
||||
|
S# |
Sn |
Ci |
|
St |
Ci |
|
S1 |
Иван |
Яя |
50 |
Яя |
|
|
S2 |
Петр |
Ош |
100 |
Ош |
|
|
S3 |
Джон |
Яя |
50 |
Томск |
|
|
S8 |
Боб |
Томск |
Естественное соединение SC и CS будет происходить без потерь информации, то есть в результате соединения не появятся кортежи, которых не было в исходном отношении. Это следствие того, что Ci – общий атрибут SC и CS, является потенциальным ключом CS. Каждому значению Ci соответствует единственный кортеж CS, который будет при соединении сливаться с соответствующими кортежами SC и образовывать, таким образом, только те кортежи, которые его породили при выполнении проекции S[Ci, St].
Дополнения к модели
Дополнения к модели
Диаграммы модели сопровождаются дополнительными материалами, уточняющими и поясняющими ее смысл. Имеется два вида дополнений: глоссарий и примечания.
Глоссарий
является обязательным дополнением. Он содержит описания отдельных диаграмм модели и определения сущностей, атрибутов и доменов.
Обязательные компоненты глоссария:
· имена – уникальные, осмысленные и соответствующие природе ПО наименования сущностей, атрибутов и доменов;
· определения – краткие, точные, однозначные тексты, обеспечивающие правильное понимание смысла имен, одинаковое для любого читателя.
Определение должно быть одинаково применимо в любом контексте, в котором встречается имя.
Кроме того, глоссарий может содержать список псевдонимов. Каждому имени могут соответствовать в различных контекстах псевдонимы. Необходимость их использования обусловлена тем, что в различных частях моделируемой ПО может использоваться разная терминология. Поэтому одни и те же вещи могут называться разными именами. Полный список псевдонимов должен сопровождать каждое имя.
Примечания
– это необязательный вид дополнений. Они могут пояснять смысл диаграмм и их элементов, содержать описания путей связей, сообщать о функциях, связанных с тем или иным объектом и т.п.
Примечания нумеруются числами натурального ряда. На диаграмме ссылка на примечание помещается около соответствующего объекта в круглых скобках.
Дополнительные реляционные операции
.
Определенные к настоящему моменту операции обеспечивают манипуляции кортежами, но не дают никаких средств для работы со скалярами, а это часто бывает необходимо.
Например, могут понадобиться сведения о весах поставок. Их можно получить из отношения (SPJ JOIN P)[SPJ#, We, Qt], вычислив для каждого кортежа значение We*Qt. Однако имеющимися средствами невозможно получить производное отношение со схемой {SPJ#, Tot_We}, где Tot_We
принимает значения выражения We*Qt.
Это пример «горизонтальных вычислений», т.е. комбинирования значений атрибутов из текущего кортежа отношения-операнда. В процессе анализа данных часто нужно комбинировать значения атрибута в различных кортежах – проводить «вертикальные» вычисления.
Например, для создания отчета о поставках может понадобиться отношение, содержащее номера поставщиков, номера поставляемых ими деталей и общие объемы поставок этих деталей, выполненных этими поставщиками. Чтобы получить такое отношение, нужно:
·
сгруппировать кортежи отношения SPJ по значениям подмножества атрибута {S#, P#};
· сформировать отношение со схемой {S#, P#, Tot_Qt}, где Tot_Qt принимает для каждого значения {S#, P#} единственное значение, равное сумме значений атрибута Qt во всех кортежах группы.
Определенные ниже операции производят отношения, содержащие результаты «горизонтальных» и «вертикальных» вычислений.
Доступ к данным в трехуровневой архитектуре
. Реализация изложенной архитектурной концепции вовсе необязательно явно
включает все три уровня. Однако в любой реализации ПП получают доступ к хранимым данным только через посредство СУБД. Для примера рассмотрим схему алгоритма выполнения операции чтения данных прикладной программой [9] (рис. 1.7).
 |
Рис. 1.7 Доступ к данным в СБД
Шаг 1. ПП обращается к СУБД с запросом на чтение записи внешней модели.
Шаг 2. СУБД, используя схемы ВМД и КМД и описание отображения внешний « концептуальный, определяет, какие записи КМД необходимы для формирования требуемой записи ВМД.
Шаг 3.
СУБД, используя схемы КМД и ВНМД и описание отображения концептуальный «
внутренний, определяет, какие записи внутренней модели необходимы для формирования затребованных записей КМД и совокупность физических записей, которые должны быть для этого считаны с физического носителя.
Шаг 4.
СУБД выдает ОС запрос на считывание в свои буферы необходимых записей физической базы данных (ФБД).
Шаг 5.
ОС считывает затребованные записи и помещает их в системные буферы СУБД.
Шаг 6. На основании имеющихся схем моделей и описаний отображений СУБД формирует в своем буфере затребованную внешнюю запись.
Шаг 7. СУБД пересылает сформированную внешнюю запись в рабочую область (РО) ПП.
Шаг 8. СУБД передает в ПП сообщение о результатах выполнения запроса.
Процедура записи данных из ПП в ФБД выполняется аналогично.
Естественное соединение
. Существует несколько разновидностей операции соединения отношений. Наиболее важный для практики вид – естественное соединение или просто соединение.
Эта операция применяется к отношениям, схемы которых имеют одноименные
атрибуты, определенные на общем
домене, т.е. к отношениям с пересекающимися
схемами.
Результатом является отношение, схема которого есть теоретико-множественное объединение схем операндов, а тело составлено из теоретико-множественных объединений таких кортежей операндов, в которых значения одноименных атрибутов совпадают.
Пусть X, Y, Z
– подмножества атрибутов, а R1
и R2 – отношения со схемами R1(X, Y) и R2(Y, Z), соответственно. Естественным соединением этих отношений называется отношение R = R1 Ä R2, имеющее схему R(X, Y, Z) и тело, образованное всеми кортежами {X:x, Y:y, Z:z}
такими, что в R1
существует кортеж {X:x, Y:y} и в R2 – кортеж {Y:y, Z:z}.
Пример 1.
| А | В | С | B | D | E | A | B | C | D | E | |||||||||||||||||||
| a | b | c | b | c | d | a | b | c | c | d | |||||||||||||||||||
| R1 = | d | e | c | , R2 = | b | c | e | , R = R1 Ä R2 = | a | b | c | c | e | . | |||||||||||||||
| b | b | f | a | d | b | b | b | f | c | d | |||||||||||||||||||
| c | a | d | b | b | f | c | e | ||||||||||||||||||||||
| c | a | d | d | b |
Пример 2.
| А | В | С | B | C | E | A | B | C | E | ||||||||||||||||||
| a | b | c | b | c | d | a | b | c | d | ||||||||||||||||||
| R1 = | d | e | c | , R2 = | b | c | e | , R = R1 Ä R2 = | a | b | c | e | . | ||||||||||||||
| b | b | f | a | d | b | c | a | d | b | ||||||||||||||||||
| c | a | d | |||||||||||||||||||||||||
Формализованное описание задачи
.
Цель: документирование результатов начального анализа требований ПО. Формирование общих представлений об информационных потребностях ПО.
Задача:
оформление результатов обследования ПО в виде текстового документа, содержащего:
·
наименование задачи;
· формулировку цели деятельности;
· перечень выполняемых функций с указанием субъектов;
· перечень правил бизнеса;
· перечень хранимых данных;
· перечень предполагаемых пользователей системы.
Этап 2. Определение сущностей и связей.
Цель: документирование сведений об основных сущностях ПО и характере взаимосвязей между ними.
Задачи: построение ER-диаграммы и глоссария к ней.
Перечень выходной документации:
· диаграмма ER-уровня модели;
· глоссарий (таблица).
Последовательность действий:
· выделить основные сущности и присвоить им уникальные имена;
· занести в глоссарий модели формальные определения имен сущностей;
· определить и поименовать связи между сущностями;
· построить ER-диаграмму;
· согласовать диаграмму и глоссарий с экспертами.
Этап 3. Определение семантики связей.
Цель:
документирование сведений об идентификаторах экземпляров сущностей и уяснение логики взаимосвязей сущностей на уровне идентификаторов.
Задачи:
построение диаграммы уровня ключей (KB-диаграммы) и глоссария к ней.
Перечень выходной документации:
· диаграмма KB-уровня модели;
· глоссарий (таблицы).
Последовательность действий:
· преобразовать все неспецифические связи в специфические;
· поименовать ассоциативные сущности и внести формальные определения имен в глоссарий;
· определить возможные ключи независимых сущностей и выделить первичные ключи;
· внести формальные определения имен ключевых атрибутов в глоссарий;
· показать первичные и все возможные ключи на диаграмме;
· определить типы связей и показать на диаграмме переданные ими внешние ключи;
· определить первичные и все возможные ключи зависимых сущностей и показать их на диаграмме;
· указать на диаграмме кардинальности всех связей со стороны потомков;
· показать необязательные неидентифицирующие связи;
· указать дискриминаторы кластеров категорий;
· согласовать диаграмму и глоссарий с экспертами;
· уточнить список хранимых атрибутов.
Этап 4. Определение состава атрибутов сущностей.
Цель:
документирование сведений о хранимых атрибутах.
Задачи:
построение полноатрибутной диаграммы (FA-диаграммы) и глоссария к ней.
Перечень выходной документации:
· диаграмма FA-уровня модели;
· глоссарий (таблицы).
Последовательность действий:
· дать формальные определения имен неключевых атрибутов;
· разместить неключевые атрибуты на диаграмме в соответствии с их смыслом;
· проверить условия 3НФ для каждого сущностного отношения и при необходимости выполнить нормализацию структуры;
· окончательно согласовать модель с экспертами.
Формальный подход
включает два этапа моделирования:
· анализ ПО с целью выявления полного перечня хранимых атрибутов и правил бизнеса;
· нормализация универсального отношения до требуемого уровня.
Результатами анализа являются определения схемы универсального отношения и множества межатрибутных ФЗ, существующих в нем. Результат нормализации – система отношений, связанных по типу «родитель – потомок» или «супертип – категория». Выполняя нормализацию, обычно стремятся строить такие проекции универсального отношения, которые можно интерпретировать как объекты ПО или факты связи объектов.
Основной недостаток формального подхода состоит в том, что он требует проведения детального анализа ПО до начала проектирования логического макета БД. Поэтому методики, основанные на формальном подходе, мало пригодны для решения сложных задач.
