Корпоративные базы данных - статьи
Моделирование процессов
Диаграммы потоков данных, создаваемые в SILVERRUN, соответствуют современному развитию
принципов структурного анализа. В системе имеется возможность изменять внешний вид символов
диаграмм и выбирать отображаемые в них дескрипторы, включая определяемые пользователем. На рис. 1 показан экран определения нотации модуля BPM. Также можно выбирать
набор правил, проверяемых процедурой анализа корректности модели. В SILVERRUN встроено
несколько предопределенных нотаций и наборов правил, соответствующих наиболее известным методам
построения DFD: Gane/Sarson, Yourdon/DeMarco, Merise, Ward/Mellor.

Моделируются бизнес-процессы
Пояснять, что такое бизнес-процессы в документообороте, вряд ли нужно - каждый специалист
сталкивается с ними ежедневно. Например, бизнес-процесс покупки материалов состоит из
получения счета, его оплаты, получения материалов по накладной и их оприходования на
склад. Этому сопутствует оформление и подписание определенного набора документов
состоит вся оперативный документооборот предприятия. Корпоративные системы нового
поколения позволяют предприятию самостоятельно моделировать в системе свои бизнес-
процессы. Это значит, что, продумывая внедрение нового бизнес-процесса, руководитель
самостоятельно или с помощью своего специалиста по компьютерам описывает его в своей
корпоративной системе, определяя при этом, какие документы участвуют в процессе и кто из
специалистов отвечает за действия с этими документами. Больше руководителю не придется ни
инструктировать своих специалистов, ни контролировать последовательность действий или
правильность оформления документов - система просто не позволит персоналу делать ошибки
или нарушать технологию работы.

Наиболее примечательные возможности S-Designor
Чем хорош и примечателен S-Designor? В первую очередь тем, что это - профессиональное
средство информационного моделирования и разработки структур данных. Помимо "широко
известных" функций для CASE-средств такого уровня добавлены мощные средства групповой
разработки и генерация приложений для целевых средств разработки. Примечателен S-
Designor тем, что концептуально целостно построен и имеет строгую практическую
направленность. Ниже освещены некоторые наиболее интересные возможности S-Designor.
Направления дальнейшего развития
Дальнейшее развитие PowerBuilder связывается с новой версии 5.0, которая должна появиться в первой
половине 1996 года.
В новой версии будет реализована компиляция приложений в машинный код, что может существенно
повысить производительность приложений с интенсивными вычислениями или сложной логикой.
Технология компиляции будет основана на богатом опыте канадской фирмы Watcom по разработке
компиляторов.
Новая версия выйдет для платформ Windows 95, Windows NT, Windows 3.X и будет поддерживать
разработку как 32, так и 16 разрядных приложений. На платформе NT будут поддерживаться
двухбайтовые символы. Затем последуют версии PowerBuilder для UNIX и Macintosh. В новой версии
реализована полная поддержка элементов управления Windows 95, таких, как диалоги с закладками,
иерархические списки и т.д. Полностью поддерживается OLE 2.0.
Добавлена возможность построения многоуровневых приложений средствами PowerBuilder,
распределяя различные компоненты приложений по сети. Для передачи данных будут поддерживаться
протоколы Winsock, Named Pipes и Sybase Open Client/Server.
Расширены возможности PowerScript, пополнился список встроенных функций. Улучшены Окна
Данных, которые теперь смогут отображать информацию из базы данных непосредственно
используя элементы управления OLE (OCX) или в формате RTF.
Новая версия PowerBuilder обещает стать надежным основанием для разработок сложных приложений
клиент/сервер масштаба предприятия.
[]
[]
[]
Настройка режимов отображения
Диаграммы информационных моделей современных информационных систем обычно весьма велики,
вследствие чего работать со всей диаграммой достаточно сложно как на стадии проектирования
информационной модели, так и при разработчикам прикладного программного обеспечения. ERwin
дает возможность работать не со всей диаграммой, а с логически законченной группой сущностей,
называемой предметной областью (Subject Area). Переключение отображения с одной предметной
области на другую производится выбором из раскрывающегося списка.
Например, рассмотрим информационную модель для некоторого абстрактного предприятия. В
информационной системе задействованы бухгалтерия, склад, кадры. В этом рассмотренные в первом
примере сущности (сотрудник, история работы, доход) могут быть выделены в отдельную предметную
область "кадры".
Такой подход обладает рядом важных преимуществ. Во-первых, группа разработчиков программного
обеспечения снабжается диаграммой той предметной области, с которой она работает. Во-вторых, при
разработке информационной модели проектировщик может удалить с экрана уже спроектированные
блоки, чтобы они не загромождали диаграмму. В-третьих, использование предметных областей
стимулирует структурный подход к разработке информационной модели, то есть выделение
логических блоков с последующей их детальной разработкой.
Уровень детализации диаграммы информационной модели может изменяться проектировщиком.
Например, могут отображаться только имена сущностей (таблиц), может быть включено/выключено
отображение мощности связи, может быть включено/выключено отображение альтернативных
ключей, может отображаться физическая или концептуальная модель. Для удобства проектировщика
предусмотрена возможность присвоить имя группе параметров отображения. Определенные
пользователем имена показываются на экране в виде закладок, что обеспечивает переключение с
одного режима отображения на другой одним щелчком мыши.
Проектировщик информационной модели имеет возможности использовать цветовое и шрифтовое
выделение для различных компонентов диаграммы. Выделение может быть выполнено как для всей
модели (например, все внешние ключи отображать синим цветом), так и для отдельного компонента
(одна таблица, все атрибуты таблицы, один атрибут таблицы, одна связь и т.д.). Использование
цветового и шрифтового выделения на диаграмме информационной модели делает ее более наглядной
и позволяет проектировщику обратить внимание читателей диаграммы на ее отдельные
элементы.
Несколько процессов, работающих с сетевыми соединениями
В предыдущей версии Sybase System 10 сетевым обменом занимался только один процессор в SMP-
архитектуре. Это ограничивало масштабируемость сервера на симметричной мультипроцессорной
архитектуре, так как было "узким местом" при увеличении числа процессоров. В версии Sybase
System 11 сетевым обменом могут заниматься все процессоры.
Несколько выводов
Если попытаться сделать выводы из всего описанного выше, то необходимо прежде всего отметить
следующее:
Входящий в состав VantageTeam Builder кодогенератор является весьма
мощным и гибким средством, позволяющим свести значительную долю рутинной
работы программиста по написанию программ "по образцу" к однократному
написанию этих самых образцов. Причем в отличие от многих билдеров вы
можете непосредственно видеть сгенеренный текст и вносить изменения как в
него, так и в те шаблоны, по которым он генерится.
VantageTeam Builder в комплекте с генератором GRINDERY позволяет
использовать один и тот же проект для генерации приложений на таких различных
языках, как Informix-4GL, NewEra и SuperNOVA. Это, в частности, позволяет
упростить переход от Informix-4GL к NewEra и само освоение объектных подходов
к разработке приложений.
NewEra как универсальный язык программирования
Программа на языке NewEra состоит из одного или нескольких файлов (модулей). Различаются
программные и заголовочные модули. Оператор INCLUDE "имя_файла" позволяет включить в
тело модуля текст другого файла. Имеется стандартный набор управляющих операторов.
Определены интерфейсы для вызовов С-функций из программ NewEra и функций NewEra из
программ на языке С.
Множество встроенных типов данных NewEra соответствует набору типов данных,
поддерживаемых СУБД Informix, и включает, в частности, типы данных для работы с большими
бинарными объектами.
NewEra автоматически выполняет все осмысленные преобразования типов при присваиваниях,
передаче параметров или возврате результатов функций.
Поддерживаются записи и многомерные массивы - два вида структурных необъектных типов,
унаследованных от языка Informix-4gl.
NewEra - новая линия инструментальных средств компании Informix
Н. Вьюкова
Средства разработки приложений и средства доступа к базам данных для конечного пользователя
занимали значительное место в деятельности компании Informix с момента ее зарождения. Спектр
продуктов Informix в этой области охватывает потребности и предпочтения самых разных групп
разработчиков - от профессионалов до прикладных специалистов, не имеющих навыков
программирования. Ниже перечислены исторические предшественники Informix-
NewEra:
Informix-SQL - инструмент программирования на языке SQL.
Informix-ESQL/C - среда программирования на языке С со встроенным SQL.
Informix-ESQL/COBOL - среда программирования на языке COBOL со
встроенным SQL.
Informix-4GL - инструмент программирования на языке 4-го поколения (4GL)
со встроенным SQL, включает компилятор языка 4GL, средства построения
экранных форм и меню.
Informix-4GL-RDS+ID - версия Informix-4GL со средствами быстрой
разработки (RDS) и интерактивной отладки (ID).
Informix-HyperScript Tools - инструмент создания приложений в среде
Windows, Unix и др. Позволяет программировать меню, диаграммы,
электронные таблицы, экранные формы.
Informix-ViewPoint - средство доступа к базам данных, позволяет
непрограммным способом создавать графические формы, отчеты,
запросы.
Informix-NewEra - последнее "детище" Informix в области средств разработки, на котором
сосредоточены в настоящее время значительные усилия компании. Сохранив определенную
преемственность по отношению к продуктам линии 4GL, NewEra обладает рядом принципиально
новых свойств, важнейшие из которых - объектная ориентация и инструментарий визуального
программирования.
Приложения, создаваемые в среде Informix-NewEra, имеют архитектуру клиент-сервер и могут
использовать СУБД Informix или другие СУБД, доступные посредством интерфейса ODBC.
Продукт представляет собой комплекс графических и языковых средств, позволяющих описывать
модели данных, строить компоненты графического пользовательского интерфейса и задавать их
поведение, программировать объекты и процедуры обработки данных, собирать и отлаживать
приложения. Важнейшие характеристики Informix-NewEra:
Многоплатформность, кросс-платформность. Informix-NewEra работает
в системах MS Windows, OSF/Motif и Macintosh. Приложения или компоненты
приложений, разработанные на одной платформе, могут работать на других
платформах.
Объектно-ориентированный характер инструмента. Преимущества данного
подхода - переиспользуемость кода, бизнес-моделирование, хорошая
приспособляемость приложений к меняющимся требованиям, простота
сопровождения, интегрируемость с библиотеками от независимых
поставщиков. Допустимо использование внешних библиотек, разработанных на
С и С++.
Поддержка наряду с объектно-ориентированными разработками
традиционного структурного программирования.
Поддержка групповых разработок. Программисты совместно используют
библиотеки, файлы исходных кодов и ресурсов. Возможно применение
системы управления версиями и конфигурациями PVCS (Intersolv).
Стилистическое единообразие пользовательского интерфейса
обеспечивается за счет механизма наследования и поддержания репозитория
данных. В репозитории хранятся такие элементы интерфейса, как цветовое и
шрифтовое оформление, маски ввода и форматы вывода данных, правила
верификации, заголовки и метки столбцов, используемые при выводе, и т. п.
Открытость создаваемых приложений по отношению к используемой СУБД.
В комплект поставки входят библиотеки взаимодействия с СУБД Informix, а
также с СУБД, доступными через интерфейс ODBC. Определен объектный
интерфейс для создания других аналогичных библиотек доступа к СУБД.
Преемственность по отношению к Informix-4gl. Благодаря существенной
совместимости языков NewEra и 4gl, возможен перенос приложений 4gl в среду
Informix-NewEra.
Возможность создания распределенных многозвенных приложений, в
которых обработка данных отделена от обслуживания интерфейса с
пользователем.
Комплекс Informix-NewEra включает следующие инструментальные средства:
Инструменты визуального программирования - генератор окон и генератор составных
органов управления;
Компиляторы и интерпретатор языка NewEra;
Компилятор файлов сообщений и справок;
Генератор приложений;
Интерактивный символьный отладчик программ на языке NewEra;
Электронная документация, доступная в интерактивном режиме;
Набор примеров элементарных приложений (рецептов);
Демонстрационные базы данных;
Вспомогательный продукт Informix-NewEra ViewPoint Pro, который содержит;
инструменты администрирования баз данных и репозитория данных NewEra;
средства для построения простых приложений без программирования на SQL или каких-
либо других языках.
Подробные характеристики основных компонентов Informix-NewEra приведены в последующих
разделах.
В предположении, что необходимая база данных уже создана, технологическая цепочка
построения приложений в NewEra состоит из следующих шагов:
Используя средства администрирования ViewPoint Pro, создать
репозиторий приложения, описав в нем связи между таблицами, атрибуты
внешнего представления данных для таблиц и столбцов - шрифты, цвета,
заголовки и т. п.
Создать при помощи визуальных инструментов макет прикладной системы
в виде серии окон, отражающей общую структуру приложения и
пользовательский интерфейс. Описать поведение органов управления окон.
Создать программные модули, реализующие классы и процедуры для
содержательной обработки данных и поддержки некоторых компонентов
пользовательского интерфейса.
Создать файлы сообщений, используемые в приложении.
Создать новый проект в рамках генератора приложений, собрать
приложение.
Отладить его при помощи отладчика, возвращаясь по мере необходимости
к предыдущим шагам.
NonStop SQL/MP: Параллельная система управления реляционными базами данных
Ричард Галдерман, Tandem Computers
(Тезисы доклада)
В докладе рассматриваются следующие вопросы:
повышение производительности труда программистов на основе
поддержки открытых стандартов;
параллельная реализация, обладающая полными свойствами
масштабируемости;
надежная, высокодоступная база данных;
оптимальная производительность для наиболее критичных приложений.
В первой части доклада обсуждается основной набор открытых стандартов, поддерживаемых в
NonStop SQL/MP. В частности, внимание уделяется возможностям локализации системы с
использованием национальных языков.
Вторая часть посвящена архитектурным особенностям системы. Основными качествами
архитектуры являются ее параллельность архитектуры и высокая степень масштабируемости.
Этому способствует наличие автоматической оптимизации запроса основанная на языке SQL, в ходе
которой оценивается целесообразность распараллеливания выполнения запроса.
В третьей части речь идет об особенностях системы, обеспечивающих надежность и высокую
доступность баз данных. Рассматриваются приемы, с помощью которых гарантируется
целостность баз данных. Высокий уровень доступности достигается с помощью специальных
операций управления БД, использованием механизмов версий и репликации.
Наконец, четвертая часть доклада связана главным образом с возможностями системы,
обеспечивающими оптимальную эффективность выполнения запросов. Основное внимание
уделяется параллельной реализации таких трудоемких операций как соединения и вычисление 0
функций.
[]
[]
[]
Новые средства администрирования
Для управления из единой точки многосерверной распределенной средой нужны новые средства
администрирования. Поэтому вместе с Oracle 7.3 будет поставляться такое средство -
ENTERPRISE MANAGER. Он придет на смену утилите Server Manager. Enterprise Manager имеет
GUI интерфейс. Он позволяет анализировать состояние и управлять сетью, администрировать все
узлы многосерверной архитектуры Oracle, управлять запуском и выполнением работ в различных
узлах (в том числе и по заранее заданному расписанию), описывать события на серверах, которые
интересуют администратора, контролировать возникновение этих событий, а также описывать
действия, которые будут выполняться при возникновении событий. Например, при переполнении
tablespace на сервере А, там будет автоматически выполняться команда расширение
tablespace.
Enterprise Manager позволяет также выполнять тиражирование нового программного обеспечения
в различные узлы сети и вести учет того, какие версии программ работают в разных узлах.
Открытый интерфейс Enterprise Manager позволяет подключать к нему как Ваши полезные
программы для администрирования, так и средства других фирм.
Enterprise Manager состоит из базовой части - консоли и группы дополнительных компонент
(applications). Консоль реализует стандартные функции Server Manager по управлению instance,
объектами и схемами, безопасностью (привилегии, роли, профили), хранением данных (tablespace,
rolsback, ...), репликацией, распределением новых версий программ, сетью. Консоль также
позволяет запускать копирование/восстановление БД, экспорт/импорт и загрузчик. Можно
выполнять и команды SQL или скрипты.
Дополнительные компоненты позволяют выполнять мониторинг и настройку БД, собирать
статистику, просматривать и реорганизовывать пространство в tablespace. Особенно интересна
компонента Performance Monitor, идущая на смену режиму Monitor в SQL DBA. Она не только
позволяет динамически отслеживать состояние баз данных, но и представит его в виде диаграмм, а
также соберет статистику, на основе которой еще одна компонента Oracle Expert выдаст Вам
рекомендации по настройке БД и подготовит скрипты, выполняющие эту настройку.
Так что Enterprise Manager возьмет на себя выполнение многих задач по администрированию БД,
которые сегодня приходится выполнять вручную. Он сильно упростит и изменит управление
сложной распределенной БД.
| Oracle7 Server | Trusted Oracle7 | Parallel Server Option |
| Parallel query Option | Advanced Replication Option | Distributed Option |
| Text Server Option | Video Option | WebServer Option |
| Spatial Data Option |
| Developer/2000 | Oracle CALL interface | |
| Oracle Forms | Translation Manager | |
| Oracle Reports | SQL*Module | |
| Oracle Graphics | Oracle Precompiler (C, Cobol, PL/I,Ada, Pascal) | |
| Oracle Book | ||
| Oracle Browser | ||
| Procedural Builder | ||
| SQL*Plus |
| Descoverer/2000 | Oracle Office | |
| Oracle Browser | Oracle Office MHS Gateway | |
| Oracle DataQuery |
| TextServer with Context |
| Designer/2000 | Oracle CASE Exchange | |
| Process Modeller | ||
| System Modeller | ||
| System Designer | ||
| Wizards | ||
| Server Generator | ||
| Forms Generator | ||
| Reports Generator |
| Oracle Express Server | Oracle Financial Analyzer |
| Oracle Sales Analyzer | Oracle Analyzer |
| Oracle MultiProtocol Interchange | Oracle Network Manager |
| Sequre Network Services | Oracle Names Server |
| Protocol Adapters (TCP/IP, SPX/IPX, DecNet, Async, NetBios, Named Pipes, LU6.2, APPC, Banyan Vines, X25, AppleTalk, DCE) |
| ODBC Driver | Transparent Gateways |
| Oracle Glue | Procedural Gateway |
| Oracle Objects for OLE |
| Personal Oracle7 | Workgroup Server7 |
| Oracle Power Objects |
| Oracle Manufacturing | Oracle Human Resources |
| Oracle Financial |
| Oracle Media Objects | Oracle Mobile Agents |
| Oracle Power Viewer |
[]
[]
[]
Новые возможности и тенденции
С.Кузнецов, Центр Информационных Технологий, Открытые системы ()
Не будучи сотрудником какой-либо компании, производящей развитые средства управления базами данных и обладая по этому поводу полной независимостью при выражении собственного мнения, прежде всего отмечу, что на мой взгляд за последний год ничего чрезвычайного в технологии баз данных не произошло. Видимо, так и должно быть, когда средства управления базами данных на наших глазах превращаются в хотя и дорогостоящие, но вполне обыденные программные продукты. Для широкой массы пользователей гораздо более важно научиться производить (или хотя бы использовать) прикладные программные системы, чем погружаться вглубь замысловатых внутренних методов и алгоритмов.
Все это верно, но как и всегда, не совсем. Можно выделить несколько основных факторов, которые влияли на технологию управления базами данных и построения информационных систем в прошедшем году.
Первый фактор состоит в постепенном, эволюционном внедрении сравнительно новых технологий в наиболее известные программные продукты управления базами данных. Компании Oracle, Informix, Sybase, IBM, Computer Associates хотя и разными способами оснащают свои серверы объектными механизмами.
Informix и Computer Associates приобрели готовые постреляционные системы и произвели их интеграцию со своими реляционными серверами.
Компания Informix выбрала объектно-реляционное направление развития, приобретя систему (и компанию целиком) Illustra. В течение года была выполнена интеграция этой системы с сервером OnLine, результатом чего стало появление объектно-реляционного Универсального Сервера. Похоже, что Informix наиболее близко подошел к уровню все еще не появившегося стандарта SQL-3.
Компания Computer Associates решила использовать объектно-ориентированный подход для развития своего серверного продукта CA-OpenIngres. CA использует объектно-ориентированную систему Jasmine компании Fujitsu. В отличие от Informix, компания CA не стала производить интегрированный сервер.
Вместо этого обеспечивается возможность доступа к реляционным базам данных OpenIngres в объектно-ориентированном интерфейсе системы Jasmine. Если учитывать, что CA через систему шлюзов уже сравнительно давно обеспечивает доступ из OpenIngres к таким распространенным "унаследованным" базам данных как CA-Datacom, CA-IDMS, IMS и т.д., то фактически, через Jasmine обеспечивается доступ и к таким базам данных.
Компании Oracle, Sybase и IBM также объявляют о переходе к постреляционным механизмам доступа к данным, базируясь на объектно-реляционном подходе. Однако эти компании эволюционизируют свои продукты, не прибегая к приобретению готовых постреляционных систем, а развивая собственные программные средства (часто в сотрудничестве с другими компаниями).
В целом можно сказать, что постреляционные системы, как правило, были зарождены в университетах, прошли довольно долгий путь малотиражного коммерческого использования и, наконец, начинают внедряться в мощные, развитые и широко используемые серверные продукты. Естественно, возрастающее использование постреляционных СУБД в информационных системах вызовет появление нового класса инструментальных средств, поддерживающих проектирование и разработку приложений.
Второй фактор заключается в интенсивно развивающемся применении технологии Internet для построения корпоративных систем. Наиболее активно используются информационные службы Всемирной Паутины (World Wide Web - WWW), поддерживающие распределенные гипертекстовые структуры. Web-браузеры предоставляют удобный и легко осваиваемый интерфейс. Базовый язык разработки Web-страниц HTML в совокупности с протоколом взаимодействия Web-сервера и Web-клиента HTTP обеспечивают, в частности, возможности заполнения форм на стороне клиента и передачи заполненных форм серверу.
Естественно, у пользователей появилось желание получить возможность доступа в интерфейсе WWW не только к гипертексту, но и к обычным базам данных. Этого можно добиться разными способами, например, с использованием CGI-скриптов или API на стороне Web-сервера или с применением Java-апплетов на стороне Web-клиента (рис. 1 и рис.2, соответственно).

Рис. 1. Доступ к базе данных на стороне сервера
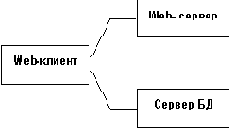
Рис. 2. Доступ к базе данных на стороне клиента
С другой стороны, все большее число ведущих производителей серверов баз данных обеспечивают в своих продуктах встроенные возможности Web-сервера, тесно интегрированные с возможностями управления базами данных. В частности, в последних вариантах серверов INFORMIX-OnLine обеспечивается не только доступ к базам данных через средства WWW, но и возможность хранения HTML-документов в реляционных базах данных.
Как кажется, Internet/Intranet-ориентированные информационные системы - это не дань моде, а полностью экономически обоснованный подход. Соответствующая поддержка со стороны серверов баз данных будет продолжать наращиваться.
Третий фактор - развивающееся применение аналитиками и руководителями корпораций систем оперативной аналитической обработки (OLAP). Для построения таких систем требуется использование очень объемных, накапливаемых в течение долгого времени, обычно хранимых в нескольких разнородных базах данных и многомерных по своей сути складов данных (datawarehouse). Специфика работы со складами данных (очень большой объем, многомерность, частая потребность в агрегированной информации и т.д.) заставляет производителей серверных продуктов применять особую технику, в частности, методы организации индексов, отличных от B-деревьев.
В общем, это в основном все, что характеризовало развитие серверов баз данных и инструментальных средств, поддерживающих разработку приложений, в прошлом году. Как видно, не произошли великие открытия, не было изобретено ничего принципиально нового. Ведется повседневная работа по улучшению качества серверов и в отношении интерфейсов, и в отношении эффективности. Расширяются сферы применения баз данных, поддерживаются новые технологии разработки информационных систем.
[]
[]
В первом квартале 1996 г.
В первом квартале 1996 г. фирма Oracle выпустила новую версию своего сервера - Oracle 7.3. Эта
версия интересна тем, что по многочисленным заявкам пользователей фирма Oracle включила в
нее почти все улучшения, планировавшиеся для Oracle 8. Практически Oracle 7.3 - это Oracle 8 без
поддержки объектно-ориентированной модели данных. Большинство улучшений было направлено
на повышение быстродействия многопользовательской работы, улучшения работы как OLTP так
и DSS приложений, повышение надежности реализуемых прикладных систем. Эти улучшения
позволили серверу Oracle резко поднять производительность ( более 11 тыс. транзакций в минуту
по тесту ТРС C) и достичь на персональных платформах не только лучших показателей по
производительности, но и минимальной стоимости транзакций.
Все улучшения в Oracle 7.3 можно разделить на следующие группы:
улучшение работы для Data Warehouse ( работа с большими таблицами);
улучшение работы с очень большими БД ( свыше 10 терробайт );
улучшение работы для OLTP приложений;
расширение возможностей языков сервера ( PL/SQL, OCI );
новые средства администрирования;
прочее ( сложная репликация, обновляемые View, Multithread приложения).
О современных информационных технологиях
Прежде, чем перейти к непосредственному изложению представленных материалов, кратко
остановимся на основных понятиях и терминах, используемых при описаниях современных
автоматизированных систем (АС).
Объектная модель NewEra
Язык NewEra поддерживает основные возможности объектно-ориентированного
программирования, в частности, наследование и полиморфизм. В языке явно выделены и имеют
специальное синтаксическое оформление понятия "событие в объекте", "обработчик
события".
Объектная модель NewEra допускает более гибкий по сравнению, например, с С++, подход к
проектированию и применению классов, поскольку функциональность объектов может частично
определяться непосредственно в программах, использующих данный класс, причем,
индивидуально для каждого объекта.
Класс объектов NewEra характеризуется
именем
набором констант
набором переменных
набором функций
набором событий
ЗАМЕЧАНИЕ. Во всех последующих примерах программ знаки -- обозначают комментарий до
конца строки.
Пример декларации класса:
CLASS music -- ИМЯ КЛАССА
-- КОНСТАНТЫ:
CONSTANT unknown SMALLINT=0
CONSTANT folk SMALLINT=1
CONSTANT classic SMALLINT=2
CONSTANT pop SMALLINT=4
CONSTANT hard_rock SMALLINT=8
-- ПЕРЕМЕННЫЕ:
PUBLIC VARIABLE music_type SMALLINT
PRIVATE VARIABLE music_title CHAR (32) -- название
PRIVATE VARIABLE music_code BYTE -- внутреннее представление мелодии
-- ФУНКЦИИ:
-- инициализация нового объекта класса music:
FUNCTION music (music_type SMALLINT: unknown,
music_title CHAR(32): NULL)
-- установка названия:
FUNCTION set_title (title CHAR(32))
-- опрос названия:
FUNCTION get_title () RETURNING CHAR(32)
-- установка кода (внутреннего представления) мелодии:
FUNCTION set_code (file_name CHAR(*))
-- СОБЫТИЯ:
-- воспроизведение мелодии
EVENT play ()
END CLASS
Объекты класса создаются при помощи операторов NEW и COPY, примеры:
VARIABLE my_melody MUSIC = NEW music(music::folk, "Калинка")
VARIABLE your_melody MUSIC = COPY my_melody
Допускается определение нескольких различных функций-обработчиков для одного и того же
события данного класса. Обработчики могут присваиваться индивидуальным объектам
динамически.
Объектная технология
Объектная технология PowerBuilder позволяет разработчикам быстро создавать объектно-
ориентированные приложения масштаба предприятия без применения специфических
трудноизучаемых языков программирования. PowerBuilder полностью поддерживает многоуровневое
наследование, инкапсуляцию и полиморфизм.
Для разработчиков информационных систем самым значительным преимуществом объектной
технологии является впечатляющий скачок вверх производительности благодаря многократному
использованию кода. Наследование позволяет усложнить объект-предок и автоматически передавать
добавленные характеристики всем его потомкам. Наследование упрощает также поддержку
приложений и обеспечивает непротиворечивость.
PowerBuilder поддерживает инкапсуляцию, храня объект вместе со всеми его функциями или
программами в виде инкапсулированного объекта. Инкапсуляция автоматически обеспечивается для
любого созданного в PowerBuilder объекта, включая те, которые помещаются внутри других объектов
(например, командная кнопка, расположенная в окне).
PowerBuilder поддерживает полиморфизм, позволяя одним объектам посылать одинаковые
сообщения другим объектам похожих, но неизвестных типов. PowerBuilder также поддерживает
перегрузку функций.