Функциональная зависимость атрибутов
Функциональная зависимость атрибутов
3.2.1 Основные определения.
Определение 1.
Пусть R некоторое отношение, А, В
– подмножества его атрибутов. Говорят, что А
функционально определяет В (или В
функционально зависит от А), если и только если для любого допустимого значения R каждому значению А соответствует точно одно значение В. Функциональную зависимость (ФЗ) принято обозначать А ® В.
Иными словами, если А ® В, то для любого допустимого значения R
два кортежа, совпадающие по значению А, совпадают также и по значению В. Обратное, вообще говоря, неверно. Подмножество А называют детерминантом
зависимости, подмножество В – зависимой частью.
Функциональные зависимости есть связи типа 1:М между подмножествами атрибутов. Они определяются смыслом данных и правилами бизнеса. Наличие ФЗ невозможно установить по результатам анализа значения отношения.
Так, в приведенном выше примере (см. п. 3.1.2) дважды встречающемуся значению
P# = ‘P1’ соответствует одно и то же значение Qt = 1000. Аналогичное соответствие наблюдается и для P# = ‘P3’и P# = ‘P8’. Однако из этих фактов нельзя сделать вывод о существовании ФЗ {P#} ® {Qt}[26]. Возможно, это случайность. Однако, если ПО действительно накладывает ограничения на разовые объемы поставок конкретных видов деталей, то есть и отмеченная ФЗ.
Зависимости S# ® St, S# ® Sci, Sci ® St действительно существуют. По правилам ПО конкретный поставщик расположен в единственном городе, имеет единственный статус, и всем поставщикам, расположенным в одном городе, присваивается один и тот же статус.
Определение 2.
Атрибуты А1, А2, ... , Аn
называются взаимно независимыми, если ни один из них не зависит функционально от какого-либо подмножества остальных.
Например, атрибуты We, Qt, S#, Jn взаимно независимы. Правила бизнеса не обусловливают каких-либо зависимостей между ними или их комбинациями.
Пусть R – некоторое отношение, А, В, С – подмножества его атрибутов. Если А ®
В, В ®
С, то А ® С. В таком случае говорят, что существует транзитивная
функциональная зависимость (С транзитивно зависит от А, А ® В ®
С).
В универсальном отношении USPJ существует транзитивная ФЗ S# ® SСi ® St, следующая из S# ® SCi, SСi ® St.
Определение 3. Пусть A и B – подмножества атрибутов и A – детерминант B. Говорят, что ФЗ A ® B
неприводима, если не существует такого подмножества C Ì
A, что C ® B.
Например, существующая в USPJ ФЗ {S#, P#, J#, Dt} ® Qt неприводима, а зависимость {S#, P#, J#, Dt} ® Jn следует из J# ® Jn, т.е. неприводимой не является.
ФЗ в декомпозированной структуре
. В структуре БД, состоящей из отношений SC, P, J, SPJ, CS объявлены[28] следующие ФЗ:
| S# ® Sn; | P# ® Pn; | J# ® Jn; | A ® Qt; | S.Ci ® St. | |||||
| S# ® St; | P# ® We; | J# ® J.Ci; | |||||||
| S# ® S.Сi; | P# ® Co; | ||||||||
| P# ® P.Ci; |
Из них выводятся все остальные ФЗ, указанные в п.11.3.1. Например, поскольку атрибут S#
принадлежит множеству A
и является детерминантом ФЗ S# ® S.Сi, то A ® S.Ci.
Во всех отношениях этой структуры имеются только объявленные ФЗ. Именно, каждый неключевой атрибут любого отношения функционально зависит только от полного возможного ключа. Аномалии обновления данных в этой структуре невозможны.
Характеристика процесса проектирования
. Процесс проектирования БД включает три основных этапа:
·
проектирование концептуальной модели (логического макета БД);
· проектирование внутренней модели (физического макета);
· проектирование внешних моделей (локальных представлений данных для различных конечных пользователей).
Проектированию предшествует этап анализа ПО. Цель анализа – установить, какие данные должны храниться в БД, как эти данные взаимосвязаны и какие ограничения на них накладываются правилами бизнеса.
На первом этапе выбирается подходящая логическая структура для некоторого набора данных, которые должны храниться в БД. Здесь принимаются решения о том, какие базовые отношения и с какими атрибутами (схемами) следует создать и поддерживать. При этом учитываются только требования ПО. Никакие соображения реализации и аспекты использования данных не принимаются во внимание.
На втором этапе проектируются хранимые файлы, в которых будут размещаться базовые отношения, процедуры поддержания целостности, принимаются решения о том, какие нужно создать индексы, на каких носителях какие файлы следует разместить и т.п. Другими словами, на этом этапе выполняется отображение концептуальной модели на структуры хранимых данных.
Все принимаемые здесь решения зависят от конкретной СУБД, которая будет контролировать базу. Абсолютно точная реализация логического макета БД средствами этой СУБД может оказаться невозможной. Поэтому обычно для достижения компромисса между требованиями ПО и возможностями реализации приходится выполнить несколько итераций проектирования логического и физического макетов.
На третьем этапе определяются подмножества данных, необходимых конкретным КП, и проектируются отображения концептуального макета БД на макеты КП. Кроме того, проектируются интерфейсы КП.
Требования конечных пользователей меняются со временем. Может возникнуть потребность в данных, хранение которых не предусмотрено. Может исчезнуть необходимость хранения каких-то данных. Могут измениться способы использования хранимых данных или правила бизнеса.
Все это приводит к необходимости изменения логического макета. Таким образом, процесс проектирования БД, условно изображенный на рис. 3.1, продолжается в течение всего периода жизни системы.
 |
Для того чтобы получить качественную БД, нужно в первую очередь создать концептуальную модель данных. Интерес при этом представляют сами данные как таковые и правила целостности, обусловленные бизнес-правилами и смыслом данных. Только после того, как создан логический макет, можно приступать к анализу аспектов реализации структур хранения и приложений.
Здесь мы будем обсуждать только проблемы проектирования концептуальной модели. Будем иметь в виду реляционный макет, хотя все, сказанное ниже, может и должно быть использовано при проектировании нереляционных баз данных. Иначе говоря, проектируя нереляционную (например, сетевую) БД, следует прежде всего создать реляционный макет, а затем отобразить его на нереляционные структуры, поддерживаемые целевой СУБД.
Проектирование БД – это скорее искусство, чем наука. Тем не менее, существуют некоторые принципы проектирования, которых следует придерживаться. Эти принципы формально обоснованы. Существуют строгие доказательства того, что логический макет данных, построенный в соответствии с ними, обладает определенными «хорошими» свойствами. Мы познакомимся здесь с этими принципами, но не с их формальными обоснованиями.
Поскольку при реальном проектировании всегда возникают проблемы, не охватываемые этими принципами, существует очень много различных методик проектирования. Не существует критериев предпочтения для какой-либо конкретной методики. Однако есть два наименее специализированных подхода к проектированию логического макета.
С одним из них – формальным – мы познакомимся лишь поверхностно, исключительно для того, чтобы понять суть общих проблем, возникающих при проектировании концептуальной модели, и выяснить, какие основные формальные требования предъявляются к «хорошим» структурам БД.
Второй подход – семантический – изучим достаточно подробно. Его рекомендуется использовать для выполнения курсовых проектов.
Иерархии сущностей
.
При описании ПО нередко обнаруживается, что несколько различных объектов имеют сходные свойства и вступают в одинаковые связи с другими объектами. Либо наоборот, оказывается, что экземпляры объекта образуют подмножества, обладающие различными свойствами и вступающие в различные связи.
Например, множество преподавателей ВУЗа является подмножеством множества работников ВУЗа, которое включает в себя, кроме преподавателей, учебно-вспомогательный персонал, работников обеспечивающих служб, администрации и другие категории работников. В базе данных ВУЗа должна быть представлена информация обо всех этих категориях. Часть характеристик категорий совпадает (например: табельный номер, ФИО, дата рождения). Другая часть свойственна только конкретной категории (например, преподаватель, как правило, имеет ученую степень, а лаборант – нет). Кроме того, различные категории работников ВУЗа могут вступать в различные отношения с другими объектами ПО. Например, преподаватель обязательно преподает, по крайней мере, одну учебную дисциплину, а электрик АХЧ никогда не вступает в такую связь.
Можно предложить два варианта описания этой ситуации.
· Ввести единственную сущность СЛУЖАЩИЙ
как объединение множеств атрибутов всех категорий служащих. Эта сущность вступает в связи со всеми другими сущностями, с которыми связаны преподаватель или лаборант и т.д.
· Ввести сущности ПРЕПОДАВАТЕЛЬ, ЛАБОРАНТ и т.д., представляющие выделенные категории работников, и определить все связи этих сущностей.
Однако, и первый и второй варианты неудовлетворительны. Оба неадекватно отображают предметную область. Действительно, первый вариант скрывает реально существующую внутреннюю структуру сущности СЛУЖАЩИЙ и затрудняет понимание ее связей. Можно предположить, что любой экземпляр СЛУЖАЩЕго может заниматься преподаванием, хотя на самом деле это не так. Второй вариант описания этим недостатком не обременен, зато он скрывает факт наличия общих характеристик сущностей.
Для отображения подобных ситуаций в модели ПО вводятся понятия родовой (обобщенной) сущности и категории.
Родовой сущностью (супертипом, суперклассом) называется сущность, экземпляры которой классифицированы в один или более подтипов
(подклассов).
Категорией
называется сущность, экземпляры которой представляют подтип (подкласс) родовой сущности.
В состав атрибутов родовой сущности входят только общие атрибуты всех категорий. Каждый экземпляр категории является одновременно экземпляром родовой сущности, т.е. категория наследует атрибуты родовой сущности. В связях родовой сущности могут участвовать экземпляры любой категории. Категория может иметь атрибуты и/или вступать в связи с другими сущностями, не свойственные всем экземплярам родовой сущности, а свойственные только экземплярам категории.
Категории родовой сущности выделяются по некоторому признаку. Его значения одинаковы во всех экземплярах одной категории и различны в экземплярах разных категорий. Все множество категорий, выделенных по значениям этого признака, называется кластером категорий, а сам признак – дискриминатором кластера. Экземпляры родовой сущности могут классифицироваться по различным признакам, образуя несколько кластеров категорий. Наконец, любая категория может быть родовой сущностью, порождающей свои кластеры категорий.