Объектно-ориентированный подход и современные мониторы транзакций
В. Индриков, АО ВЕСТЬ
Объектно-ориентированный подход и мониторы транзакций? А где, собственно, связь? Если с ООП все, вроде бы, ясно, то мониторы - вопрос темный, да и, кажется, вообще из другой области. Зачем они вообще? "А затем," - отвечают нам, - "чтобы обеспечить высокую пропускную способность системы и повышает ее устойчивость к сбоям." "Помилуйте," - локтем отодвигает предыдущего оратора создатель сервера баз данных, - "мы это и без них прекрасно умеем - и на кластерах работаем, и транзакции мониторим." Тут вам и диспут, и острота схватки. Говорят и такое: "Многие ..., кто ... выбирает мониторы транзакций, применяет их не по назначению. Не так часто мониторы транзакций используются ради того, для чего они и предназначены, конкретно - поддержки сотен или тысяч одновременно работающих пользователей - такие внедрения составляют не более 1% рынка. Все остальные примеры свидетельствуют о том, что мониторы занимаются асинхронной передачей сообщений или играют роль связующего программного обеспечения в разнородных средах." (DATABASE Journal, N2 1996 стр. 77, перевод мой).
В этом изречении содержится, как минимум, две мысли. Первая - есть альтернативы мониторам транзакций. Вторая, спорная - мониторы предназначены для обработки тысяч транзакций на одной системе и ничего более. Самое забавное, что и те, кто продает мониторы, чаще всего думают также. И спорю с ними не я, а как раз те, кто применяет эти мониторы, и, если верить тексту, 99% пользователей использует их отнюдь не ради тех возможностей, которые "и так присутствуют в серверах БД." Я даже позволю себе предположить, что они, пользователи, нуждаются в мониторе транзакций, поскольку тот является средой разработки распределенных приложений. Средой, которая, очевидно, имеет какие-то плюсы.
И я даже готов был бы согласиться с тем, что среда эта не является объектно-ориентированной, если бы не обратившее на себя внимание пугающее сходство CSI (Client/Server Interactions) диаграмм в документации на монитор TopEnd и диаграмм сценариев в объектно-ориентированных методах Буча и Fusion.
Речь не о принципиальном сходстве, это полбеды, а об изобразительном - повернув CSI на девяносто градусов против часовой стрелки, вы не найдете разницы, обозначения убийственно идентичны.
Причина в том, что, как только разговор выходит за рамки отношений между классами, а точнее, единственного, пожалуй, рассматриваемого в них вида отношений (наследования), большинство из ныне здравствующих ОО методов (почему-то их постоянно пытаются называть методологиями) предлагают набор изобразительных средств, существенно превосходящий по возрасту ОО подход - сценарии и диаграммы перехода состояний, анализ доменов и т.д. Причем в 3 из 5 случаев оказывается, что наследование существует само по себе, а все остальное - в стороне. Блистательным, с моей точки зрения, примером конгломерата из слабо связанных между собой подходов является метод Гради Буча. Наследование объявляется ключом к объектно-ориентированному подходу, все остальное - "недоразвитым", объектно-базирующимся подходом (вот вам еще одна загадка - что лучше, базироваться на объектах или ориентироваться на них?), и в то же самое время Рамбо (метод OMT) является одним из немногих, кому пришла в голову нестандартная мысль - сценарии и диаграммы перехода суперкласса должны наследоваться в подклассах. Между тем, даже и в этом случае мы далеки от разрешения всех проблем - имеет место эффект расщепления состояния в подклассе (state partitioning - S.Matsuoka, K.Wakita, A.Yonezawa, Inheritance Anomaly in Object-Oriented Concurrent Languages, University of Tokyo, 1991), заставляющий переопределять методы суперкласса. Одной из причин является то, что само понятие "состояние" никак не определяется, поэтому, что означает "унаследовать состояние" или "унаследовать переход", остается за рамками ОО метода. Да и само по себе наследование суть целый букет проблем: self проблема, конфликт с требованием атомарности операций, переписывание (overriding) методов по принципу "все или ничего" вместо декларированного в ООП "уточнения", трудности с интеграцией с СУБД, трудности в реализации множественных представлений (views) и координированного выполнения и т.д. (см, например, M.Askit, M.Bergmans Obstacles in Object-Oriented Development, TRESE Project, University of Twente; H.
Lieberman, Using Prototypical Objects to implement shared behavior, OOPSLA '86).
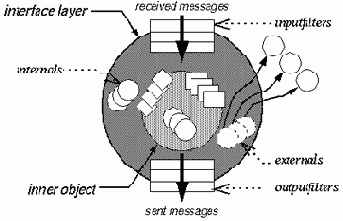
Илл. 1
Крайне интересной попыткой разрешить многие из трудностей с реализацией наследования и на деле позволить применять ООП в больших программных проектах (programming in large), является модель CFOM (Composition-Filters Object Model), разрабатываемая в Университете Твенте, Нидерланды. Она доводит до кристальной чистоты старую идею, гласящую, что сообщения, передаваемые объекту, и методы, обрабатывающие эти сообщения - не обязательно одно и то же, а сообщение представляет самостоятельный интерес. CFOM разводит объект-ядро (kernel object) и интерфейс. Объект-ядро полностью инкапсулирован, его структура недоступна извне, открыты только методы, но и те - не для всех, а только для интерфейса, являющегося своего рода оболочкой объекта. Интерфейс может содержать объекты (секция internals) или ссылки на внешние объекты (externals), а также фильтры. Фильтры задают правила обработки входящих (inputfilters) и, мало того - исходящих (outputfilters) сообщений (Ошибка! Источник ссылки не найден.). В простейшем случае сообщение передается ядру на выполнение, и выглядит это так: inner.doSmth. Inner - это и есть ядро. В общем же случае сообщение, попав в сито фильтров, может быть также модифицировано либо переадресовано одному из объектов, определенных в теле интерфейса, или внешним объектам.
Модель CFOM смело можно отнести к числу "недоразвитых" - вводя понятие объекта и класса, ее создатели отказались от введения отношений наследования. Сделано это по причинам, кратко уже упомянутым выше, и развернутое описание которых займет слишком много места. Каким же образом создатели CFOM ухитряются обойтись без наследования? Очень просто - включение и делегирование. Если вы хотите, чтобы объект objA класса A предоставлял и сервис класса B, вы включаете объект objB класса B в секцию internals интерфейса и помимо возможных прочих фильтров указываете такой: {inner.*, objB.*}. Понять, что делает этот фильтр, легко - все сообщения ('*' и означает "все"), распознаваемые ядром, передавать ядру, все сообщения, распознаваемые объектом objB (т.е.
все сообщения класса B), передавать objB. С печально известными проблемами множественного наследования здесь сталкиваться не приходится - фильтры выполняются слева направо и сверху вниз. Если набор методы A и B пересекаются, и вы хотите, чтобы сообщение mess1 обрабатывалось в B, а не в A, то фильтр становится таким: {objB.mess1, inner.*, objB.*}. Если objB объявлен в секции externals, то это ссылка на внешний объект, и в этом случае фильтр {..., objB.*, ...} будет реализовывать делегирование в чистом виде.
На самом деле синтаксис фильтров несколько более сложен, и важную роль играют здесь условия (conditions) - особая группа методов ядра, не имеющих параметров и вырабатывающих значение булевского типа. Тот или иной фильтр может срабатывать или быть проигнорирован в зависимости от условий. Введение условий позволяет в рамках одной модели описать и переходы состояний - изменение состояния объекта и даже история изменения состояний объекта может находить свое отражение в изменении условиях, а те будут задавать тот или иной сценарий обработки сообщений. Введены также псевдопеременные: sender (№1 на Илл. 2) - идентифицирует объект, пославший сообщение; упоминавшаяся уже inner (№4 на Илл. 2) - ядро, т.е. собственно реализация той или иной совокупности сервисов; self - означает то же самое, что и self в Samlltalk или this в C++ - ссылка на сам объект в теле программного кода, принадлежащего этому объекту; message (№5) - метаданные, т.е. имя сообщения и список аргументов; server (№2) - объект, который первым принял сообщение. В приведенном выше примере сервером является объект objA. Если бы objA в свою очередь был бы включен в интерфейсную часть объекта objX (неважно, где бы он был объявлен - в секции internals или externals), то сервером стал бы objX. Сообщение, проходя через множество фильтров, может много раз поменять "направление", однако значение server не изменится. Данная псевдопеременная помогает объекту разобраться, в каком контекcте он получает сообщение.
Например, public и private, реализованные в C++, легко воспроизводятся с использованием server.
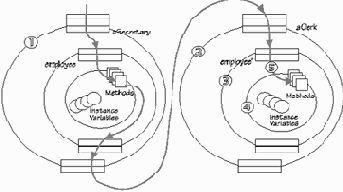
Илл. 2
CFOM позволяет описать как статические свойства объекта, так и динамически изменить их. Во всяком случае self и inner могут быть статически связаны компилятором, а sender и server - в том случае, если они представлены константами. CFOM представлена языком Sina (по имени Ибн Сины), а тот, в свою очередь, реализован в рамках среды Smalltalk. Между тем, ничто не мешает использовать CFOM как метод моделирования. Метамодель CFOM в принципе может быть представлена средствами другой ОО модели, и выбрав CASE пакет, позволяющий писать скрипты для обработки метаданных, например, Rational Rose (методы Booch, OMT, UML) или ParadigmPlus (компания Platinum - Booch, OMT, UML, Fusion, Shlaer/Mellor, Martin/Odell OOIE, Coad/Yourdon), можно искусственно расширить оную, "другую", модель средствами CFOM (вот только готовы ли вы отказаться от наследования?).
Чем так удивительно хороша CFOM? Тем, что она позволяет изолировать друг от друга вещи несвязанные, и которые, тем не менее, оказываются поневоле перемешаны в одном и том же программном коде. Ядро в CFOM - это суть объекта, то, что он делает, все его прикладное наполнение, если угодно - бизнес-логика. Все остальное вынесено вовне: коммуникации между объектами, делегирование (читай - диалоги) выполнения тех или иных функций внешнему, в том числе и удаленному объекту, синхронизация и обеспечение конкурентного режима, динамическое преобразование сообщений и множественные представления (view). Поясним это на примерах:
Начнем с последнего - в зависимости от условий (conditions), а также от того, какой именно объект (sender) посылает запросы, принимающая сторона может в простейшем случае открывать или закрывать те или иные слоты, а в случае более сложном - динамически изменять цепочку обработки сообщения. Здесь вам и разграничение прав доступа, и базы данных, и модная ныне тема - деловые процессы (они же документооборот).
Необходимо заставить объект objB посылать сообщение не локальному внешнему объекту objC (класс C), а такому же, но удаленному, objCRemote. Включив objB в objA и задействуя в последнем фильтрацию исходящих сообщений, вы, не изменяя кода objB, организуете распределенные вычисления.
Объект objCRemote (напоминаю - класса C) может обслужить одновременно не более одного обращающегося к нему по сети клиента. Рассмотрим объект objM, принимающий все предназначенные objCRemote сообщения, организующего одну или множество очередей запросов и передающего эти запросы одному или нескольким объектам класса C. В результате будет обеспечен либо последовательный доступ к сервису класса C (множество клиентов - один экземпляр класса C), либо параллельный (каждому клиенту - собственный экземпляр), либо смешанный (экземпляров меньше, чем клиентов, запросы буферизуются)
Все посылаемые сообщения предварительно протоколируются
Необходимость изменения любого из аспектов - параллелизм, синхронизация, сценарий, замена локального вызова на удаленный - требует изменения лишь локального участка модели или кода, остальные не затрагиваются. Между тем, если вы пишете на Ada, то прикладная логика перемешана с логикой распараллеливания и синхронизации. А если вам захочется переписать программу на предмет возможности использования DCE/RPC, то заранее примите мои соболезнования.
Ну а мониторы-то тут причем? Или автор пытается подражать О'Генри - ни королей, ни капусты в романе, зато в заголовке - пожалуйста. На самом деле самые внимательные уже смогли найти в капусте (ОО методы) королей (мониторы). Вернемся к примерам 3 и 4. Что такое objM, который принимает от клиентов, протоколирует, буферизует и перенаправляет запросы? Что он, скажите мне, как не монитор транзакций?
И, коль скоро в теме заявлены современные мониторы, то нельзя не вспомнить о предельно современном, а именно - еще в "Памперсах" разгуливающем Microsoft Transaction Server (MTS). Начнем с того, что MTS целиком базируется на архитектуре COM - до удивления близкой рассмотренной выше CFOM (и там, и там расширение возможностей класса осуществляется посредством включения и делегирования - см.
выше). MTS является, конечно, не моделью и не ОО методом, а реализацией вполне конкретного подхода. В то же время реализация эта весьма близка к той модели о которой мы говорили, и к тому же выводит наиболее массовую на нынешний момент технологию создания программных компонентов на новый уровень возможностей. Рассмотрим лишь некоторые из фрагментов архитектуры MTS.
Application Component (AC) сосредотачивает в себе прикладную логику. Его смело можно уподобить ядру объекта в CFOM. Ничего относящегося к распараллеливанию, опросу ресурсов и т.д. здесь нет. Пользуясь любым инструментом, позволяющим делать ActiveX компоненты, разработчик создает AC такой же, как и для однопользовательского локального приложения - все проблемы, не связанные с собственно бизнес-логикой, берет на себя монитор транзакций. Приложение, управляемое MTS, может работать с разными видами ресурсов, различаются два вида последних: Resource Managers (RM) и Resource Dispensers (RD). Разница в том, что RM устойчив к сбоям (последняя буква в ACID - atomicity, consistency, isolation, durability), а RD - не дает никаких гарантий, т.е. это ресурс "вообще". В качестве интерфейса к ресурсам MTS использует все тот же OLE.
Похожую концепцию предлагают и другие мониторы, такие как IBM Transaction Server и NCR TopEnd. Начнем с TopEnd. Созданный компанией NCR (изначально - под другим названием) и радикально переработанный где-то в 91-м, компанией, которая трудится с 60-х, и разные мониторы которой стоят на 40000 серверов, TopEnd учитывает сложившиеся реалии: клиент-сервер и графические станции - с одной стороны, а неуничтожимые мейнфреймы, терминалы и DOS - с другой. TopEnd предлагает два вида серверов - managed server (MS) и standard server (SS). SS служит исключительно целям поддержки процесса переноса уже имеющегося сервера приложений, разработанного каким-либо иным способом, на монитор TopEnd. Работать с SS - занятие достаточно утомительное, поскольку распараллеливанием обслуживания запросов в этом случае занимается сам программист.
Другое дело MS - ведь он же "managed", т.е. его выполнением управляет сам монитор. MS выглядит практически так же, как и любая другая функция, написанная на C. Он подключается к TopEnd, и всей его дальнейшей жизнью управляют двое - TopEnd и администратор системы.