Таким образом, понятия родовой сущности и категории позволяют строить иерархии
сущностей любой сложности.
Имя роли
Имя роли
Именование ролей – это механизм разрешения конфликтов имен. Они возникают, например, в унарных связях (см. п. 2.3.4,, замечание 9). Нередки также ситуации, когда один и тот же атрибут передается сущности через посредство нескольких различных связей.
Пример. БД должна хранить сведения о некоторых ИЗДЕЛИях и об УЗЛах, входящих в их состав. При этом сами УЗЛы могут состоять из других узлов, т.е. быть составными ИЗДЕЛИями. Нужно показать, в состав каких ИЗДЕЛИй какие УЗЛы входят. Один и тот же УЗЕЛ может входить в состав различных ИЗДЕЛИй. На ER- уровне это может выглядеть так:
 |
Однако на KB-уровне придется преобразовать это неспецифическое соединение к виду
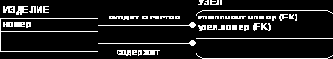 |
Рис. 4.6 Имена ролей
Каждая связь передает атрибут номер сущности ИЗДЕЛИЕ в состав атрибутов сущности УЗЕЛ в качестве внешнего ключа. Внешние ключи, переданные различными связями, имеют различный смысл. В каждом экземпляре потомка значения передаваемого по разным связям атрибута номер
будут различными. Поэтому он должен войти в схему потомка дважды, но с различными именами. Показанные на рисунке 4.6 префиксы имени номер называются именами ролей. Они явно именуют различные роли сущности ИЗДЕЛИЕ
в разных связях с потомком.
Имя роли
это – новое имя компонента внешнего ключа, явно указывающее на роль, исполняемую сущностью в связи.
В ситуациях, подобных рассмотренной, имена ролей необходимы для разрешения конфликта. Однако на их использование нет никаких ограничений. Имя роли может быть назначено всякий раз, когда проектировщик модели считает это нужным, например, для точной передачи смысла связи, улучшения читаемости диаграммы и т.п. На имя роли можно ссылаться в диаграмме как на атрибут.
Информация, данные
.
Словом «информация» мы будем обозначать любые сведения о чем-либо, которые могут быть восприняты, преобразованы, сохранены и найдены при помощи ЭВМ.
Данные
– это форма, которую может принять информация. Приведем два определения этого понятия.
1) Представление фактов, понятий или команд в формализованном виде, удобном для пересылки, интерпретации и обработки человеком или автоматически.
2) Любое представление, которому приписано или может быть приписано какое-то значение.
Эти определения раскрывают два различных аспекта понятия. Первое утверждает, что данные – это одна из возможных форм представления информации. В соответствии со вторым данные – это абстракция, символ, принимающий различные значения.
Например, фамилия, возраст, пол – это символы, поставленные в соответствие абстрактным понятиям. ‘Иванов’, ‘Петрова’, ‘Сидоров’ – значения символа фамилия.
Отметим, что оба определения не накладывают никаких ограничений на внутреннюю структуру представления. Например, данными является символ ЧЕЛОВЕК, обозначающий множество символов {фамилия, возраст, пол, …}. Значениями символа ЧЕЛОВЕК являются наборы значений символов-компонентов: {‘Иванов’, ‘25’, ‘муж.’, …}, {‘Петрова’, ‘18’, ‘жен.’, …}.
Изменяемость отношений
. Реляционная модель данных рассматривает отношение как структурный тип. Тип определяется схемой отношения. Все кортежи – знаки типа – удовлетворяют одной и той же схеме. Тело отношения может изменяться во времени. Отдельные кортежи могут добавляться или удаляться. Могут изменяться значения атрибутов в существующих кортежах[11]. Поэтому можно говорить об экземпляре (текущем значении) отношения с заданной схемой.
Экземпляр (значение) отношения – это набор кортежей с заданной схемой, существующий в некоторый фиксированный момент времени.
Замечание 2.
Определенное здесь понятие отношения не совпадает
с одноименным понятием теории множеств.[12]
Читателю предлагается самостоятельно обнаружить различия.
Элементарные понятия
. Выделяется шесть базовых понятий РМД: тип данных, домен, атрибут, схема отношения, кортеж, отношение. Первые три относятся к элементам данных, остальные – к структурам, объединяющим элементы.
Тип данных (в классической РМД) есть множество значений, не имеющих внутренней структуры. Это совпадает с понятием простого типа в ЯВУ. Реляционные СУБД обычно поддерживают числовые, символьные, битовые и логические типы, а также специальные числовые типы, такие как деньги, даты, время и т.п.
Домен есть подмножество элементов типа. Формально домен определяется как пара <тип, предикат>. Предикат задает условия принадлежности элемента типа домену. На одном и том же типе можно определить произвольное число доменов.
Атрибут
есть имя, поставленное в соответствие домену и представляющее семантически значимое свойство объекта ПО. Если домену поставлено в соответствие имя, то говорят, что на домене определен атрибут.
Атрибут принимает значения на домене.
На одном и том же домене можно определить произвольное число атрибутов. Атрибуты, определенные на общем домене, наследуют его свойства.
Категории пользователей
.
Пользователи системы по их отношению к процессам обработки данных разделяются на три категории.
· Конечные пользователи (КП) – работники предприятия, использующие данные для выполнения служебных обязанностей. Доступ к данным для каждого КП ограничен той частью БД, которая соответствует его обязанностям. В этой части он может выполнять только те манипуляции данными, которые поддерживаются специально для него разработанным интерфейсом конечного пользователя. Как правило, КП не имеет специальных знаний и навыков в области компьютерных технологий.
· Прикладные программисты – пользователи системы, создающие и сопровождающие программы для конечных пользователей. Они не работают с данными непосредственно. Их задачи – реализация алгоритмов обработки данных и создание удобного интерфейса конечного пользователя.
· Администратор базы данных – группа специалистов, проектирующих, реализующих и сопровождающих систему (см. п. 1.2.3).
Компоненты языка IDEFX
Компоненты языка IDEF1X
4.2.1 Модель данных. Стандарт IDEF1X дает следующее определение модели данных:
Модель данных – графическое и текстуальное представление, идентифицирующее потребности организации в данных для достижения ее целей, выполнения функций и определения стратегий управления. Модель данных идентифицирует сущности, домены, атрибуты и связи между данными и поддерживает единый концептуальный взгляд на данные и их взаимосвязи.
В соответствии с этим определением IDEF1Х как язык описания данных содержит два важнейших компонента:
· графический – средства создания диаграмм, показывающих структуру и взаимосвязи данных;
· текстовый – правила создания и ведения текстовых документов, уточняющих и поясняющих графическую модель, – глоссариев, спецификаций, отчетов, заметок и т.п.
Мы здесь сосредоточимся, главным образом, на графическом компоненте.
Компоненты СБД
. В систему базы данных входит ряд компонентов (рис. 1.2), предназначенных для поддержания БД и интерфейсов пользователей, а также ряд вспомогательных компонентов, обеспечивающих обучение пользователей, информирование о возможностях системы, накопление и анализ сведений о ее работе и т.д.
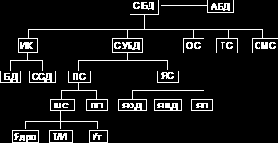 |
Рис. 1.2 Состав СБД
| СБД | - система базы данных, | ПП | - прикладные программы, | ||||
| ИК | -информационный компонент, | ЯС | - языковые средства, | ||||
| БД | - база данных, | ЯОД | - языки определения данных, | ||||
| ССД | - словарь-справочник данных, | ЯМД | - языки манипулирования данными, | ||||
| СУБД | - система управления БД, | ЯП | - языки программирования, | ||||
| ПС | - программные средства, | ОС | - операционная система, | ||||
| ШС | - штатные средства, | ТС | - технические средства, | ||||
| Ядро | - ядро СУБД, | ОМС | -организационно-методич. средства, | ||||
| Т/И | - трансляторы/интерпретаторы, | АБД | - администратор базы данных. | ||||
| Ут | - утилиты, |
База данных
– находящаяся под управлением СУБД совокупность хранимых данных, отражающих текущее состояние ПО.
Словарь-справочник данных – хранилище информации обо всех ресурсах системы базы данных. В нем содержатся сведения, характеризующие состав и структуру БД, смысловые определения элементов данных и их агрегатов, характеристики связей, ограничения целостности данных, а также сведения о владельцах и пользователях ресурсов данных, полномочиях доступа к данным различных категорий пользователей и т.п.
ССД – это база данных, предметной областью которой является СБД и ее окружение. Как правило, БД и ССД контролируются одной СУБД.
Система словаря данных обеспечивает централизованное накопление метаданных и управление ими как ресурсом на всех этапах проектирования, реализации и эксплуатации СБД. ССД обеспечивает эффективное взаимодействие между всеми категориями пользователей СБД. Описания данных в словаре привязаны к единой терминологии, согласованной со всеми категориями пользователей.
Словарь используется для документирования разработки СБД и справочного обслуживания разработчиков и пользователей. Часть словаря – системный каталог, содержащий формальные описания структуры БД, правил целостности и т.п., – обеспечивает поддержку функционирования СУБД и прикладных программ. Таким образом, словарь является необходимым компонентом СБД, обеспечивающим ее разработку и эксплуатацию [3].
СУБД
– комплекс программных и языковых средств, предназначенный для создания баз данных и управления данными.
Штатные средства СУБД обеспечивают следующие функции:
· ядро – организацию ввода, обработки и хранения данных;
· трансляторы/интерпретаторы – компиляцию и/или интерпретацию прикладных программ, написанных на входных языках СУБД;
· утилиты – различные вспомогательные функции: настройку системы, ее тестирование, восстановление БД в случае разрушения, сбор статистики о функционировании СБД и т.д.
Прикладные программы (ПП) создаются программистами, обслуживающими конечных пользователей СБД. Они обрабатывают запросы к БД и поддерживают интерфейс КП, обеспечивая предоставление информации в привычной и понятной конечным пользователям форме.
Языковые средства
СУБД предназначены для обеспечения интерфейсов всех категорий пользователей.