IBM Transaction Server двуглав, как российский герб. С одной стороны это Encina, монитор, также разработанный в начале 90-х компанией Transarc (являющейся теперь частью IBM) и реализующий архитектуру OSF/DCE. С другой стороны это CICS, известный монитор IBM, установленный на 70000 серверов и мейнфреймов. Если добавить сюда IMS-TP, TPF и Encina, то дух захватывает от числа инсталляций у IBM. Transaction Server базируется на сервисах и ядре Encina, обеспечивая в то же время и совместимость с CICS. В любом случае разработчику доступны и CICS, и Encina в "чистом виде". Encina работает с любым XA ресурсом, но не только. Например, входящая в базовый набор структурированная файловая система (SFS) не является XA ресурсом. SFS представляет из себя некоторую комбинацию DCE файловой системы с ISAM. Немного отклоняясь в сторону, скажу, что перенос наработок с Fox, Clipper, Paradox, Btreive на Encina и SFS существенно проще, чем на реляционный сервер БД. Encina и Microsoft оказываются в некотором смысле даже ближе , чем можно ожидать. В Encina используется язык описания интерфейсов (IDL), принятый в OSF/DCE при работе с удаленным вызовом процедур (RPC). Microsoft реализовал DCE/RPC в самой первой версии Windows NT, и IDL, используемый при описании COM интерфейсов (отчасти и CORBA IDL) более, чем близок к DCE/RPC IDL. Таким образом, некий набор сервисов рассматривается в Encina как целое, как интерфейс, и несложно показать, как увязать технику программирования данного монитора транзакций с ОО подходом CFOM (возможно, и каким-либо еще). В TopEnd нет понятия интерфейса, однако сервисы тоже не рассыпаны сами по себе. Существуют по сути очень близкое понятие product - совокупность сервисов (функций), помимо этого - function (например, "оформить билет") и function qualifier.
Квалификатор функции - не более, чем номер, однако вносит особый шарм. Как оформление билета, так и продажа фунта изюму со склада и т.д. - операция, занимающая не один шаг. Наличие квалификаторов позволяет не создавать на каждый из них по собственной функции, а поделить на шаги единственную.
Итак, оставим в стороне разговоры о производительности и надежности - мониторы транзакций упрощают жизнь разработчику. Я ненамного перегну палку, если скажу, что человек, приступающий к созданию банковской, складской, бухгалтерской и т.д. задачи думает о ее функциональности, а не о том, как она будет работать в сети. То есть он пишет однопользовательскую по сути программу. В результате она прекрасно работает для, скажем, трех пользователей. А вот потом начинаются проблемы. Серьезным образом переработать приложение не удается, потому что параллельно с решением задачи производительности обычно требуется и доводить логику. Мониторы же (как минимум - рассмотренные выше) позволяют вынести все эти заботы на администратора системы. Мне как-то подсказали интересную аналогию - программирование для Windows. В одном случае вы должны писать WinMain и т.д., самостоятельно обрабатывать входящие сообщения. Используя же Delphi, VB, PowerBuilder или специально разработанную библиотеку C/C++ вы будете создавать обработчики событий (причем только тех, которые вас интересуют), не заботясь о том, откуда они берутся. Очень похоже
Серверы баз данных со всем справляются сами? Не думаю. Даже с мониторингом собственных ресурсов. Существует (и неплохо) компания Platinum, поставляющая, нет не мониторы транзакций, а утилиты для серверов БД, которые делают, казалось бы, все то же самое, что и штатные средства. Но при ближайшем рассмотрении оказывается, что не то: мониторинг более глубокий, статистика более детальная (как, например, насчет того, чтобы увидеть в реальном времени, что происходит в журнале транзакций?); средства администрирования глубже; наконец, то, чего просто нет у самого производителя СУБД.
А даже сравнивая между собой только мониторы, которые, казалось бы, делают одно и то же, выясняешь, сколь по-разному можно это делать. О сравнении с СУБД и говорить нечего. Есть серверы БД, отводящие на каждое подсоединение 50КБ, есть те, что отводят 250КБ, а есть и такие, что отдают по 2МБ - так с каким сравнивать? Есть и ограничения, которые не слишком о себе заявляют, пока речь идет о централизованной задаче, например, пространство имен. О Microsoft TS говорить до появления Cairo преждевременно, но о других можно. TopEnd предлагает единое (вся сеть - один домен) глобальное пространство имен - вы обращаетесь к сервису, не зная, на каком сервере он "хранится" и будет выполняться. Encina интегрирована со службой каталогов DCE - CDS и позволяет, в случае необходимости разбивать сеть на ячейки, однако и в этом случае речь идет об именах, а не о "месторасположении сервиса". В случае РСУБД мы имеем нечто похожее на "имя_сервера.имя_базы(или схемы).имя_владельца.имя_таблицы(или хранимой процедуры". Репликация процедур смягчает, но не снимает эту проблему, а она о себе непременно заявит в большой и распределенной задаче.
Еще пример, связанный со временем жизни приложения. В связи с новым постановлением изменяется порядок расчетов (начисления и т.д.) чего-нибудь. Транзакции, начинающиеся с 1 апреля, проходят по новой схеме. В то же время начатые раньше этой даты, завершаются по старой. В этом случае до завершения всех "старых" транзакций, вы имеете дело с разными версиями сервиса, а не с разным сервисом. Имея доступ к метаинформации , конкретно - о дате посылки сообщения, начала транзакции и т.д., вы сможете решить эту проблему достаточно безболезненно. Имеете ли вы такую возможность в РСУБД? Или вам придется, чертыхаясь, срочно переделывать приложение и сопровождать его в этом виде в течение времени завершения всех "старых" транзакций. А потом, холодея, вы будете ждать нового изменения? А можете ли вы управлять на программном уровне общей памятью? А как насчет разграничения доступа - в Encina, например, реализовано 6 уровней плюс седьмой, если в системе установлена среда DCE.
Плюс шифрация, включая использование собственных алгоритмов. Итак - пока РСУБД не будут решать соответствующие вопросы (не "для галочки", а на деле), говорить о том, что они "лучше" мониторов транзакций, рановато.
Еще один вопрос - "другие" средства middleware, "делающие ненужными мониторы". Во-первых, это появляющиеся в новых версиях пакетов для разработки front-end программ средства создания серверов приложений. Эта альтернатива действительно интересна, но не выше уровня рабочей группы. В дополнение к перечисленным выше ограничениям здесь мы не видим поддержки безотказной работы и балансировки нагрузки. По поводу серверов приложений в архитектуре CORBA можно сказать одно - сама по себе эта архитектура не является альтернативой, напротив - требует наличия монитора (как минимум, в виде соответствующих сервисов), но только на этот раз - CORBA совместимого. Хорошим примером является Microsoft - владея полностью технологией COM (OLE), компания почему-то создает именно монитор транзакций. Ну а Encina работает с SOM (реализация CORBA от IBM).
В числе других "убийц" чаще всего называют ПО передачи сообщений. Так вот MOM (message -oriented middleware) не предоставляет технологии создания серверов приложений - речь идет только о гарантированной доставке сообщений, доставке в оговоренный интервал времени, частичной поддержке транзакций. Но кто (что) укладывает сообщения в очереди и кто занимается их выборкой - это вне компетенции MOM. Оно либо должно быть внедрено в СУБД, монитор транзакций и т.п., либо работать совместно с ними или какими-либо другими серверами приложений. Есть примеры и того, и другого - опция Recoverable Queuing System (RQS) для TopEnd, и Recoverable Transaction Queuing (RTQ) - неотъемлемая часть Encina. RTQ и RQS обеспечивают отложенное выполнение запроса. Компания IBM поставляет MQSeries - в чистом виде MOM - наверное, чтобы убить Encina. Ну, а если всерьез, то MQS чаще всего служит для связывания между собой разных мониторов или иных серверов приложений.
TopEnd никогда не будет работать с RTQ, а Encina - с RQS. А MQSeries, являясь с точки зрения монитора транзакций XA-ресурсом, может их объединить, "приклеив" также Lotus Notes, приложение, разработанное на Distributed PowerBuilder или Distributed Visual Basic. После появления MQS для Windows'95 речь уже заходит о поддержке мобильных клиентов (мониторы этого не могут). MQS поддерживает собственные транзакции, однако распределенные, вовлекающими несколько узлов - нет, и в роли координатора может выступать монитор. Таким образом, MQS может быть существенным подспорьем монитору в плане поддержки отложенного, асинхронного в полном смысле, выполнения (отложенного - не обязательно на послезавтра, речь может идти и о десятой доле секунды) как между сервером и сервером, так и между клиентом и сервером. MQS может использоваться в качестве интегрирующей среды между другими классами серверов приложений. Однако альтернативой мониторам транзакций MOM не является, что подтверждается простым сравнением функционального набора того и другого.
Таким образом, мониторы транзакций живы и, судя по всему, будут жить, пусть даже и в другом обличье. Мониторы транзакций являются не только средством поддержки, мониторинга и администрирования времени выполнения. Современные мониторы транзакций предоставляют очень надежную (с точки зрения технологии программирования) платформу разработки приложений. Проблема в том, для приложений из 5 экранных форм сказывается непривычность. А вот выигрыш сказывается позже и в по-настоящему сложных системах. Данная платформа разработки не является объектно-ориентированной в общепринятом смысле - нет речи о классах и наследовании. Однако она перекликается с наиболее продуманными ОО методами. Она близка последним не по букве, но по духу. В конечном итоге это и является главным, так как и многочисленные создатели ОО методологии, и создатели мониторов транзакций пытаются решить проблему создания приложений функционально сложных, распределенных, разнородных и сохраняющих свою жизнеспособность в течение долгого времени.
ВЕСТЬ АО
115446, Москва, Коломенский проезд,1а
тел: (095) 115-6001, факс: (095) 112-2333
[]
[]
[]
Объектно-реляционная система: лучшее из обоих систем.
Illustra Server - первая в мире объектно-реляционная СУБД. Сервер поддерживает объектно-
ориентированное управление сложными типами данных, но в то же время предоставляет
эффективный язык запросов, основанный на расширении индустриального стандарта SQL. Он
поддерживает быструю разработку приложений, значительно повышая их качество. Значительно
снижается стоимость поддержки приложений, так как Illustra работает как единый репозиторий
объектов.
Объектные возможности Illustra.
Определяемые пользователем типы данных.
Множества и массивы как конструкторы типов.
Функции, определяемые пользователем (методы).
Уникальные идентификаторы объектов.
Методы доступа, специфичные для доменов.
Наследование.
Полиморфизм.
Реляционные возможности Illustra.
Оптимизированный язык запросов (SQL).
Представления.
Обеспечение безопасности с помощью предложений grant/revoke.
Возможности одновременной работы пользователей.
Транзакции.
Восстановление после системных сбоев и сбоев носителей.
Объектно-реляционные базы данных
А. Волков, Компания "Корпоративные Системы"
В последние годы много говорится о системах баз данных следующего поколения. Нужны ли они? Какими они будут? Над решениями этих проблем работают и ученые и исследователи в коммерческих компаниях. Естественно, концепция баз данных следующего поколения должна быть выработана специалистами из научных лабораторий, реализация же - за разработчиками промышленных систем. И если первые занимаются этой проблемой уже давно, вторые только приступили к выпуску продуктов
Два различные школы известных специалистов в области баз данных представили свое понимание того, какими будут системы следующего поколения. Этому посвящены две классические работы: "Манифест объектно-ориентированных баз данных" и "Системы баз данных следующего поколения: Манифест". Совсем недавно к ним добавился и "Третий манифест", содержащий критику обоих подходов и предлагающий свое решение проблемы.
В отличие от реляционной модели, на основе которой были построены промышленные системы 15-20 лет назад, похоже, что сейчас ситуация развивается иным образом. Производители СУБД фактически уже сделали свой выбор, не дожидаясь пока договорятся ученые. Выбор этот - объектно-реляционные СУБД. Есть ли альтернатива такому выбору в следующем поколении систем?
В докладе рассмотрены различные подходы к организации систем баз данных следующего поколения. Проведено также сравнение этих подходов с зарождающимся фактическим промышленным стандартом объектно-реляционных СУБД.
[]
[]
[]
Объекты
SQLBase содержит набор стандартных объектов и структур, общих для большинства реляционных
СУБД. Данные SQLBase хранит в виде таблиц, состоящих из колонок и строк. SQLBase
поддерживает виртуальные таблицы (views) и рассматривает их как отдельные объекты базы
данных. Для поддержания уникальности данных в колонках таблиц, а также для ускорения доступа
к данным используются индексы. База данных SQLBase включает также пользователей и их
привилегии. В качестве расширения стандартного набора объектов SQLBase содержит триггеры,
хранимые команды и хранимые процедуры. В начальной редакции SQLBase 6 эта СУБД включала
также и события или таймеры базы данных, однако этот тип объектов не вошел в окончательную
версию продукта. Поддержка событий в SQLBase намечена на середину года.
Типы данных, поддерживаемые SQLBase, приведены на рис. 1. Следует отметить, что тип данных
CHAR в SQLBase не отличается от VARCHAR (в обоих случаях СУБД не хранит пустые места в
колонках) и поддерживается, в основном, для совместимости с DB2.
SQLBase поддерживает стандарт SQL-89 с многочисленными расширениями.
Кроме поддержки выполнения стандартных SQL запросов SQLBase содержит большое количество
встроенных функций (более 60). Они включают агрегатные функции, функции преобразования
форматов данных, выбора и логического ветвления, обработки строковых, числовых и временных
данных, а также различные математические и финансовые функции.
Рис. 1. Типы данных SQLBase
| CHAR (или VARCHAR) | Строковый тип | до 254 байт | Имеет вид CHAR(3). Пустые места не хранятся |
| LONG VARCHAR | Строковый тип | неограниченный размер | Для этого типа не поддерживаются предложения WHERE, ORDER BY и многие функции СУБД. |
| NUMBER | Числовой тип | до 15 цифр | Суперсет всех числовых типов SQLBase |
| DECIMAL | Числовой тип с фиксированной точкой | до 15 цифр | Имеет вид DECIMAL (размер, десятичных знаков). SQLBase не поддерживает тип CURRENCY. Используйте для этого DECIMAL(15,2) |
| INTEGER | Числовой целый тип | до 10 цифр | |
| SMALLINT | Числовой целый тип | до 5 цифр | |
| DOUBLE PRECISION | Числовой тип | до 15 цифр | Для чисел с плавающей точкой |
| FLOAT | Числовой тип | до 15 цифр | Отличается от DOUBLE PRECISION указанием количества значащих цифр |
| DATETIME (или TIMESTAMP) | Дата/Время | Точность временной компоненты - до 1 мксек | |
| DATE | Дата | ||
| TIME | Время | Точность до 1 сек |
? SQLBase существуют пользователи трех уровней: CONNECT, RESOURCE и DBA.
Особенности уровня доступа к данным и другие привилегии каждой категории пользователей
приведены на рис. 2.
Рис. 2. Типы пользователей SQLBase
| SYSADM | Создает пользователей и устанавливает их пароли и права доступа |
| DBA | Выдает, изменяет и отнимает права доступа к объекту БД для любого пользователя |
| RESOURCE | Создает и удаляет объекты БД. Выдает, изменяет и отнимает права доступа к этим объектам для других пользователей |
| CONNECT | Имеет доступ к объектам, но не может их создавать |
Всю информацию о базе данных сервер хранит в системном каталоге базы. При этом
поддерживаются два системных каталога: один полный, который содержит всю информацию об
объектах и состоянии базы данных SQLBase, и универсальный, который совместим по структуре с
системными каталогами большинства других СУБД. Поддержка универсального системного
каталога позволяет управлять базами данных SQLBase из программ и средств администрирования
СУБД других фирм. Краткое описание таблиц системного каталога приведено на рис. 3.
Рис. 3. Таблицы системного каталога SQLBase
| SYSCOLAUTH | Права обновления колонок |
| SYSCOLUMNS | Колонки базы данных |
| SYSCOMMANDS | Хранимые команды и хранимые процедуры |
| SYSEVENTS | Системные события таймера (в текущей версии не используются) |
| SYSEXECUTEAUTH | Права выполнения хранимых процедур |
| SYSFKCONSTRAINTS | Внешние ключи (foreign keys) |
| SYSINDEXES | Индексы |
| SYSKEYS | Колонки индексов |
| SYSPARTTRANS | Незавершенные распределенные транзакции |
| SYSPKCONSTRAINTS | Первичные ключи (primary keys) |
| SYSROWIDLISTS | Сохраненные множества результатов (result sets) |
| SYSSYNONYMS | Синонимы объектов базы данных |
| SYSTABAUTH | Права доступа к таблицам |
| SYSTABCONSTRAINTS | Ограничения ссылочной целостности |
| SYSTABLES | Таблицы и views |
| SYSTRGCOLS | Колонки триггеров |
| SYSTRIGGERS | Триггеры |
| SYSUSERAUTH | Пользователи БД и их пароли |
| SYSVIEWS | Описание views в виде SQL запросов |
Объекты, элементы управления и события
Разработка в среде PowerBuilder базируется на создании объектов, элементов управления и событий.
Приложения PowerBuilder состоят из объектов (таких как окна, Окна данных, меню и объекты
пользователя) и элементов управления (таких как Командные кнопки(CommandButtons) и
Радиокнопки (RadioButtons)).
Каждый объект и каждый элемент управления PowerBuilder имеет набор атрибутов, описывающих его
размер, расположение, последовательность размещения и текущее состояние (видимый,
разрешенный).
PowerBuilder - система, управляемая событиями. Разработчики определяют атрибуты, а также
поведение объектов и элементов управления в соответствии с конструкцией приложения.
Обработка больших бинарных объектов (BLOB)
Informix поддерживает две разновидности BLOB-значений - TEXT и BYTE. Значения типа TEXT
отображаются в суперполях в виде текста, если они содержат только печатные символы. Значения
типа BYTE автоматически не отображаются. Суперполя для обоих типов имеют атрибут
blobEditor, в котором указывается имя внешней программы редактора.
Обратное проектирование (Reverse engineering)
Обратное проектирование, то есть восстановление информационной модели по существующей базе
данных, используется при выборе оптимальной платформы (rightsizing) для существующей настольной
(desktop) базы данных или базы данных на mainframe, а также при расширении (или модификации)
существующей структуры, которая была построена без необходимой сопроводительной
документации. После завершения процесса восстановления модели ERwin автоматически
"раскладывает" таблицы на диаграмме. Теперь можно выполнять модификации уже с использованием
логической схемы - добавлять сущности, атрибуты, комментарии, связи и т.д. По завершении
изменений одна команда - синхронизировать модель с базой данных - актуализирует все проведенные
изменения.
Построение модели может быть выполнено как на основании данных каталога базы данных, так и на
основании пакета операторов SQL, с помощью которого была создана база данных.
выделяются следующие основные этапы процесса
В соответствии с общей архитектурой CASE-системы DESIGNER/2000, изображенной на рис.3,
выделяются следующие основные этапы процесса разработки системы: моделирование и анализ
деловой деятельности, разработка концептуальных моделей предметной области, проектирование
прикладной системы и реализация.
|
Анализ деловой деятельности Концептуальное моделирование Проектирование системы Генерация приложений | Информация | Процессы |
 |
Общая характеристика продуктов Oraсle
Все продукты Oracle (СУБД, средства разработки, средства для конечного пользователя, сетевые
компоненты) являются открытыми, масштабируемыми и программируемыми. Они позволяют
разрабатывать приложения как уровня небольшой рабочей группы, так и уровня огромного
предприятия с тысячами пользователей, террабайтными базами, размещенными в различных
зданиях и даже странах.
Средства Oracle позволяют надежно защитить эти данные, обеспечить их целостность и
непротиворечивость. Продукты Oracle работают более чем на ста вычислительных платформах
(компьютер + операционная система), поддерживают все основные промышленные сетевые
протоколы и графические оконные среды. Это позволяет Вам с минимальными затратами
переносить готовые приложения с одной платформы на другую. Например, разработав
приложение на однопроцессорном персональном компьютере с MS Windows, Вы можете далее
выполнять его на Unix - машинах, больших IBM машинах, SMP и MPP архитектурах, высоко
надежных и кластерных архитектурах.
При повышении нагрузки на Ваше приложение, Вы можете заменить сервер на более мощный,
добавить еще один сервер, вынести часть обработки в другой узел и т. д. Если Ваш клиент работал
через терминал, а затем решил перейти к архитектуре клиент - сервер или даже переместился в
другой город, он сможет продолжать работать с теми же БД Oracle. Все это не потребует
модификации кода приложений.
С помощью средств Oracle Вы сможете реализовать оперативную обработку (OLTP - системы),
системы поддержки принятия решений (DSS - системы) и системы накопления и анализа больших
объемов данных (Data Warehouse и OLAP - системы). Oracle поддерживает все основные
стандарты:
FIPS 127-2, ANSI X3-135.1992 - для БД;
NCSC TDI C2, B1, ITSEC F - C2/E3, F - B1/B3 - по защите данных;
OSI, DNSIX (MaxSix), SNMP - для сети;
ODBC, TSIG, X/Open, DCE, DDE, OLE, OCX, VBX - для взаимодействия
приложений.
Общие характеристики
SQLBase - это реляционная многопользовательская СУБД типа клиент-сервер фирмы Gupta
Corporation (Menlo Park, USA). Она предназначена для использования в качестве сервера баз
данных в локальных вычислительных сетях на базе персональных компьютеров. SQLBase
ориентирована прежде всего на сети масштаба малого и среднего предприятия с количеством
одновременно обращающихся к СУБД рабочих станций от 20 до 100, а также на подразделения
(филиалы, отделения) крупных организаций. В целом СУБД такого класса называют серверами
для рабочих групп (Workgroup Server).
SQLBase поддерживает базы данных размером до 4 Гбайт в виде консолидированного файла и до
512 Гбайт в разделенном режиме (partitioned database mode). Сервер SQLBase может работать с
базами данных, расположенными на одном компьютере, но позволяет располагать и распределять
их на разных физических и логических дисках и других носителях (оптические накопители и CD-
ROM).
СУБД фирмы Gupta отличается простотой установки и настройки, малым потреблением
системных ресурсов, что позволяет устанавливать и эксплуатировать SQLBase на недорогих
компьютерах. Так SQLBase for NetWare может работать под управлением NetWare 3.12 на машине
с 8 Мбайт оперативной памяти и при этом эффективно обслуживать 10-15 пользователей.
Режим работы SQLBase, параметры размещения его баз данных, а также описание сетевых
протоколов сервера содержатся в конфигурационном файле SQL.INI, который имеет структуру
стандартного INI-файла системы Windows. SQL.INI является универсальным файлом
конфигурации для всех продуктов Gupta и включает в себя секции описывающие поведение
различных серверов и клиентов Gupta.
Обзор продукта
Сейчас организации становятся все более динамичными. Это необходимо для быстрой реакции на
меняющиеся условия ведения бизнеса. Все более активно идет процесс децентрализации принятия
решений, а стремление повысить продуктивность принятия решений ведет к упрощению процедур
реализации различного рода идей. Для создания средств поддержки подобного рода изменений
организации обращаются к технологиям распределенной обработки информации. Эти технологии
позволяют размещать данные как можно ближе к пользователям, которым информация
необходима для принятия важных решений.
| SQL Server 4.21a |  | SQL Server 6.0 | | SQL Server следующие версии |
| NT Server | NT Server | Cairo | ||
|
Симметричная архитектура сервера (SMP) Графические средства администратора Унифицированная регистрация в сети Расширенные хранимые процедуры Интеграция с эл. почтой SQL Object Manager Service Manager RPC для доступа к БД Performance monitor ANSI89 Level 1 |
Тиражирование данных Параллельная обработка БД Сканирование, индексирование, создание и восстановление страховых копий, загрузка Поддержка очень больших БД Оптимизатор, опережающее чтение, управление блокировками Распределенное управление OLE automation ODBC курсоры Расширения языка ANSI92 (95.1) X/A (95.1) |
Унифицированное хранение данных Параллельные запросы Distributed joins Доступ к данным OLE Проверка версий, блокировка на уровне записи Защита средствами Cairo, каталоги Пользовательские функции Интеграция с репозитарием объектов |
Обзор средств проектирования информационных систем
А.М.Вендров, Центральный банк РФ
Цель данного доклада - попытаться описать и обосновать один из возможных подходов к анализу и выбору средств проектирования информационных систем достаточно крупного масштаба (здесь намеренно не используется термин "CASE-средство", поскольку большинство известных CASE-средств в лучшем случае позволяют описать будущие приложения лишь в самом общем виде).
Конечный результат выбора ни в коем случае не следует рассматривать как нечто абсолютное, он отражает лишь мнение конкретного коллектива разработчиков, утвердившееся на заданном
временном интервале.
Под средствами проектирования информационных систем (СП ИС) будем понимать комплекс
инструментальных средств, обеспечивающих в рамках выбранной методологии проектирования
поддержку полного жизненного цикла (ЖЦ) ИС, который включает в себя, как правило,
стратегическое планирование, анализ, проектирование, реализацию, внедрение и эксплуатацию.
Каждый этап характеризуется определенными задачами и методами их решения, исходными
данными, полученными на предыдущем этапе, и результатами. При анализе СП их следует
рассматривать не локально, а в комплексе, что позволяет реально охарактеризовать их
достоинства, недостатки и место в общем технологическом цикле создания ИС.
В общем случае стратегия выбора СП для конкретного применения зависит от следующих
факторов:
характеристик моделируемой предметной области;
целей, потребностей и ограничений будущего проекта ИС, включая
квалификацию участвующих в процессе проектирования специалистов;
используемой методологии проектирования.
Тенденции развития современных информационных технологий приводят к постоянному
возрастанию сложности ИС, создаваемых в различных областях экономики. Современные
сложные ИС и проекты, обеспечивающие их создание, характеризуются, как правило, следующими особенностями:
сложность предметной области (достаточно большое количество функций,
объектов, атрибутов и сложные взаимосвязи между ними), требующая
тщательного моделирования и анализа данных и процессов;
наличие совокупности тесно взаимодействующих компонентов - подсистем,
имеющих свои локальные задачи и цели функционирования;
иерархическую структуру взаимосвязей компонентов, обеспечивающую
устойчивость функционирования системы;
иерархическую совокупность критериев качества функционирования
компонентов и ИС в целом, обеспечивающих достижение главной цели -
создания и последующего применения системы;
отсутствие прямых аналогов, ограничивающее возможность использования
каких-либо типовых проектных решений и прикладных систем;
необходимость достаточно длительного сосуществования старых
приложений и вновь разрабатываемых БД и приложений;
наличие потребности как в традиционных приложениях, связанных с
обработкой транзакций и решением регламентных задач, так и в приложениях
аналитической обработки (поддержки принятия решений), использующих
нерегламентированные запросы к данным большого объема;
поддержка одновременной работы достаточно большого количества
локальных сетей, связываемых в глобальную сеть масштаба предприятия, и
территориально удаленных пользователей;
функционирование в неоднородной операционной среде на нескольких
вычислительных платформах;
разобщенность и разнородность отдельных микроколлективов
разработчиков по уровню квалификации и сложившимся традициям
использования тех или иных инструментальных средств;
существенная временная протяженность проекта, обусловленная, с одной
стороны, ограниченными возможностями коллектива разработчиков, и, с
другой стороны, масштабами организации-заказчика и различной степенью
готовности отдельных ее подразделений к внедрению ИС.
Методология проектирования определяется как совокупность трех составляющих:
пошаговой процедуры, определяющей последовательность
технологических операций проектирования;
критериев и правил, используемых для оценки результатов выполнения
технологических операций;
нотаций (графических и текстовых средств), используемых для описания
проектируемой системы.
На выбор СП могут существенно повлиять следующие особенности методологии
проектирования:
ориентация на создание уникального или типового проекта;
итерационный характер процесса проектирования;
возможность декомпозиции проекта на составные части, разрабатываемые
группами исполнителей ограниченной численности с последующей
интеграцией составных частей;
жесткая дисциплина проектирования и разработки при их коллективном
характере;
необходимость отчуждения проекта от разработчиков и его последующего
централизованного сопровождения.
ODBC-интерфейс
Спецификация ODBC фирмы Microsoft определяет универсальный промежуточный интерфейс
между приложениями-клиентами в среде Windows и Windows NT и различными реляционными
базами данных.
ODBC API представляет собой набор вызовов функций. Доступ к базе данных в нем задается
операторами SQL, которые передаются соответствующим функциям в виде строковых параметров.
Спецификация ODBC, как и Embedded SQL, поддерживает курсоры. Имеется возможность
вызывать хранимые процедуры. Из программы могут выдаваться любые операторы SQL, в том
числе DDL-операторы.