· Языки определения данных предоставляют средства описания элементов и структур данных, экранных форм и других параметров приложений.
· Языки манипулирования данными обеспечивают навигацию в БД или формулирование запросов к данным.
· Языки программирования предназначены для написания прикладных программ, обрабатывающих данные в интересах конечных пользователей.
Используя эти средства, прикладные программисты, обслуживающие СБД, могут создавать специализированные языки, ориентированные на конечных пользователей. Как правило, это наборы экранных форм, содержащих поля ввода/вывода данных и органы управления. Такие формы отображают данные в виде, привычном для пользователя, и обеспечивают ему возможность управления данными с использованием привычной терминологии.
Операционная система рассматривается как часть СБД, поскольку, как правило, СУБД работает под управлением универсальной ОС, используя ее штатные средства управления файлами.
Технические средства СБД – это чаще всего универсальные ЭВМ с необходимым набором периферийных средств. Тенденция нашего времени – реализация СБД на сетях персональных ЭВМ.
К организационно-методическим средствам
относятся различные инструкции, методические и регламентирующие документы, предназначенные для пользователей различных категорий, такие как проектная документация, руководство пользователя и т.п.
Администратор БД – это группа специалистов, обеспечивающих создание, функционирование и развитие системы базы данных. Она создается на начальном этапе жизненного цикла системы и выступает как ее идеолог и разработчик. Функционирование системы невозможно без АБД.
1.2.3 Функции и состав АБД. В зависимости от сложности и объема СБД, ее специфики, особенностей используемой СУБД и некоторых других факторов, количественный состав и структура группы АБД могут быть различными. Однако в любом случае АБД выполняет следующие функции [3]:
· анализ предметной области;
· проектирование структуры БД;
· обеспечение целостности данных;
· первоначальная загрузка и ведение БД;
· защита данных;
· обеспечение восстановления БД;
· анализ обращений пользователей к БД;
· анализ эффективности функционирования СБД и развитие системы;
· работа с пользователями;
· подготовка и поддержание системных программных средств;
· организационно-методическая работа.
В зависимости от специфики конкретной СБД объем этих функций может быть различным, но так или иначе все они должны выполняться АБД.
Этот перечень функций определяет состав АБД. В группу должны входить следующие специалисты:
· системные аналитики;
· проектировщики структур БД;
· проектировщики технологических процессов обработки данных;
· системные программисты;
· прикладные программисты;
· операторы;
· специалисты по техническому обслуживанию.
Количественный состав АБД определяется спецификой организации, в которой используется система. Перечисленные функции могут в той или иной степени выполнять один-два человека (ситуация, характерная для СБД небольших предприятий), а иной раз АБД – это крупное структурное подразделение, в состав которого входит несколько групп специалистов.
Функции АБД определяют его связи с внешним (по отношению к АБД) миром. Здесь можно выделить три канала.
· Связь с администрацией предприятия, использующего СБД. Ни создание, ни эксплуатация СБД невозможны без поддержки администрации предприятия-пользователя. Проблемы, требующие разрешения на уровне компетенции руководителя предприятия и его заместителей, возникают с самого начала разработки СБД и не исчезают никогда. Поэтому в организациях, серьезно относящихся к развитию средств автоматизации обработки данных, руководитель АБД обычно является одним из заместителей главного руководителя и принимает участие во всех решениях, связанных с изменениями информационных потоков.
· Связь с конечными пользователями также возникает на первых этапах (выяснение потребностей, принятых правил работы с документами, привычных форм и т.д.). Эта связь поддерживается постоянно в соответствии с вышеперечисленными функциями АБД.
· Связь с внешними специалистами родственных профилей также имеет место всегда. Это поставщики оборудования, СУБД, пакетов прикладных программ, администраторы других СБД и т.д.
Концептуальная модель ПО
.
Концептуальной (информационной) моделью ПО называется формальное описание объектов реального мира, их свойств и отношений между ними, выполненное с точки зрения определенного вида деятельности и без учета каких-либо аспектов реализации БД.
Концептуальная модель должна:
· быть точной и однозначной;
· адекватно отражать природу данных;
· не зависеть от локальных интерпретаций данных (внешних моделей), обусловленных различными аспектами их использования.
Модель, удовлетворяющая этим требованиям, обеспечивает порождение любых локальных интерпретаций данных посредством формального преобразования концептуального представления. Создание концептуальной модели ПО – важнейший этап проектирования базы данных.
Понятийные основы концептуального моделирования заложены американским исследователем П. Ченом, предложившим в 1976 году так называемую модель «сущность–связь» (Entity–Relationship, ER-модель). Определенные Ченом понятия и диаграммная техника представления структур данных широко используются в практике проектирования концептуальных моделей ПО для различных приложений. Достаточно подробный обзор ER-модели Чена можно найти в [1, гл. 12]. В настоящей главе изложены основные понятия ER-модели в современной терминологии. Мы не описываем диаграммную технику Чена, хотя она и не вышла из употребления. В главе 4 настоящего пособия определены современные нотации, поддерживаемые многими CASE–средствами автоматизации проектирования БД.
Концептуальная модель предметной области
. Понятие концептуальной модели является, пожалуй, наиболее важным достижением теории баз данных. Здесь мы кратко обсудим его на интуитивном уровне. Детали и определения приведены в последующих главах.
Для того чтобы представить ПО в БД, нужно указать, какая именно информация о каких именно объектах и фактах ПО будет храниться. Другими словами, нужно выполнить описание ПО с точки зрения того вида деятельности, для которого предназначается БД. Это описание называется концептуальной (информационной) моделью ПО.
Модель включает описания трех основных компонентов ПО – объектов, их свойств и связей между ними.
Объекты – это вовлеченные в деятельность люди, предметы, места, происходящие события и т.п., информация о которых должна храниться в БД. Можно сказать, что объект есть то, что в словесном описании ПО обозначается именем существительным, возможно, с определениями. Это абстракция множества сходных в определенном смысле экземпляров.
Например, СТУДЕНТ, ПРЕПОДАВАТЕЛЬ, УЧЕБНАЯ ДИСЦИПЛИНА, АУДИТОРИЯ
– объекты ПО «Учебный процесс». ПАЦИЕНТ, ПАЛАТА, ВРАЧ – объекты ПО «Больница».
Объекты обладают некоторыми свойствами (характеристиками), представляющими интерес для бизнеса. Так, СТУДЕНТ характеризуется номером студбилета, фамилией, номером группы, адресом и т.д. Свойствами ПРЕПОДАВАТЕЛЯ
являются фамилия, номер диплома, специальность, ученая степень и т.п. Каждый экземпляр объекта характеризуется определенным набором значений свойств.
Экземпляры объектов вступают в некоторые отношения друг с другом. Информация об этих отношениях также представляется в модели в обобщенном виде, как указание определенной связи между объектами как множествами экземпляров. Так, фраза: «Студент Иванов изучает учебную дисциплину ‘Базы данных’» выражает связь экземпляров объектов СТУДЕНТ и УЧЕБНАЯ ДИСЦИПЛИНА. Очевидно, не только этот студент изучает эту дисциплину, и этот студент изучает не только эту дисциплину. Поэтому можно говорить о связи (отношении) объектов СТУДЕНТ и УЧЕБНАЯ ДИСЦИПЛИНА, выражаемой глаголом ‘изучать’.
Концептуальная модель ПО есть формальное описание объектов, их свойств и отношений.
Контроль целостности домена
. Правило целостности домена должно проверяться при любой попытке ввода/обновления значения любого атрибута, определенного на этом домене. Для того чтобы РСУБД могла это делать, правило должно быть сформулировано в виде предиката и связано с доменом специальным предложением ЯОД – предложением объявления домена (см. п. 2.4.1). Обрабатывая это предложение, система вносит в свой каталог имя домена и реализует процедуру вычисления значений предиката. Процедура связывается с именем домена и сохраняется для дальнейшего исполнения.
Атрибут связывается со своим доменом строкой предложения определения базового отношения (см. п. 2.4.2.). Это определение также сохраняется в системном каталоге. При попытке присваивания атрибуту значения в новом или существующем кортеже система находит по каталогу имя соответствующего домена и вычисляет значение связанного с ним предиката на новом значении атрибута. Если предикат принял значение .F., обновление отвергается.
Контроль целостности сущности
. Правило целостности сущности должно проверяться при любой попытке добавления нового кортежа в базовое отношение (операция INSERT) или обновления значения первичного ключа (операция UPDATE). Для этого в РСУБД может быть определена стандартная процедура, возвращающая логическое значение. Входными данными для нее являются имя обновляемого отношения и вводимое значение набора атрибутов первичного ключа. Процедура возвращает значение .F., если
·
хотя бы один атрибут набора принял значение Null или
· значение набора уже существует в текущем множестве значений первичного ключа обновляемого отношения.
Процедура связывается с конкретным отношением в процессе обработки строки определения первичного ключа в предложении определения отношения (см. п. 2.4.2). В соответствующий раздел системного каталога заносится перечень атрибутов, входящих в состав первичного ключа. При попытке выполнить операцию UPDATE модуль контроля обновлений может установить по каталогу, входит ли обновляемый атрибут в первичный ключ. Если да, то процедура запускается. Попытка выполнения операции INSERT всегда инициирует эту процедуру. Обновление отвергается, если процедура контроля целостности сущности возвратила значение .F.
Контроль ссылочной целостности
. Требование ссылочной целостности накладывает ограничения на все три операции обновления БД (см. табл. 2.1). Рассмотрим эти ограничения.
Операция
INSERT. Эта операция затрагивает только одно отношение. Если вставляется кортеж в отношение, не являющееся потомком ни в какой связи, то ссылочная целостность не может быть нарушена. Просто в БД появится новый кортеж, на который нет ссылок.
Если добавляется кортеж в отношение-потомок, то ссылочная целостность может быть нарушена. Кортеж можно включить в БД, если содержащееся в нем значение внешнего ключа принадлежит существующему в настоящий момент множеству значений родительского ключа. В РСУБД должна быть системная процедура проверки, подобная процедуре контроля целостности сущности. Она должна вызываться автоматически при любой попытке вставить кортеж в отношение-потомок. Входными данными для нее являются имя ссылочного отношения и значение набора атрибутов внешнего ключа. Процедура возвращает значение .F., если вводимое значение набора атрибутов внешнего ключа потомка не существует в текущем множестве значений первичного ключа родителя.