ODBC-драйверы для Sybase выпускают несколько фирм, в том числе фирма INTERSOLV. Такой
драйвер входит в состав Sybase Open Client.
Большинство приложений, связанных с обработкой данных в среде MS-Windows, поддерживают
ODBC-интерфейс или DB-Library, и, соответственно, имеют доступ к СУБД Sybase. Среди таких
приложений Microsoft Excel, Word, Access, Visual Basic.
OLE Automation: написание сценариев на Visual Basic/Visual FoxPro
Мощь административного OLE интерфейса SQL Server становится очевидной, если учитывать
возможность использования языка программирования средств разработчика Microsoft (таких как
Visual Basic или Visual FoxPro) для написания сценариев выполнения административных задач.
Ниже приведен пример кода, используемого для получения служебной информации с SQL
Server.
On-Line Справочник (On-Line Help)
Утилита-справочник PROGRESS On-Line Help предоставляет Вам все возможности для включения
в приложения контекстно-ориентированной справочной информации в режиме On-Line. On-Line
Справочник разработан таким образом, что Вы можете использовать либо справочные
возможности собственно операционной системы (например, справочник Windows), либо можете
воспользоваться справочной системой PROGRESS. Но в любом случае требуется лишь однажды
создать справочный текст, чтобы включать его в дальнейшем в любые приложения для работы на
любых платформах.
Для создания справочной информации по приложению можно использовать любой текстовой
процессор или настольную издательскую систему. Как только справочный текст написан, On-Line
Справочник может быть использован для включения его либо в приложение, либо в собственный
справочник операционной системы, если такой имеется. Дополнительно к тексту в справочник
можно включать картинки, графики и другую визуальную информацию.
Усовершенствованные справочные возможности
Кроме функции простого справочного текста, On-Line Справочник обеспечивает поддержку
следующих возможностей:
Гипертекстовые связи. Пользователи могут выделять слова
или фразы, по которым затем они могут перейти к соответствующим разделам
в справочнике. Подобный способ значительно облегчает конечным
пользователям процесс изучения Вашего приложения.
"Вырезать-И-Вставить". Пользователи могут "вырезать" из
справочника примеры и вставлять их в разрабатываемые приложения,
значительно ускоряя таким образом изучение PROGRESS-приложений. Данная
возможность также уменьшает стоимость поддержки приложений.
Аннотирование. Конечные пользователи могут расширять
использование справочника, добавляя в него собственные примечания. При
этом собственная справочная информация остается без изменений, а у
конечных пользователей появляется возможность сохранять информацию о
предыдущем сеансе работы с приложением.
В соответствии с соглашением PROGRESS о переносимости On-Line Справочник работает без
изменений на всех программно-аппаратных платформах, поддерживаемых PROGRESS. Подобная
переносимость снижает количество сил и средств, требуемых для документирования и поддержки
приложений при использовании их на самых разнообразных платформах.
Оптимизация и выбор плана выполнения запроса
Оптимизация выполнения SQL запросов и модули поддержки подобной оптимизации
(оптимизаторы или optimizers) играют крайне важную роль в реляционных СУБД. SQL запросы
определяют какие данные необходимо передать пользователю, но не говорят РСУБД о том, как
этот запрос обработать эффективно. Обычно существует большое количество возможностей
выполнения запроса. Оптимизаторы серверов баз данных отвечают за выбор наилучшей стратегии
выполнения. Поэтому скорость выполнения запросов в ведущей степени зависит от качества
оптимизатора данной РСУБД.
Результатом работы оптимизатора SQLBase является план выполнения запроса (execution plan).
Говоря упрощенно, execution plan - это последовательность шагов, которая указывает программе
серверу SQLBase, как выполнить запрос. В плане каждый шаг может быть однотабличным (single
table) или двухтабличным (two table). Все шаги производят результирующие таблицы (result tables).
Результирующая таблица не обязательно должна иметь материальное воплощение в виде
физического объекта. Для любого шага плана результирующая таблица может быть
пользовательской (user-defined), временной (temporary) или концептуальной (conceptual).
Однотабличный шаг плана
Однотабличный шаг плана выполнения запроса определяет исходную таблицу, метод доступа к
данным, используемый для извлечения строк таблицы, и имя результирующей таблицы (чаще
всего, концептуальной). В настоящее время SQLBase поддерживает следующие методы доступа к
данным:
Последовательное сканирование (Sequential Scan) - Это наиболее простой
из всех методов доступа. В этом считывается методе каждая страница данных,
принадлежащая исходной таблице. (Следует отметить, что все страницы базы
данных для данной таблицы связаны между собой, поэтому не требуется
сканирование всего файла базы данных).
Доступ по индексу (Index Access) - Существуют два способа использования
индекса. При первом, значение индекса известно, и индекс может быть
использован для позиционирования на индексной странице БД и последующего
извлечения данных непосредственно из индексной страницы. При втором
способе индексные страницы сканируются в возрастающем или убывающем
порядке для поиска положения индекса. Если запрос включает колонки
таблицы, не входящие в индекс, потребуются дополнительные операции для
считывания информации из страниц данных таблицы.
Хэшированный доступ (Hash Access) - В этом методе ключевое значение
используется для прямого извлечения информации из страницы данных,
которая содержит строки, удовлетворяющие значению ключа. Метод
преобразования ключа в адрес страницы, на которой он находится, носит
название "хэширование". Хэшированный доступ может быть использован
только в том случае, если для ключа создан хэшированный индекс и
предикатом является равенство "=".
Двухтабличный шаг плана
Двухтабличный шаг плана выполнения запроса определяет все исходные таблицы, метод доступа к
данным, используемый для извлечения строк из этих таблиц, метод объединения строк данных и
имя результирующей таблицы. Одна из исходных таблиц называется внешней, а другая -
внутренней. SQLBase поддерживает следующие методы объединения данных:
Вложенный цикл (Nested loop) и его вариации
Слияние индексов (Index merge)
Гибридное хэшированное объединение (Hybrid hashed join)
Пример схемы выполнения
В качестве примера рассмотрим базу данных типа поставщик-товар-поставка. База содержит 3
таблицы: S для поставщика, P для товара и SP - для поставок. Таблица S имеет уникальный
первичный ключ S#. Таблица P имеет уникальный первичный ключ P#. Таблица SP имеет
уникальный первичный ключ на колонках S#P#. Дополнительно, эта таблица содержит индексы
для колонок City, Color и Weight. Схема базы приведена на рис.5.
Рис. 5. Схема демонстрационной базы данных
| S | S#, SName, Status, City | SXS#(S#), SXCITY(City) |
| P | P#, PName, Color, Weight, City | PXP#(P#), PXCOLOR(Color), PXWEIGHT(Weight) |
| SP | S#, P#, QTY | SPXS#P#(S#, P#) |
Запрос 1: Select * from P where color = 'Red' and weight =19;
План выполнения
| 1 | P | PXWEIGHT | RESULT |
Для выполнения данного запроса у оптимизатора есть три варианта: 1) последовательное
сканирование, 2) индексный доступ с помощью индекса PXCOLOR и 3) индексный доступ с
помощью индекса PXWEIGHT. В данном случае, оптимизатор выбрал индекс PXWEIGHT.
Поэтому программа сервера будет использовать ключ weight (значение 19) для извлечения всех
строк, которые удовлетворяют условию "weight =19" и отфильтровывать те из них которые не
удовлетворяют второму условию (color = 'Red'). Оптимизатор предпочел индекс PXWEIGHT
индексу PXCOLOR, поскольку он посчитал, что в таблице существует меньше строк,
удовлетворяющих критерию выбора по ключу weight. Иными словами, индекс PXCOLOR является
более "плохим" и потребует больше операций ввода/вывода и команд процессора для выполнения
запроса. Результат запроса представляется в виде концептуальной таблицы RESULT.
Стоимостная модель оптимизации
Оптимизатор SQLBase использует так называемый стоимостной метод (cost-based technique) для
определения наилучшего плана выполнения запроса, в отличие от методов, основанных на анализе
синтаксиса (syntax-based) запроса или жестко установленных правилах выбора (rule-based).
Оптимизатор оценивает стоимость или затраты на работу процессора и операции ввода/вывода для
различных методов доступа к данным и операций над ними. Стоимость процессора оценивается в
миллисекундах. Стоимость ввода/вывода, которая представляет собой количество операций
ввода/вывода в секунду, также преобразуется в миллисекунды. Такой подход позволяет проводить
сравнение нагрузки на процессор и подсистему ввода/вывода. Производительность методов
доступа к данным и операций объединения зависит от размера и распределения данных.
Информация о данных представлена в виде статистики таблиц и индексов. Запрос разбивается на
ряд небольших индивидуальных шагов.
Наименьший шаг - это доступ к данным одной таблицы,
который выбирается из всех возможным методов доступа. При этом исследуются все возможности
выбора данных из таблицы, а также методы объединения между любыми двумя таблицами или
таблицей и промежуточным результатом. Оптимизатор выбирает наиболее простой и
эффективный план выполнения.
В реальной обстановке оптимизатор SQLBase выбирает план выполнения запроса на основе
вычисления затрат на выполнение целого ряда операций, которые помимо простого
использования процессора и подсистемы ввода/вывода включают следующие факторы:
Операции сравнения
Перемещение данных
Повторный доступ к той же таблице
Методы объединения данных
Использование буферов ввода/вывода
Распределение предикатов
Учет всех вышеприведенных факторов делает реальные формулы оптимизатора весьма сложными
и не позволяет привести их в рамках данной статьи.
Опыт применения методологий RAD и DATARUN в конкретных проектах
С. Лапин, Е. Фоминский, Г. Козлов, Е. Фоминская, Б. Позин,
Компания Аргуссофт (Москва)
Недостатки традиционного (каскадного) подхода к построению жизненного цикла программного обеспечения хорошо известны. Жестко зафиксированные требования к разрабатываемой системе в самом начале жизненного цикла, отсутствие в процессе реализации участия конечного пользователя приводят к тому, что проект растягивается на годы, выходит за рамки установленного бюджета, полученная в результате система не удовлетворяет требованиям пользователей.
Развитие информационных технологий, появление средств автоматизации практически всех этапов жизненного цикла привели к возникновению разнообразных моделей жизненных циклов современных информационных систем. Современные методологии разработки программных продуктов позволяют создавать в сжатые сроки системы высокого качества, удовлетворяющие требованиям пользователей. Многие из современных методологий поддерживаются современными инструментальными средствами.
Наиболее широкое распространение получила методология быстрой разработки приложений RAD (rapid application development), которая охватывает все этапы жизненного цикла современных информационных систем. В рамках методологии быстрой разработки приложений нашла воплощение методология проектирования DATARUN - методология проектирования от данных.
При использовании методологии проектирования от данных при разработке системы надзора для Национального Банка Республики Татарстан были получены схемы взаимодействия отдела надзора, деятельность которого автоматизировалась, с внешними организациями, модели деятельности отдела в виде диаграмм бизнес-процессов, временные диаграммы выполнения процессов, концептуальная модель данных автоматизируемой задачи. Результатами обследования деятельности отдела явились состав и содержание ролевых функций отдела, состав и содержание форм документов, выпускаемой отделом, описание программных средств, используемых в отделе. Анализ результатов обследования выявил направления совершенствования информатизации отдела и позволил сформулировать требования к доработке существующих систем и к интеграции приложений.
Использование современных технологий разработки и сопровождения программного обеспечения дало новые возможности:
Гибкость ориентации на "ролевые" функции
Переносимость ПО на другие платформы без перепрограммирования
Более высокая производительность в разработке и сопровождении
Упрощение реализации новых функциональных задач без перепрограммирования
На этапе проектирования системы концептуальная модель данных была преобразована в реляционную модель данных (структуру базы данных), создана архитектура информационной системы: схемы навигации экранов приложений, модели данных приложений, модели интерфейса (данных, спецификации, представления).

При создании системы была реализована спиральная модель жизненного цикла, было получено четыре прототипа системы, разработка каждого прототипа заняла четыре недели. В конце четвертого цикла прототипирования была получена полностью функциональная система, которая бала передана заказчику для опытной эксплуатации.
При создании первого прототипа были зафиксированы внешние представления системы, собраны замечания и предложения заказчика по реализованному составу ролевых функций, внешнему виду и функциональности системных модулей, замечания и предложения по проекту документации сопровождения. В состав первого прототипа вошли работающая версия системы, уточненная диаграмма автоматизируемых ролевых функций, список реализованных ролевых функций, реляционная модель данных системы и пояснительная записка к ней, архитектура системы в виде схемы навигации модулей, модели данных автоматизируемых функций и интерфейсных элементов, внешний вид интерфейсных элементов (на бумажном носителе), исходные тексты прикладного программного обеспечения (на магнитном носителе).
В результате предъявления первого прототипа заказчику были получены протокол рассмотрения итогов создания прототипа, список замечаний по составу ролевых функций, список замечаний по составу реализованных в базе данных системы сущностей предметной области, соглашение по внешнему виду системы с приложением к протоколу в виде бумажных копий экранов с замечаниями на них.
При реализации второго прототипа были зафиксированы перечень и состав ролевых функций системы и способы их реализации, структура базы данных системы, проверены выполнения требований к первому прототипу и сбор замечаний по функциональности экранов и логикам формирования отчетов.
Результатами второго прототипа явились протокол рассмотрения итогов создания 2-го прототипа, список замечаний по функциональности экранов и логикам формирования отчетов, приложение к протоколу в виде бумажных копий экранов с замечаниями на них.
Результаты третьего прототипа были аналогичны.
Перед вводом системы в опытную эксплуатацию были созданы рабочая база данных системы, рабочие места пользователей, системы автоматизированного версионного управления версиями ПО и автоматизированного сбора замечаний, проведено обучение пользователей.
| Файлы экранов | 217 |
| Файлы отчетов | 74 |
| Файлы меню | 33 |
| Файлы моделей архитектуры | 41 |
| Файлы моделей данных | 18 |
Oracle7 Server
Универсальный сервер Oracle позволяет Вам хранить и обрабатывать самые разные типы данных.
Кроме привычных структурированных данных (числа, строки, дата, время) Вы теперь можете
работать с неструктурированными данными, такими как тексты, многомерные пространственные
данные, изображения, видео, аудио. При этом Oracle обеспечит Вам надежность хранения и
быстроту доступа к этим данным, а так же возможность создания приложений, работающих со
всеми этими данными в комплексе.