Процедура связывается с конкретным отношением в процессе обработки строки определения внешнего ключа в предложении определения отношения (см. п. 2.2.4.2). В соответствующий раздел системного каталога заносятся имя ссылочного отношения и перечень атрибутов, входящих в состав внешнего ключа потомка. Попытка выполнения операции INSERT всегда инициирует эту процедуру. Обновление отвергается, если процедура возвратила значение .F.
Операции DELETE и UPDATE. Удаление кортежа отношения, не являющегося ссылочным ни для какого другого, не может привести к нарушению ссылочной целостности. Так, в нашей БД «Поставщик-Деталь-Изделие» мы можем удалить без всяких последствий любой кортеж отношения SPJ.
Однако, если мы попытаемся удалить из отношения S какой-то кортеж, на который есть ссылка в SPJ, то это приведет к проблеме.
Пусть есть в S кортеж
‘S1’, ‘Иван’, 150, ‘Яя’,
а в
SPJ
– кортеж
‘S1’, ‘P3’, ‘J12’ 1000.
Удалив первый, мы нарушим требование ссылочной целостности, т.к. в SPJ
останется кортеж, содержащий значение ‘S1’, которого нет во множестве значений S.S#.
Аналогичная ситуация возникает при попытке обновить значение ссылочного ключа. Если понадобится изменить в S значение ‘S1’ на ‘S11’, то что делать с соответствующим значением SPJ. S#
?
Существует, по крайней мере, две возможности.
· Отложить удаление/обновление ссылочного ключа до тех пор, пока в БД не останется ни одного ссылающегося на него значения внешнего ключа. Кортеж из S, содержащий значение S.S# = ‘S1’, может быть удален только после того, как в SPJ
не останется ни одного кортежа, содержащего значение SPJ.S# = ‘S1’.
· Каскадировать удаление/обновление, т.е. удалить или обновить значение внешнего ключа во всех кортежах, ссылающихся на удаляемый/обновляемый родительский ключ. Например, удалить кортеж со значением S.S# = ‘S1’ и все кортежи SPJ со значением SPJ.S# = ‘S1’.
Таким образом, операции удаления/обновления родительского ключа затрагивают, по крайней мере, два
отношения – ссылочное и ссылающееся.
Для того чтобы система могла поддерживать ссылочную целостность при выполнении этих операций, нужно сообщить ей, что она должна делать с кортежами-потомками удаляемого кортежа-родителя, т.е. определить правило внешнего ключа.
Правило реализуется в виде хранимой процедуры – триггера ссылочной целостности. Триггер связывается в системном каталоге с внешним ключом потомка при обработке строки объявления внешнего ключа в предложении определения отношения (см. п. 2.4.2). Он запускается при любой попытке удаления/обновления значения родительского ключа.
Мы говорили о двух видах триггеров ссылочной целостности – ОТЛОЖИТЬ и КАСКАДИРОВАТЬ. Они наиболее часто используются на практике, поэтому РСУБД обычно имеют системные триггеры отложенного и каскадного удаления/обновления. Но возможные варианты действий не ограничиваются этими правилами.
Вообще говоря, правила внешнего ключа могут быть какими угодно.
Например, система может:
· предложить пользователю самостоятельно решить вопрос о том, что делать со ссылающимися кортежами;
· заменить значения внешнего ключа, ссылающиеся на удаляемое значение родительского, значениями по умолчанию;
· удалить ссылающиеся кортежи из отношения-потомка и занести их в некое архивное отношение и т.п.
Как правило, в БД, даже относительно простых, большинство отношений являются и ссылочными и ссылающимися. Правила внешних ключей устанавливаются для каждого из них индивидуально. При этом могут возникать сложные ситуации.
Например, пусть R1, R2, R3
– связанные отношения: R3 ® R2 ® R1. Для R2 определено каскадное удаление. Сделана попытка удаления кортежа R1, на который есть ссылки в R2. Следует удалить все кортежи R2, ссылающиеся на удаляемый кортеж R1. Однако на эти кортежи есть ссылки в R3. Если для R3 также установлено правило каскадного
удаления, то операция будет выполнена «лавиной». Если же для R3 определено отложенное удаление, то операция удаления из R2 не может быть выполнена, и, следовательно, не может быть выполнена операция удаления из R1.
Операции удаления/обновления всегда атомарны.
Либо выполняются все определенные правилами изменения в группе отношений, затронутых операцией, либо не выполняется ни одно, и состояние БД остается неизменным.
Лексические соглашения
Лексические соглашения
Для того чтобы обеспечить наглядность и читаемость диаграмм, стандарт IDEF1X рекомендует придерживаться ряда соглашений относительно построения имен и фраз на диаграммах.
4.9.1 Имена. В именах сущностей и атрибутов используются только буквы, цифры, а также знаки–разделители: «дефис», «подчерк» и «пробел». Имя должно начинаться с буквы. Части составного имени отделяются дефисом, подчерком или пробелом. Эти разделители не различаются.
Рекомендуется имена сущностей на диаграммах и в текстах глоссариев и замечаний всегда писать ПРОПИСНЫМИ буквами.
Например, глоссарий может содержать такое определение имени ПОСТАВЩИК: «Юридическое лицо, заключившее с фирмой договор на поставку одного или нескольких видов ДЕТАЛей для одного или нескольких видов ИЗДЕЛИй «.
Это определение содержит сведения не только о смысле, но и о связях определяемой сущности с другими сущностями ПО. Выделение имен этих сущностей регистром облегчает зрительное восприятие фактов связи.
Помимо вышеперечисленных разделителей в именах используются еще «×« и «/». Точка отделяет имя роли от основного имени атрибута. Имя роли предшествует точке, основное имя следует за точкой. Ни перед, ни после точки не допускаются другие разделители. Слэш разделяет разнонаправленные имена связи. Кроме того, он разделяет имя сущности или связи и его идентификатор.
4.9.2 Идентификаторы. Стандарт рекомендует назначать именам сущностей и связей уникальные идентификаторы. За идентификатор обычно принимают порядковый номер сущности или связи в порядке появления объекта на диаграмме. Обычно присваиваются идентификаторы вида «Е<число>« сущностям и «R<число>« - связям.
4.9.3 Метки атрибутов. Метки атрибутов размещаются вслед за именем атрибута в круглых скобках. Допускаются следующие метки:
(О) – атрибут может принимать NULL-значения;
(FK) – внешний ключ;
(AK<N>) – атрибут N-го альтернативного ключа;
(<число>) – ссылка на примечание.
Метки (О) и (АК) не могут использоваться вместе, т.е. комбинация вида «дата (АК1) (О)» недопустима. Других ограничений на комбинации значений меток нет.
Методологии семантического подхода
. В настоящее время существует несколько методологий анализа и проектирования логического макета БД, реализующих семантический подход. Основным компонентом любой из них является графический язык определения данных – система графических нотаций для основных понятий ER-модели. Этими средствами проектировщик может точно, ясно и наглядно сформулировать свои текущие представления о ПО в виде диаграмм. Второй компонент – глоссарий, содержащий однозначные определения имен сущностей и атрибутов. Он раскрывает те аспекты модели, которые невозможно отразить графическими средствами. Методологии различаются, в основном, нотациями графических языков определения данных и обладают рядом общих достоинств.
Во-первых, все они поддерживают параллельное развитие анализа ПО и проектирования структуры БД и правил целостности данных. Нет никакой необходимости выявлять весь перечень хранимых данных и правил бизнеса еще до начала проектирования. Для выделения базовых отношений не нужно использовать громоздкие и сложные процедуры нормализации универсального отношения.
Во-вторых, простота нотаций графических языков, строго определенные правила именования сущностей, атрибутов и связей, а также содержащиеся в глоссарии определения имен обеспечивают точную передачу представлений автора модели и однозначную (и одинаковую!) понимаемость модели всеми участниками разработки – аналитиками, экспертами и проектировщиками структур хранения данных.
В-третьих, строго определенная иерархия уровней модели открывает возможность согласования представлений аналитика с представлениями конечных пользователей системы на всех этапах разработки.
В-четвертых, в настоящее время существует несколько десятков товарных CASE-систем (Computer Aided System Engineering), поддерживающих семантические методологии на всех этапах жизненного цикла системы от формулировки замысла до выпуска проектной документации. Многие из них обеспечивают отображение окончательных диаграмм модели на физические структуры данных распространенных СУБД, а также создание триггеров ссылочной целостности, как стандартных, так и оригинальных.
В силу указанных причин использование семантического подхода значительно снижает трудозатраты на ранних этапах проектирования системы, упрощает и облегчает верификацию моделей и обеспечивает создание высококачественных спецификаций систем баз данных.
Далее в настоящей главе изложены основы методологии информационного моделирования IDEF1X (Integrated DEFinitions 1 eXpanded), имеющей в настоящее время статус федерального стандарта США. Предполагается, что читатель усвоил материал пп. 1.4, 2.1 – 2.3.
На концептуальном уровн
е данные представлены такими, какие они есть на самом деле. Концептуальное представление состоит из множества экземпляров каждого типа концептуальной записи. Она вовсе не обязана совпадать с внешней или хранимой записью. Концептуальное представление задается концептуальной схемой, которая включает определения типов концептуальных записей. Для определения концептуальной схемы используется специальный ЯОД, не содержащий средств определения структур хранения и методов доступа к данным. Определения концептуального языка относятся только к содержанию информации. Если это обеспечено, то внешние схемы, определяемые на основе концептуальной схемы, заведомо не будут меняться при изменении хранимых схем.
Итак, концептуальное представление – это представление всего содержимого БД, а концептуальная схема – определение этого представления.
Однако она содержит не только определения типов записей. В концептуальную схему включаются также определения средств безопасности, правила обеспечения целостности и т.п. Более того, в нее следует включать и описания того, как используются данные на предприятии. Это обеспечит возможность реорганизации процессов управления с целью повышения эффективности предприятия. Однако, реально этого (пока) нет.
Важнейшее свойство концептуальной схемы – стабильность. Она отражает общие информационные потребности бизнеса и может измениться только в связи с радикальным изменением этих потребностей.