Сегодня Oracle - это реляционная СУБД, поддерживающая язык SQL и его расширения для работы
с различными типами данных, а так же механизм транзакций. Особенности архитектуры Oracle
Server обеспечивают очень высокое быстродействие системы в многопользовательском режиме. По
результатам независимых тестов TPC Oracle всегда показывает лучшие результаты по
производительности. Оригинальный механизм многоверсионной записи позволяет получать
согласованные результаты при выполнении запросов без блокировки данных. Автоматически
выполняется блокировка данных на уровне записи при модификации данных. Это позволяет
увеличивать число пользователей системы без снижения ее производительности.
Встроенные оптимизаторы запросов, использование алгоритмов хеширования, битовых индексов
и B-деревьев, возможность тонкой настройки СУБД на возможности среды эксплуатации также
позволяют обеспечить очень высокое быстродействие. Дополнительная компонента ядра Parallel
Query Option позволяет ускорить работу существующих приложений за счет использования
возможностей многопроцессорных машин. Эта компонента резко снижает время выполнения
отдельного запроса, загрузки данных, построения индекса и т. д. за счет разбиения операций
(например оператора Select) на части и выполнения этих частей параллельно на разных
процессорах. Увеличение числа процессоров с 1 до 10 позволяет ускорить выполнение запроса в 8
раз, что очень важно для работы с очень большими БД.
Компоненты Oracle Parallel Server позволяет СУБД Oracle и Вашим приложениям работать на МРР
и кластерных архитектурах. Наиболее часто кластер реализуется на базе компьютеров фирм DЕC,
Sequent, HP, Sun, IBM (RS 6000). При этом все машины кластера могут работать с одной и той же
БД (что ускоряет и распараллеливает работу), а при выходе из строя одного из узлов кластера,
другие узлы аккуратно отработают отказ и возьмут на себя дальнейшую обработку данных.
Использование Oracle на кластере компьютеров позволяет относительно недорого обеспечить
высоконадежное и быстрое решение Ваших задач.
Oracle Server позволяет реализовать как односерверную, так и многосерверную архитектуру БД. В
случае многосерверной архитектуры узлы могут отстоять на большое расстояние, размещаться на
разных ОС и компьютерах, связываться по разным сетевым протоколам. На основе
многосерверной архитектуры Oracle позволяет реализовать как распределенную базу данных, так
и репликацию.
Компонента Distributed Option позволяет приложению работать с распределенной БД так же, как
с локальной. Автоматически реализуемый протокол 2х-фазной фиксации позволяет одновременно
модифицировать данные в разных узлах БД. Узлы всегда находятся в согласованном состоянии,
однако для этого требуется постоянное наличие связи между узлами. Механизм репликации не
требует постоянного наличия связи между узлами. Через заданные промежутки времени или при
восстановлении связи, изменения, сделанные в данном узле, будут отрабатываться в копиях таблиц
в других узлах. Можно реализовать не только простую репликацию (изменения распространяются
от таблицы - мастер к копиям), но и сложную репликацию (когда в узлах хранятся копии одной и
той же таблицы и их можно одновременно обновлять).
Сложную репликацию реализует компонента Advance Replcation Option, она же помогает задать
механизм разрешения возникающих коллизий. Oracle Server имеет средства для реализации Backup
копии Вашей базы, готовой быстро вступить в действие при уничтожении основной базы.
Вообще же Oracle обеспечивает надежную защиту Ваших данных как от несанкционированного
доступа (роли, привилегии, ограничения на использование ресурсов компьютера), так и от
всевозможных сбоев. Какой бы сбой не произошел (вплоть до уничтожения дисков), Вы всегда
имеете возможность восстановить свою систему либо к моменту, предшествовавшему сбою, либо к
заданному Вами моменту времени. При большинстве сбоев восстановление БД выполняется
автоматически.
Oracle позволяет реализовать системы, работающие непрерывно (24 часа, 7 дней в неделю). При
этом операции копирования и восстановления БД не снижают производительность работы
пользователей.
При создании приложений Вы можете часть обработки и контроля данных вынести на сервер.
Oracle реализует мощный механизм декларативных и процедурных ограничений целостности
(вплоть до каскадных операций), позволяет создавать хранимые процедуры, триггеры БД,
функции, алерты, пакеты процедур и функций, задавать расписание для автоматического
выполнения работ. Причем для создания процедурных объектов ненужно изучать новый язык. В
качестве процедурного языка 4GL используется расширение языка SQL, называемое PL/SQL.
Oracle Server - открытая система. Он поддерживает стандарт ODBC и может работать в среде
мониторов транзакций. В качестве узла распределенной БД Oracle можно использовать чужие
СУБД, например, DB2. Это реализуется за счет использования шлюзов Oracle к "чужой" СУБД.
Сегодня существуют шлюзы Oracle к десяткам промышленных СУБД.
Oracle позволяет создавать и поддерживать очень большие БД. Имеются средства для быстрого
копирования, восстановления, обработки таких баз. Летом 1995г. Oracle демонстрировал базу
размером 4 террабайта. На основе СУБД Oracle реализованы огромные хранилища разнородных
данных Data Warehouse, используемые для выполнения сложных задач анализа. В составе Oracle
Server появляются инструменты, позволяющие выполнять администрирование и настройку как
отдельных серверных узлов, так и распределенной БД. Имеется и NLS поддержка, так что Вы
можете, например, получать сообщения сервера БД на русском языке, использовать правила языка
при сортировке, работе с датой, строками символов и т. д.
Организация тиражирования данных в SQL Server 6.0:
Система тиражирования данных построена на метафоре подписки. В
процессе тиражирования участвуют следующие серверы сервер публикаций;
сервер репликаций;
сервер подписки.
Под публикацией понимается совокупность данных, которые могут подвергаться
тиражированию.
Статья - наименьший возможный элемент публикации. Статья может представлять собой таблицу
или любую ее часть. Публикация может включать одну или более статей.
Наиболее важным требованием к тиражированию данных является устойчивость к сбоям,
гарантирующая постоянное, надежное поступление данных и способная противостоять
возможным сбоям сети и оборудования. Система тиражирования должна обеспечивать высокое
быстродействие операций сохранения и переноса данных с минимальным воздействием на
центральный сервер и гарантией надежного и защищенного поступления информации. Она должна
быть достаточно гибкой, чтобы позволять организациям применять различные подходы и схемы
организации процесса тиражирования. Кроме того, поскольку организации не всегда могут себе
позволить иметь высококвалифицированного администратора в каждом подразделении, где
размещен конкретный сервер, система тиражирования должна быть хорошо интегрирована с
самой СУБД для получения возможности удаленного конфигурирования, мониторинга и
управления.
Microsoft создавала SQL Server 6.0 с учетом всех перечисленных требований. Подсистема
тиражирования данных, являющаяся составной частью SQL Server, позволяет осуществлять
автоматическое тиражирование транзакций и объектов базы данных с единого сервера на один
или более серверов, расположенных в географически разделенных подразделениях компании. SQL
Server 6.0 обладает следующими основными характеристиками:
Высокая производительность. Архитектура системы тиражирования
данных SQL Server обеспечивает высокую производительность с
минимальными задержками на сервере публикаций;
Надежная, защищенная передача информации. SQL Server 6.0
гарантирует целостность транзакций тиражируемых данных средствами
автоматической ресинхронизации и восстановления после сбоев. SQL Server
поддерживает новые расширения ANSI SQL Server, позволяющие описывать
принципы отбора/приема информации на уровне языка определения данных.
Кроме того, дополнительное шифрование данных при передаче по сети
гарантирует высокую защищенность тиражируемых данных от
несанкционированного доступа;
Гибкая реализация. SQL Server поддерживает несколько различных
моделей асинхронной репликации как с диспетчированием процесса, так и
непрерывных: тиражирование по журналу, тиражирование статических данных
(snapshot) и перемещение объектов. Богатство моделей тиражирования
позволяет организациям реализовывать различные подходы, стратегии
тиражирования и конфигурации сети. Помимо тиражирования транзакций и
пользовательских данных, SQL Server позволяет автоматизировать
тиражирование объектов баз данных (таких как хранимые процедуры), что
облегчает сопровождение систем, функционирующих в распределенных
средах;
Простота сопровождения и установки. Так, Microsoft реализовала в
SQL Server встроенные средства тиражирования данных, что снижает
сложность управления и позволяет использовать технологию Drag and Drop
для удаленного конфигурирования, управления и мониторинга. Система
тиражирования реализована на интуитивно понятной метафоре "издатель -
подписчик";
Расширяемость. Пользователи создают базы данных самого
разного типа, и Microsoft построила тиражирование данных вокруг стандартных
интерфейсов взаимодействия (таких как ODBC), что в будущем позволит
поддерживать тиражирование в неоднородных базах данных, включая и базы
данных, созданные средствами приложений для ПК.
Ключевые возможности по организации хранилищ
Ключевые возможности по организации хранилищ данных, которые были добавлены в Microsoft
SQL Server 6.5, включают:
Новые возможности CUBE и ROLLUP, добавленные в процессор запросов
Microsoft SQL Server, задача которых - облегчить для поставщиков
инструментальных средств и для пользователей создание мощных решений
для анализа данных, хранящихся в базах Microsoft SQL Server. Эти новые
утилиты позволяют создавать в прикладных программах сложные запросы,
которые за один шаг осуществляют многомерную группировку данных. При
использовании только ANSI SQL это осуществить весьма не просто.
Тиражирование данных в разнородных средах при помощи интерфейса
ODBC, который облегчит обмен данными в рамках предприятия.
Первоначально эта возможность будет реализована для платформ DB2, Oracle
и Sybase. Microsoft SQL Server 6.5 также будет поддерживать репликацию в
базы данных Microsoft Access, используемые на ПК.
Ряд новых возможностей по поддержке программируемых устойчивых
представлений данных, хранящихся на различных серверах. Разработчики
смогут поддерживать на настольном компьютере суммированные и
сгруппированные представления данных, которые хранятся на удаленных
серверах Microsoft SQL Server. Эти новые утилиты включают возможность
"перекачивания" данных с сервера на сервер посредством дистанционного
вызова процедур.
| Требования к системе | Windows NT Server 3.51 или выше, Intel® 386 или выше (рекомендуется 486 или Pentium), MIPS® R4xxx или системы на базе DEC™ Alpha AXP™, минимум 16 Mб RAM (минимум 32 Мб RAM, если сервер конфигурируется как сервер публикаций), 35 Mб на жестком диске, CD- ROM Кроме того, Microsoft SQL Workstation может работать на Windows NT Workstation версии 3.51 или более поздней | |
| Поддерживаемые сети и протоколы | В комплект поставки Microsoft SQL Server входит поддержка практически всех сетевых сред, включая: Novell® NetWare® IPX/SPX, Microsoft Named Pipes (включая Windows NT, Windows® for Workgroups, Windows 95, LAN Manager), TCP/IP sockets, Banyan® VINES®, DECNet™, AppleTalk®, сети с мультипротоколами | |
| Емкость системы | SQL Server адресует до 2 Гб памяти, до 8 терабайт дискового пространства, поддерживает до 32767 баз данных на один сервер. До 32767 одновременных пользовательских соединений на сервер. Неограниченное число таблиц и пользовательских объектов. Базы данных могут размещаться на нескольких физических дисках | |
| Число пользовательских соединений | 32767 15 (один пользователь) | SQL Server SQL Workstation |
| Поддерживаемые клиентские платформы | DOS, Windows, Windows NT, UNIX®, OS/2, Macintosh® |
[]
[]
[]
Открытая архитектура Delphi
С.Орлик, Borland International
Компания Borland в развитии своих объектно-ориентированных средств разработки явно пришла
к тому выводу, что повторное использование кода и объектная ориентация не являются
единственными средствами повышения производительности программистов. С появлением Delphi
разработчик может не только создавать и предоставлять своим коллегам готовые к использованию
компоненты, но и расширять функциональные возможности среды, в которой он работает, с
помощью так называемых "открытых интерфейсов". Такой подход позволяет использовать Delphi
уже в роли общего ядра набора инструментальных средств на всех этапах создания прикладных
систем - начиная с CASE-систем и заканчивая генерацией документации по создаваемым проектам,
с полной их интеграцией в "святая святых" любой среды программирования - IDE. Рассмотрим
основные возможности расширения функциональности среды Delphi для того, чтобы оценить
степень "открытости" архитектуры этого инструмента.
Открытая среда разработок клиент/сервер (CODE - Clent/Server Open Development Environment)
Платформа для разработок приложения в среде клиент/сервер должна включать все необходимые
технологии для создания приложений масштаба предприятия. PowerBuilder предоставляет отличный
набор базовых инструментов для работы, однако существует целый ряд продуктов, которые часто
используются для разработки информационных систем, например, системы контроля исходных
текстов, системы проектирования структур баз данных, дополнительные библиотеки классов и
системы автоматизированного тестирования, а также различные сервера баз данных, сетевые
продукты, системы управления документами и так далее.
Фирма Powersoft считает, что разработчики должны иметь свободу выбора лучших инструментов для
создания своих приложений. Начиная с 1992 года проводится программа CODE по интеграции
PowerBuilder и самых различных компонент среды клиент/сервер. PowerBuilder имеет открытые
опубликованные интерфейсы, используя которые можно интегрировать в его среду практически
любые необходимые инструменты.
Многие ведущие производители участвуют в программе CODE, интегрируя свои продукты в среду
PowerBuilder. Партнеров условно можно разделить на несколько категорий, которые перечислены
ниже с перечислением некоторых производителей.