Внутреннее представление состоит из множества экземпляров каждого типа внутренней (хранимой) записи. Это представление, так же, как и внешнее и концептуальное, не связано с физическим уровнем, т.е. с блоками, цилиндрами, дорожками и т.д. Оно описывается внутренней схемой, которая определяет типы хранимых записей, способы представления хранимых полей, физическую последовательность хранения записей, существующие индексы и т.д. Внутренняя схема описывается с помощью внутреннего ЯОД, отличающегося как от ЯОД подъязыка данных внешнего представления, так и от концептуального ЯОД. Все, что ниже этого уровня, – уровень ОС.
Единица доступа к данным для СУБД – хранимая запись. СУБД получает доступ к данным через посредство ОС.
Отображения
определяют соответствия между представлениями верхнего и нижнего уровней. Отображение концептуальный « внутренний ставит в соответствие концептуальным полям и записям хранимые. Это соответствие является взаимно однозначным. При изменении структур хранения отображение концептуальный « внутренний изменяется так, чтобы концептуальная схема осталась неизменной. Аналогично отображение внешний «
концептуальный ставит в соответствие концептуальным полям и записям внешние. Отображения реализуются посредством статей словаря данных системы и специальных модулей СУБД, обеспечивающих преобразования данных.
Независимость прикладных программ и данных
[3]. Конечные пользователи СБД получают доступ к хранимым данным через посредство прикладных программ (ПП), работающих с общим полем данных во внешней памяти (см. рис. 1.3). Этого требует принцип интег-
 |
Рис. 1.3 ПП вокруг данных
рированного хранения. При этом ПП могут использовать только общие для всех форматы хранимых файлов, определенные проектировщиком БД. Игнорирование этого требования недопустимо.
В самом деле, предположим, что прикладные программы создают файлы собственных форматов. Тогда возможны показанные на рис. 1.4 варианты соответствия ПП и данных.
| Вариант 1 | Вариант 2 | ||
 |  | ||
| Каждая ПП использует только собственные файлы со всеми нужными данными. | ПП создает собственные файлы, если нет подходящих файлов других ПП. |
Рис. 1.4 Данные вокруг ПП
В первом варианте неизбежна неконтролируемая избыточность. Данным нельзя доверять и ими невозможно управлять как общим ресурсом предприятия.
Во втором варианте избыточности нет, но возникает ряд проблем проектирования и развития системы. Главная из них состоит в том, что если прикладной программист изменит структуры файлов своей ПП, скажем, с целью повышения эффективности программы, то придется переписать все ПП, использующие эти файлы. Прикладные программы оказываются взаимно зависимыми в этом смысле.
Вариант «ПП вокруг данных» (рис. 1.3) лишен этих недостатков. Здесь нет ни неконтролируемой избыточности, ни взаимной зависимости ПП. Однако, если ПП получают доступ к данным непосредственно от ОС, то возникает проблема зависимости ПП от данных. Подробное обсуждение этой проблемы можно найти в [1]. Здесь излагается только ее суть. Начнем с определения терминов.
Данные, хранящиеся во внешней памяти, будем называть хранимыми. Наименьшая (логическая) единица хранимых данных называется хранимым полем. Обычно во внешней памяти размещается много экземпляров
хранимых полей, т.е. значений поля.
Поле имеет имя и тип. Хранимые поля объединяются в хранимые записи. Хранимая запись – это набор связанных хранимых полей.
Например
|
номер детали |
наименование |
вес |
– тип хранимой записи |
|
‘P12’ |
‘шайба’ |
0,1 |
– экземпляр записи |
Вариант «ПП вокруг данных» предполагает, что все нужные типы хранимых записей и все их связи определены проектировщиком БД в виде схемы хранения данных. Прикладной программе известна часть схемы, содержащая необходимые ее пользователю данные. Тело программы содержит ссылки на доступные ей хранимые записи и поля. Если схема хранения изменится, то придется переписать все ПП, ориентированные на измененную часть схемы.
Необходимость внесения изменений в схему хранения возникает отнюдь не в исключительных случаях.
· В связи с изменениями требований пользователей могут быть добавлены/удалены хранимые поля или типы записей.
· В связи с изменением программно-технической платформы системы может измениться, например, способ упорядочения записей или способ доступа к записям и т.п.
· Для повышения эффективности обработки запросов к данным может потребоваться изменение структуры хранимых записей. Например, два существующих типа хранимых записей используются в запросах, как правило, вместе. Разумно объединить их в один. Это приведет к уменьшению числа обращений к внешней памяти. Или наоборот, часть длинной записи редко используется и может быть размещена на более медленном устройстве. Разумно расщепить запись на две.
· Для удовлетворения новым стандартам или требованиям защиты, или с целью экономии внешней памяти и т.д. может понадобиться: изменить представление числовых данных – форму, основание системы счисления, масштаб, тип, точность и т.д.; изменить кодировку символов (ASCII – EBCDIC); ввести кодирование данных.
Требование независимости ПП и данных состоит в том, что все эти изменения не должны быть видны
прикладным программам.
Нормальная форма Бойса – Кодда
(НФБК). Предположим, что в нашей ПО не может быть двух поставщиков с одинаковыми именами, и представим себе, что «учебную» БД проектировал малоопытный проектировщик, создавший отношение со схемой SSPJ(S#, Sn, P#, J#, Dt, Qt). Оно имеет два потенциальных ключа: {S#, P#, J#, Dt} и {Sn, P#, J#, Dt} и находится в 3НФ, так как единственный неключевой атрибут неприводимо зависит от каждого из них. Тем не менее, возможно избыточное дублирование данных.
| S# | Sn | P# | J# | Dt | Qt | ||||||
| S1 | Иван | P1 | J1 | ... | 1000 | ||||||
| S1 | Иван | P2 | J1 | ... | 1000 | ||||||
| S1 | Иван | P3 | J1 | ... | 2000 | ||||||
| S2 | Петр | P8 | J4 | ... | 1000 |
Для того чтобы изменить имя поставщика S1
нужно перебрать все кортежи со значением S# = S1. Если мы удалим кортеж S2, то потеряем информацию об имени поставщика. Это следствие наличия ФЗ S# ® Sn между атрибутами, входящими в состав различных потенциальных ключей. Отношение имеет детерминанты, не являющиеся потенциальными ключами. Для устранения аномалий следует декомпозировать отношение SSPJ. Возможны два варианта декомпозиции без потерь информации:
1) SS(S#, Sn) SPJ(S#, P#, J#, Dt, Qt);
2) SS(S#, Sn) SNPJ(Sn, P#, J#, Dt, Qt).
Отметим, что отношение SS в обоих вариантах имеет два возможных ключа, но при его обновлении не могут возникать аномалии.
Говорят, что отношение находится в нормальной форме Бойса – Кодда, если и только если каждый его детерминант является потенциальным ключом[30].
Если отношение не находится в НФБК, то его всегда можно представить в виде набора проекций, находящихся в НФБК. Но эта декомпозиция не всегда может быть выполнена без потерь информации. Проекции могут оказаться зависимыми в том смысле, что при обновлении одной из них придется обновить и другую.
Пример.
Пусть в отношении СДП(студент, дисциплина, профессор) существуют следующие ФЗ:
профессор ® дисциплина,
{студент, дисциплина} ® профессор,
{студент, профессор} ® дисциплина.
Отношение находится в 3НФ, но не в НФБК, так как имеет три детерминанта: {студент, дисциплина}, {студент, профессор}, {профессор}, а потенциальными ключами являются только два первых.
Возможны три варианта декомпозиции отношения СДП.
Вариант 1.
СП(студент, профессор); ПД(профессор, дисциплина).
Первичными ключами проекций являются подмножества {студент, профессор} и {профессор}. Существует ФЗ профессор ® дисциплина и выводимая из нее ФЗ {студент, профессор} ® дисциплина. Тело естественного соединения проекций СП
и ПД всегда будет эквивалентно исходному отношению СДП, т.к. общий атрибут проекций является первичным ключом отношения ПД. Однако существующая в исходном отношении ФЗ {студент, дисциплина} ® профессор не следует из существующих в этой декомпозиции. Поэтому независимое обновление проекций невозможно. В самом деле, пусть имеется следующее значение отношения СДП:
|
СДП |
||
|
студент |
дисциплина |
профессор |
|
Иванов |
математика |
Комов |
|
Иванов |
физика |
Липов |
|
Петров |
математика |
Комов |
|
Петров |
физика |
Дубов |
|
СП |
ПД |
|||
|
студент |
профессор |
|
профессор |
дисциплина |
|
Иванов |
Комов |
Комов |
математика |
|
|
Иванов |
Липов |
Липов |
физика |
|
|
Петров |
Комов |
Дубов |
физика |
|
|
Петров |
Дубов |
вместе с Петровым. Если Липов преподает одну из дисциплин, преподаваемых Дубовым или Комовым, то новый кортеж должен быть отвергнут.
Вариант 2.
СД(студент, дисциплина); ПД(профессор, дисциплина).
Вариант 3.
СП(студент, профессор); СД(студент, дисциплина).
В каждой декомпозиции утеряна одна из ФЗ, существующих в исходном отношении. Кроме того, восстановить исходное отношение посредством естественного соединения проекций невозможно.Убедитесь в этом сами.
Нормальные формы отношений
Нормальные формы отношений
То, что мы проделали с отношением USPJ, называется процедурой нормализации. Цель нормализации – преобразовать универсальное отношение в систему отношений, удовлетворяющих определенным формальным требованиям. При обновлении данных, хранящихся в такой системе отношений, не возникают аномальные ситуации, и РСУБД в состоянии поддерживать целостность данных.
Требования к базовым отношениям и алгоритмы нормализации без потерь информации составляют предмет математической теории нормальных форм отношений. Мы не будем здесь углубляться в эту теорию. Сформулируем лишь определения важнейших с практической точки зрения нормальных форм для того, чтобы точно определить цель проектирования логической структуры БД. Более подробное изложение теории нормальных форм можно найти, например, в [1].
Объединение отношений
Объединение отношений. Пусть отношения R1 и R2 совместимы по объединению. Отношение R называется объединением отношений R1
и R2, если его схема эквивалентна схемам операндов, а тело составлено из всех кортежей, принадлежащих хотя бы одному из операндов.
R = R1
È R2 = {SR : R ( ) = R1
( ) = R2 ( ), SR Î R1
Ú
SR Î R2}.
Пример:
| A | B | A | B | A | B | ||||||||||||||||
| R1 = | a1 | b1 | , | R2 = | a1 | b1 | , R1 È R2 = | a1 | b1 | . | |||||||||||
| a2 | b2 | a1 | b2 | a1 | b2 | ||||||||||||||||
| a2 | b2 |
Объявление домена
. Домен на самом деле есть то, что в современных языках программирования называется «тип данных, определенный пользователем». К сожалению, большинство современных СУБД не поддерживает домены как объекты БД.
Определение домена может выглядеть так:
CREATE DOMAIN имя-домена тип [(длина)]
{FOR ALL имя-домена (предикат)}|
{VALUES (список)};
Здесь имя-домена
– уникальное имя, под которым домен будет известен системе и на которое можно ссылаться в определениях отношений;
тип – один из поддерживаемых системой встроенных типов данных;
длина
– длина поля данных в байтах;
предикат
– логическое выражение, использующее имя-домена в качестве переменной;
список
– список значений, разделенных запятыми.
Эта декларация объявляет системе, что она должна внести в свой каталог имя нового объекта – домена, и указывает ограничения на значения, принадлежащие домену. Определение сохраняется в системном каталоге. При любой попытке обновления значения какого-либо атрибута, определенного на этом домене, будет вычислено значение предиката. Если оно окажется равным .F., обновление будет отвергнуто.
Пример 1.
CREATE DOMAIN день CHAR (2)
FOR ALL день (
день = ‘пн’ OR
день = ‘вт’ OR
день = ‘ср’ OR
день = ‘чт’ OR
день = ‘пт’ );
Это же можно записать короче:
CREATE DOMAIN день CHAR (2)
VALUES(‘пн’, ‘вт’, ‘ср’, ‘чт’, ‘пт’);
Если, скажем, в ИС банка на этом домене определен атрибут рабочий день, то система сможет заблокировать выполнение банковских операций по субботам и воскресеньям.
Пример 2.
CREATE DOMAIN вес INTEGER
FOR ALL вес (вес ³ 10 AND вес £ 150 AND mod(вес, 5) = 0);
Каждый атрибут, определенный на этом домене, может принимать целочисленные значения в интервале [10, 150], причем только такие, которые делятся на 5 без остатка.
Если есть возможность создать домен, должна быть и возможность удалить его. Следующая команда
DESTROY DOMAIN имя-домена;
удалит из системного каталога определение домена. Она будет исполнена, если в схеме БД нет ни одного атрибута, определенного на удаляемом домене.
Если система поддерживает домены, то в ней есть возможность выполнения запросов, основанных на доменах. Например, запрос
Какие отношения в БД содержат какую-либо информацию о весе?
в терминах доменов имеет вид:
Какие отношения в БД включают атрибуты, определенные на домене Вес?
Это запрос к системному каталогу. В системе, не поддерживающей домены, такие сведения практически невозможно получить.
Объявление отношения
. Можно говорить о переменной-отношении, заданной схемой отношения, и о значении отношения, существующем в БД в конкретный момент времени (см. п. 2.2.4). Определять следует только схему, т.е. переменную. Значения отношения формируются системой в процессе выполнения запросов пользователей.
В реляционной БД всегда существует несколько основных видов отношений.
· Именованное отношение – это отношение, имя и определение схемы которого сохранены в системном каталоге. Именованное отношение может быть базовым или производным.
· Производное отношение есть отношение, определенное посредством реляционного выражения (см. пп. 2.5, 2.6) через именованные отношения. Производное отношение может быть именованным или неименованным.
· Базовое отношение – именованное отношение, не являющееся производным.
Любое производное отношение, в конце концов, выражается через базовые. Поэтому средства явного определения схемы нужны только для базовых отношений.
Объявление реляционных объектов
Объявление реляционных объектов
Реляционными объектами являются домены, отношения и процедуры базы данных (хранимые процедуры), обеспечивающие поддержание целостности данных. Все объекты объявляются специальными предложениями ЯОД. Определения объектов заносятся в системный каталог и используются СУБД при управлении данными.
Ниже, следуя [1], мы приводим синтаксис предложений определения доменов и отношений во входном ЯОД гипотетической СУБД, поддерживающей все требования РМД.
Область определения
. Переменная-кортеж t определяется фразой:
RANGE OF t IS X1, X2, …, Xn;
где t– имя переменной-кортежа;
Xi – имя отношения или выражение исчисления кортежей.
Все Xi должны быть совместимы по объединению. Переменная t принимает значение на объединении X1 È X2
È… È
Xn.
Обычно список элементов области определения – это одно отношение. Например, предложение
RANGE OF SX IS S;
указывает область определения переменной SX
– отношение S.
Вот более сложный случай.
RANGE OF SPJX IS SPJ;
RANGE OF SY IS (SX) WHERE SX.Ci = ‘Яя’,
(SX) WHERE
EXISTS SPJX (SPJX.S# = SX.S#
AND SPJX.P# = ‘P1’);
Переменная SY принимает значения на множестве кортежей отношения S, относящихся к поставщикам, расположенным в Яе или поставляющим деталь Р1.
Обозначения
.1 Обозначения. Под сущностью в IDEF1Х понимается отношение. Сущности изображаются на диаграммах именованными прямоугольниками, в которые вписываются имена атрибутов. Используемые обозначения определены на рис. 4.1.
 |
Рис. 4.1Обозначения сущностей и атрибутов
На ER-уровне независимые и зависимые сущности не различаются, атрибуты не указываются, а имена сущностей вписываются в обозначающие их прямоугольники.
Никакого специального синтаксиса доменов в графическом языке не предусмотрено. Домены определяются независимо от сущностей и диаграмм на основании требований ПО.
Общая характеристика
.
Реляционная алгебра (РА) – один из имеющихся в РМД механизмов манипулирования данными на уровне множеств кортежей.
Первый вариант набора операций РА был предложен Э.Коддом в 1970 г. Он содержал 8 операций. Позднее различными авторами были предложены различные дополнения этого набора. Мы здесь познакомимся с операторами, обеспечивающими основные потребности манипулирования данными.
Операндами операций РА являются отношения. Всякая операция РА производит отношение, формируя по определенным правилам схему и тело производного отношения из атрибутов и кортежей операндов.
Реляционная алгебра замкнута относительно множества отношений. Из имен отношений, знаков операций РА и скобок можно строить выражения произвольной степени сложности. Очень сложные запросы к реляционной БД можно сформулировать в виде одного выражения РА. Поэтому реляционная алгебра обладает большой выразительной мощностью.
Общая характеристика модели
Общая характеристика модели
Реляционная модель данных (РМД) состоит из трех частей – структурной, целостностной и манипуляционной[8].
· Структурная часть ставит в соответствие концептуальным понятиям, введенным в п. 1.4, строго определенные математические объекты – реляционные структуры данных. Она является абстрактным языком описания данных.
· Целостностная часть определяет правила, которым должны подчиняться хранящиеся в реляционных структурах непротиворечивые правдоподобные данные.
· Манипуляционная часть определяет абстрактные языки манипулирования данными в реляционных структурах на уровне множеств.
РМД поддерживает только концептуальный уровень представления данных (см. п. 1.3.3).
Все понятия структурной и целостностной частей РМД используются в современных графических ЯОД
(см. гл.4) – входных языках компьютерных систем автоматизированного проектирования баз данных. Многие понятия РМД положены в основу SQL – входного языка современных коммерческих СУБД, обеспечивающего управление данными в БД на концептуальном уровне.
Модель предложена американским математиком Е. Коддом в 1970 году. За три десятилетия она претерпела некоторые изменения. Здесь, в основном в соответствии с [1], изложены современные представления. Определения реляционных ЯОД и ЯМД ориентированы на гипотетическую СУБД, поддерживающую все реляционные возможности. Следует иметь в виду, что ни одна коммерческая СУБД, называемая «реляционной», не поддерживает РМД в полном объеме. Однако тенденции развития этих систем таковы, что можно надеяться на появление «настоящих» реляционных СУБД (РСУБД) в недалеком будущем.
Операции обновления и целостность данных
[20] В любой реляционной БД имеется три типа операций обновления базовых отношений:
· INSERT – вставить кортеж в отношение;
· DELETE – удалить кортеж из отношения;
· UPDATE – обновить значение атрибута(ов) в кортеже.
Таблица 2.1 показывает, какие типы ограничений целостности могут ими нарушаться.
Таблица 2.1-
Возможные нарушения ограничений целостности
| Целостность домена | Целостность сущности | Ссылочная целостность | |||||
| INSERT | ДА | ДА | ДА | ||||
| DELETE | НЕТ | НЕТ | ДА | ||||
| UPDATE | ДА | ДА | ДА |
Таким образом, выполнение операций INSERT и UPDATE должно сопровождаться (в общем случае) проверками всех трех типов правил целостности. При выполнении операции DELETE
необходимо проверять только ссылочную целостность. Будем считать, что наша гипотетическая РСУБД имеет модуль контроля обновлений, инициируемый любой из команд – INSERT, UPDATE или DELETE, и запускающий нужные процедуры контроля целостности.
Операции реляционной алгебры
.
Поскольку отношения – это множества, то операции РА основаны на теоретико-множественных операциях. Однако отношения – множества с особыми свойствами, поэтому в РА входят также специфические операции, которые могут быть определены только на множествах отношений. Выделяют две группы операций РА.
Теоретико-множественные операции:
· объединение;
· разность;
· пересечение;
· расширенное прямое произведение.
Специальные реляционные операции:
· переименование;
· селекция (ограничение, выборка);
· проекция;
· соединение по условию;
· естественное соединение;
· взятие реляционного частного (реляционное деление).
Этот набор операций избыточен, так как некоторые из них выражаются через другие. Тем не менее, все они включаются в состав алгебры как элементарные, исходя из интуитивных потребностей пользователей БД. В этом подразделе приведены формальные определения операций, а в следующем – синтаксис абстрактного языка РА.
Специфика отношений накладывает ограничения на операции. Так, операндами операций объединения, взятия разности
и пересечения могут быть только отношения с эквивалентными схемами.
Определение 1.
Говорят, что отношения R1
и R2 совместимы по объединению, если R1( ) = R2( ).
Операндами операции расширенного прямого произведения могут быть только отношения с непересекающимися схемами.
Определение 2.
Говорят, что отношения R1
и R2 совместимы по взятию расширенного прямого произведения, если
R1( ) Ç
R2( ) = Æ.
Операция подведения итогов
. Это также унарная операция. Ее синтаксис определим так:
| подведение-итогов ::= SUMMARIZE терм BY (список) ADD | |
| агрегатное-выражение AS атрибут1; |
Здесь список – список атрибутов, по которым производится группирование;
агрегатное-выражение
– скалярное выражение, возвращающее единственное значение для группы кортежей;
атрибут – атрибут схемы производного отношения, определенный на значениях агрегатного-выражения.
Операция SUMMARIZE значительно сложнее операции EXTEND. Поясним ее действие. Пусть R – отношение со схемой, содержащей атрибуты A1, A2, ..., An, по которым нужно подвести итог. Выражение
SUMMARIZE R BY (A1, A2, ..., An) ADD exp AS Z;
произведет безымянное отношение со схемой {A1, A2, ..., An, Z}. Тело этого отношения будет содержать все кортежи проекции отношения R на атрибуты A1, A2, ..., An, дополненные значениями атрибута Z. Значение атрибута Z в кортеже t производного отношения является значением выражения exp. Оно вычисляется на подмножестве всех таких кортежей отношения R, в которых значения атрибутов A1, A2, ..., An совпадают со значениями соответствующих атрибутов в t. Концептуально эту процедуру можно представить как формирование групп кортежей R с одинаковыми значениями атрибутов A1, A2, ..., An
и вычисление значения exp для каждой группы.
Выражение exp содержит ссылки на агрегатные функции, возвращающие скалярные значения, вычисленные для группы кортежей операнда. Имеет смысл ввести такие агрегатные функции, которые выполняют вычисления, часто встречающиеся при подведении итогов:
| COUNT | число значений атрибута; | ||
| SUM | сумма значений атрибута; | ||
| AVG | среднее арифметическое значений атрибута; | ||
| MAX | максимальное значение атрибута; | ||
| MIN | минимальное значение атрибута. |
Пример:
SUMMARIZE SPJ BY (S#, P#) SUM(Qt) AS Tot_Qt;
Это выражение производит отношение со схемой {S#, P#, Tot_Qt}. Тело отношения для каждой пары значений {S#, P#}, встретившейся в SPJ хотя бы один раз, будет содержать ровно один кортеж с соответствующими значениями номера поставщика, номера детали и суммарного объема поставок этой детали этим поставщиком независимо от того, для каких изделий и когда он поставлял этот вид детали.
Операция расширения схемы
. Это унарная операция. Она производит безымянное отношение со схемой, включающей все атрибуты операнда и, кроме того, атрибут, принимающий значения некоторого скалярного выражения. Операция обеспечивает возможность выполнения «горизонтальных вычислений». Будем использовать для нее следующий синтаксис:
| расширение
::= EXTEND терм ADD выражение AS атрибут[24]; |
Здесь выражение – любое скалярное выражение, ссылающееся на атрибуты терма.
Очевидны следующие ограничения:
1) схема терма не может содержать атрибута с именем, указанным после AS;
2) выражение не может ссылаться на атрибут.
Пример:
EXTEND (( P JOIN SPJ) ADD We*Qt AS Tot_We)
[SPJ#, Tot_We];
Это выражение произведет безымянное отношение со схемой {SPJ#, Tot_We}. Его кортежи будут содержать сведения о весах зарегистрированных поставок.
Оператор обновления значений атрибутов
. Синтаксис для этого оператора следующий:
| UPDATE приемник список-присваиваний; | |
| список-присваиваний
::= атрибут := скалярное-выражение | | |
| список-присваиваний, атрибут := скалярное-выражение |
Здесь приемник
– любое реляционное выражение. Каждый атрибут из списка присваиваний принадлежит приемнику.
Все кортежи приемника обновляются в соответствии с указанным списком присваиваний.
Пример:
UPDATE (S WHERE Ci = ‘Яя’) St := St*10;
Будут обновлены значения атрибута St во всех кортежах отношения S, удовлетворяющих условию Ci = ‘Яя’.
Оператор удаления кортежей
. Оператор удаления кортежей имеет вид:
| DELETE приемник; |
Здесь приемник
– любое реляционное выражение.
Удаляются все кортежи целевого отношения, произведенного приемником.
Пример:
DELETE (S WHERE Ci = ‘Яя’);
Будут удалены все кортежи отношения S, содержащие сведения о поставщиках, размещенных в Яе.
Реляционные выражения, встречающиеся в операторах INSERT, UPDATE, DELETE, определяют область действия этих операторов. Как правило, эти выражения оказываются либо именами базовых отношений, либо подмножествами кортежей этих отношений. Однако, в принципе, они могут определять какую угодно часть БД.
Подчеркнем, что операции обновления действуют на уровне множеств кортежей. Даже когда обновляется один кортеж, на самом деле обновляется множество, состоящее из одного элемента. Иногда обновление одноэлементного множества невозможно.
Например, в нашей БД может существовать ограничение целостности: «Все поставщики из Яи имеют одинаковые статусы».
Тогда операция
UPDATE (S WHERE S# = ’S1’) St := 50;
не может быть выполнена на уровне одного кортежа, если поставщик S1 размещается в Яе и есть еще поставщики из Яи. Такая операция должна быть либо преобразована системой в операцию
UPDATE (S WHERE Ci = ‘Яя’) St := 50;
обновляющую все кортежи, соответствующие поставщикам из Яи, либо отвергнута в соответствии с определенным правилом целостности.
Оператор вставки кортежей
. Синтаксис для оператора вставки кортежей определим так:
| INSERT источник INTO приемник; |
Здесь приемник
и источник
– любые реляционные выражения, производящие отношения, совместимые по объединению.
Все кортежи источника вставляются в приемник.
Пример:
Пусть в схеме нашей БД определено отношение TEMP
со схемой {P#, TOTAL}. Оператор
INSERT ((SUMMARIZE SPJ BY (P#) SUM (Qt) AS TOTAL)
WHERE TOTAL > 10000) INTO TEMP;
вставит в отношение TEMP
все кортежи отношения, произведенного операцией SUMMARIZE.
Операторы обновления данных
.
Для обновления данных в БД требуются операции вставки и удаления кортежей и изменения значений атрибутов в существующих кортежах базовых отношений. Они не входят в состав операций РА. Мы приводим здесь синтаксис соответствующих операторов для того, чтобы показать, как реляционные выражения можно использовать для определения области обновления данных.
Переименование атрибутов
. Эта операция вводится в состав операций РА для разрешения конфликтов имен в бинарных операциях. В реальных манипуляциях реляционными данными нередко возникает необходимость вычислить соединение по условию отношений с пересекающимися схемами или построить объединение отношений с «почти совпадающими» схемами, отличающимися только именами атрибутов и т.п.
Эта операция сохраняет тело отношения, изменяя лишь имена указанных атрибутов:
rА ®С (R (A, B)) = R (C, B).
Пересечение отношений
Пересечение отношений. Пусть отношения R1 и R2 совместимы по объединению. Отношение R называется пересечением отношений R1
и R2, если его схема эквивалентна схемам операндов, а тело составлено только из кортежей R1, принадлежащих R2.
R = R1
Ç R2 = {SR : R( ) = R1( ) = R2( ), SR Î R1
Ù
SR Î R2}.
Пример:
| A | B | A | B | A | B | ||||||||||||||||
| R1 = | a1 | b1 | , | R2 = | a1 | b1 | , R1 Ç R2 = | a1 | b1 | . | |||||||||||
| a2 | b2 | a1 | b2 | a1 | b2 | ||||||||||||||||
| a1 | b2 | a2 | b3 |
Это неэлементарная операция. Она представляется через операции объединения и разности:
R1 Ç R2 = R1 È R2 – (R1 – R2) È
(R2 – R1 ).
Первая нормальная форма
3.3.1 Первая нормальная форма (1НФ).
Говорят, что отношение находится в первой нормальной форме, если и только если все домены его атрибутов содержат скалярные значения.
Любое отношение РМД находится в 1НФ по определению (см. пп. 2.2.1, 2.2.3).
Рассмотренное выше отношение USPJ находится в 1НФ. Как мы видели, в таком отношении возможно избыточное дублирование данных и аномалии обновления. Некоторые его атрибуты могут функционально зависеть от части возможного ключа. Могут существовать ФЗ между атрибутами, не входящими в состав возможного ключа.
Поддержание целостности в РБД
.
Любое состояние РБД, не удовлетворяющее требованиям целостности, некорректно. На вопрос о том, как избегать подобных состояний, общего ответа нет. В каждом конкретном случае это должен решать проектировщик БД. Определение конкретных правил целостности – его задача. Ниже излагаются некоторые общие идеи, лежащие в основе механизмов поддержания целостности РСУБД.
Подходы к концептуальному моделированию
Подходы к концептуальному моделированию
Задача проектировщика БД на этапе концептуального моделирования состоит в том, чтобы на основании локальных представлений пользователей найти обобщенное представление информации, свойственное природе ПО как целого.
Для этого необходимо выполнить анализ ПО, то есть:
·
уяснить цели предприятия, для которого создается БД;
· выявить функции или действия, направленные на достижение целей, и правила бизнеса, принятые на предприятии;
· выявить данные, необходимые для выполнения функций;
· выделить объекты, вовлеченные в деятельность, и выявить связи между ними.
Результатом анализа является концептуальная (информационная) модель ПО. С точки зрения проектировщика она содержит спецификации логического макета БД – определения базовых отношений и правил целостности данных. Как мы уже отмечали в главе
Понятие целостности данных
. Выше мы определили базу данных как модель некоторой части реального мира. Она отражает реальное состояние ПО в любой фиксированный момент времени в виде текущей конфигурации хранимых данных. Очевидны два основных требования к этой конфигурации.
· Любое хранимое в БД значение любого семантически значимого атрибута в любой момент времени должно быть истинным значением характеристики соответствующего объекта ПО.
· Состояние БД в любой момент времени должно иметь осмысленную интерпретацию в терминах ПО.
Текущее состояние БД является целостным, если возможна осмысленная интерпретация его в терминах ПО.
Естественно попытаться возложить на СУБД как можно больше забот по поддержанию целостности. Для того чтобы вполне понять, о чем идет речь, рассмотрим пример.