Тестирование приложений особенно важно при быстром переходе к разработкам в среде
клиент/сервер. Тестирование представляет собой один из ключевых этапов в жизненном цикле
приложения. Среда Windows, основанная на графическом интерфейсе пользователя и управлении с
помощью сообщений, одна из наиболее сложных для отладки. Для эффективного тестирования
приложений используются специализированные инструменты для планирования, разработки, и
исполнения тестов приложений.
| Фирма | Название продукта |
| Software Quality Automation | TeamTest |
| Mercury Interactive | QA Partner |
| Seguie Software | PowerRunner |
| Softbridge | Automated Test Facility |
разработчики нуждаются в инструментах управления всеми техническими и организационными
аспектами поддержки проектов по разработке информационных систем. Критически важным для
успеха проекта является применение CASE - методологий для начальных фаз анализа и
проектирования. Со средой разработки PowerBuilder тесно интегрированы многие ведущие CASE
системы.
| Фирма | Название продукта |
| Chen & Assotiates | ER-Modeller |
| Intersolv | Excelerator |
| LBMS | System Engineer |
| Logic Works | ERwin/ERX |
| Visible Systems | Visible Analyst Workbench |
что существует множество общих компонент, которые часто повторно используются. Используя
мощные объектно-ориентированные средства PowerBuilder, многие компании предлагают такие
компоненты в виде библиотек классов и элементов управления.
| Фирма | Название продукта |
| Greenberg & Russel | Object Start |
| PowerServ | PowerTOOL |
| ServerLogic | PowerClass |
| Visual Tools | Formula One, ImageStream, First Impression |
версии. Каждый интерфейс использует все преимущества (например хранимые процедуры, расширения
языка SQL, декларативная ссылочная целостность и т.д.) и учитывает особенности (такие, как
различные типы данных, различные реализации работы с курсорами и т.д.) каждого конкретного
сервера баз данных. PowerBuilder также поддерживает стандарт ODBC для доступа к разнообразным
базам данных и файлам на персональных компьютерах.
| Фирма | Название продукта |
| Hewlett Packard | Allbase/SQL, Image/SQL |
| IBM | DB2/2, DB2/6000 |
| Informix | Online |
| Microsoft | SQL Server |
| Oracle | Oracle Server |
| Sybase | SQL Server, SQL Anywhere |
| Information Builders | EDA/SQL |
клиент/сервер опирается на разбиение приложения на компоненты, реализующие различные функции,
такие как хранение данных, деловая логика и интерфейс пользователя, и исполнение их на различных
машинах в сети с целью минимизировать нагрузку на сеть и оптимально использовать
вычислительные ресурсы. Такая организация называется трехуровневой (в более общем случае,
многоуровневой) архитектурой.
| Фирма | Название продукта |
| Gradient Technologies | Visual DCE |
| Tangent International | Distributed Computing Intergator for TopEnd |
| Tangent International | Distributed Computing Intergator for Tuxedo |
| Transarc | EncinaBuilder |
обращаться к значительным объемам неструктурированных данных по сети, управлять данными и
потоками информации в распределенной среде масштаба предприятия.
| Фирма | Название продукта |
| Lotus Development | Notes |
больших ЭВМ. Различные продукты для доступа к данным позволяют интегрировать их в
PowerBuilder, не прибегая к низкоуровневому программированию.
| Фирма | Название продукта |
| Attachmate Corp | Extra! |
| Wall Data | Rumba |
участвуют в программе CODE, позволяя разработчикам интегрировать эти технологии с
приложениями на PowerBuilder.
| Фирма | Название продукта |
| FileNet Corp | WorkFLO |
| Wang Laboratories | Wang OpenImage |
| Watermark Software | Watermark Discovery Edition |
представляет собой открытую среду для групповой разработки приложений и управления проектом.
Предоставляются прямые связи из среды PowerBuilder к лидирующим системам управления объектами
и контроля версий для управления разработкой объемных приложений.
| Фирма | Название продукта |
| Intersolv | PVCS |
| Legent Corp | Endevor |
| Mortice Kern Systems | RCS |
Открывается доступ в международные информационные сети
А для пользователей это означает:
У вас появляются новые способы ведения бизнеса: в сеть можно поместить свои прейскуранты
и другую информацию для всеобщего ознакомления, можно по электронной почте получать и
посылать заказы, выставлять клиентам счета, обсуждать и согласовывать тексты контрактов и
коммерческих предложений, посылать напоминания должникам и т.д.
Вы можете обращаться к огромным объемам информации по любым областям знаний,
гораздо большим, чем в любой самой крупной библиотеке. Это могут быть книги, справочники,
программы, материалы периодических изданий, различные базы данных, коммерческая реклама
и многое другое.
Вы можете вести деловую переписку по электронной почте с абонентами в любых уголках
мира
Вы приобретаете одну из самых удобных возможностей получения консультаций, советов,
помощи. Все серьезные фирмы, производящие компьютеры или программы, осуществляют сейчас
техническую поддержку своих пользователей через глобальные сети.
Наиболее известной фирмой, обеспечивающей коммуникационные возможности (или услуги
глобальной сети), является Internet. Каждое серьезное предприятие сегодня обязательно должно
иметь выход в Internet. Такую возможность начинают предоставлять многие корпоративные
системы.
Отладчик
Символьный отладчик позволяет отлаживать в исходных кодах программы на языке NewEra.
Основные возможности:
просмотр исходных модулей, входящих в программу, показ текущей
позиции выполнения;
пошаговое выполнение программ;
установка и снятие точек останова непосредственно в тексте модулей;
просмотр значений переменных, элементов массивов, компонентов
структур и объектов;
поиск фрагмента текста по всем модулям.
Отладчик Приложений (Application Debugger)
Отладчик Приложений предоставляет Вам полный набор средств для поиска, локализации и
исправления ошибок или ошибочных данных в любой из компонент приложения. Отладчик
позволяет проследить и понять логику работы программы, просмотреть содержимое буферов
приложения и переменных, просмотреть информацию о состоянии программной среды,
трассировать обработку событий. Используя Отладчик Приложений, Вы можете легко и быстро
протестировать приложения, уменьшая время разработки в частности и повышая надежность
приложения в целом.
Отслеживание передачи управления в приложении.
После того, как процедура загружена в Отладчик Приложений, легко видеть, какие параметры
приложения изменяются, какие операторы выполняются, какие процедуры вызываются из данной,
какие триггеры срабатывают. Отладчик позволяет установить точки прерывания на операторах
программы и просмотреть в них состояние буферов данных и значения переменных.
Просмотр объектных сообщений и информации о состоянии.
Применение Отладчика Приложений упрощает тестирование объектно-ориентированных
приложений, так как позволяет просмотреть состояние инкапсулированных объектов и методов
для данных и пользовательского интерфейса. Также, во время исполнения приложения возможно
производить отслеживание сообщений, посылаемых объектами.
Трассировка событий.
Для того, чтобы Вам было легче понять смысл событийно-управляемой модели программирования
PROGRESS, Отладчик Приложений позволяет просмотреть список событий, инициированных
действием пользователя, и легко проследить, какие триггеры срабатывают при этом.
Отладчик Приложений является полностью настраиваемым, предоставляя Вам возможности по
созданию макрокоманд, определению панелей и установке заранее определенных точек
пребывания и переменных для наблюдения. Все эти установки могут быть сохранены в
конфигурационном файле и загружены в любой момент времени.
Отладка (Debug)
Отладчик выполняет приложение в режиме отладки для поиска ошибок в работе программ и
объектов. Отладчик позволяет разработчику устанавливать очки прерывания, осуществлять
выполнение по шагам, просматривать и изменять значения переменных, а также сохранять среду
сеанса отладки для использования в будущем.
Отображение логического и физического уровня модели данных в ERwin
В ERwin существуют два уровня представления и моделирования - логический и физический .
Логический уровень означает прямое отображение фактов из реальной жизни. Например, люди,
столы, отделы, собаки и компьютеры являются реальными объектами. Они именуются на естественном
языке, с любыми разделителями слов (пробелы, запятые и т.д.). На логическом уровне не
рассматривается использование конкретной СУБД, не определяются типы данных (например, целое
или вещественное число) и не определяются индексы для таблиц.
Целевая СУБД, имена объектов и типы данных, индексы составляют второй (физический) уровень
модели ERwin.
ERwin предоставляет возможности создавать и управлять этими двумя различными уровнями
представления одной диаграммы (модели), равно как и иметь много вариантов отображения на
каждом уровне.
Отслеживание действий пользователей
Серверный продукт Sybase Audit Server записывает информацию о действиях пользователей в
специальную базу данных, доступную для анализа.
Параллельная загрузка
При работе с новой версией SQL Server можно запускать несколько параллельно работающих
копий BCP или SQL Enterprise Manager и выполнять параллельные перекрывающиеся операции
загрузки данных в SQL Server. Подобные возможности оказываются особенно полезными при
необходимости массивного копирования данных в ограниченные сроки.
Параллельное сканирование и асинхронное опережающее чтение
Параллельное сканирование и асинхронное опережающее чтение повышает на 40 - 400% скорость
выполнения некоторых типов запросов и других операций над базой данных в многопроцессорных
системах. Повышение производительности достигается за счет использования SQL Server 6.0
множественных потоков операционной системы и алгоритмов определения следующего блока
данных, необходимых для вывода в кэш. На приводимом графике показано, как растет время,
необходимое для считывания с диска более 10000 страниц из базы данных (меньшие числа
показывают более высокую производительность). Эта операция типична для длительного запроса
с вычислениями или операции создания отчета. Как видно из графика, по мере роста числа
клиентов, SQL Server 6.0 выполняет операцию не менее чем в 4 раза быстрее за счет использования
параллельного сканирования таблиц и асинхронного опережающего чтения.
Подобная технология обеспечивает резкое повышение производительности для любой операции,
требующей просмотра таблиц, например, SELECT, UPDATE и DELETE с необходимостью
поиска, CREATE INDEX, DBCC, DUMP/LOAD и т.п.
Pазработкa корпоративных систем с использованием современных инструментальных средств
Б.Вольфман, ЭЛКО Технологии

Технологии" - выполнение крупных проектов на базе современных информационных
технологий.
Переносимость и интероперабельность информационных систем и международные стандарты
Сергей Кузнецов
Программные продукты, которые сегодня принято называть информационными системами,
появились много лет назад. Первые информационные системы основывались на мейнфреймах
компании IBM, файловой системе ОС/360, а впоследствии на ранних СУБД типа IMS и IDMS. Эти
системы прожили долгую и полезную жизнь, многие из них до сих пор эксплуатируются. Но с
другой стороны, полная ориентация на аппаратные средства и программное обеспечение IBM
породила серьезную проблему "унаследованных систем" (legacy systems). Проблема состоит в том,
что производственный процесс не позволяет прекратить или даже приостановить использование
морально устаревших систем, чтобы перевести их на новую технологию. Многие серьезные
исследователи сегодня заняты попытками решить эту проблему. Это отдельная большая тема, но в
этом докладе мы серьезно рассматривать ее не будем.
Серьезность проблемы унаследованных систем очевидно показывает, что информационные
системы и лежащие в их основе базы данных являются слишком ответственными и дорогими
продуктами, чтобы можно было позволить себе их переделку при смене аппаратной платформы
или даже системного программного обеспечения (главным образом, операционной системы и
СУБД). Для этого программный продукт должен обладать свойствами легкой переносимости с
одной аппаратно-программной платформы на другую. (Это не означает, что при переносе не могут
потребоваться какие-нибудь изменения в исходных текстах; главное, чтобы такие изменения не
означали переделки системы.)
Другим естественным требованием к современным информационным системам является
способность наращивания их возможностей за счет использования дополнительно разработанных,
а еще лучше, уже существующих программных компонентов. Для этого требуется обеспечение
свойства, называемого интероперабельностью. Под этим понимается соблюдение определенных
правил или привлечение дополнительных программных средств, обеспечивающих возможность
взаимодействия независимо разработанных программных модулей, подсистем или даже
функционально завершенных программных систем.
Каким же образом можно одновременно удовлетворить оба эти требования уже на стадии
проектирования и разработки информационной системы? Ответом, который мне нравится и
кажется правильным, является следующий: следуйте принципам Открытых Систем. Другими
словами, максимально строго придерживайтесь международных или общепризнанных
фактических стандартов во всех необходимых областях.
Рассмотрим немного подробнее, какие стандарты следует иметь в виду при разработке
информационной системы сегодня. При использовании текущей технологии информационная
система пишется на некотором языке программирования, в нее встраиваются операторы языка
SQL и, наконец, включает какие-либо вызовы библиотечных функций операционной системы.
Соответственно, прежде всего следует обращать внимание на степень стандартизированности
используемого языка программирования. На сегодняшний день приняты международные
стандарты языков Фортран, Паскаль, Ада, Си и, совсем недавно, Си++. Понятно, что Фортран,
даже в своем наиболее развитом виде стандарта Фортран-95, не является языком, подходящим для
программирования информационных систем. Паскаль - очень приятный язык, но чтобы не
испортить впечатление от его приятности, в стандарт не включены средства раздельной
компиляции. Конечно, в принципе можно оформить полный исходный текст в виде одного
текстового файла, но вряд ли это разумно и практично. Язык Ада, вообще говоря, пригоден для
любых целей. На нем можно писать и информационные системы (что, кстати и делают
американские и некоторые отечественные военные). Но что-то не видно счастливых прикладных
программистов, использующих язык Ада. Уж больно он громоздкий...
По мнению многих программистов, наиболее хороший стандарт на сегодняшний день существует
для языка Си. Опыт нескольких лет, прошедших после принятия стандарта, показывает, что при
грамотном использовании стандарта Си ANSI/ISO проблемы переноса программ, связанные с
особенностями аппаратуры или компиляторов, практически не возникают (если учитывать
имеющиеся в самом стандарте рекомендации по созданию переносимых программ). Этих
нескольких лет оказалось достаточно, чтобы обеспечить полное соответствие стандарту
практически всех индустриальных компиляторов языка Си. Даже если в реализации допускаются
расширения стандарта (как, например, в компиляторе Ричарда Столлмана из проекта GNU GCC),
то имеются опции компилятора, позволяющие контролировать выход за границы стандарта.
Очень важно, что в стандарте ANSI Си специфицирован не только язык, но и базовые библиотеки
стандартной системы программирования (в частности, основные компоненты библиотеки
ввода/вывода). Наличие стандарта на библиотечные функции и его строгое соблюдение в
реализациях в ряде случаев позволяет создавать не очень сложные приложения, переносимые не
только между разными аппаратными платформами, но и между различными операционными
средами.
Прошлым летом был, наконец, принят стандарт Си++. Видимо, это означает (по крайней мере, на
это можно надеяться), что еще через несколько лет можно будет говорить о мобильном
программировании на Си++ в том же смысле, в котором можно говорить об этом сегодня по
отношению к Си. С другой стороны, трудно надеяться, что действительно стандартные
компиляторы появятся очень быстро: слишком сильно сегодня расходятся реализационные
варианты языка Си++.
Почему, имея в виду взаимодействия с базами данных, мы говорим про язык SQL, и что с ним
происходит? Здесь все не очень просто. SQL с самого своего зарождения являлся сложным языком
со смешанной декларативно-процедурной семантикой, не идеальным синтаксисом, а кроме того,
всегда содержал ряд темных мест (объем доклада не позволяет даже привести примеры). Тем не
менее, судьба распорядилась так, что именно SQL стал единственным практически используемым
языком реляционных баз данных, хотя имелись и другие кандидаты, в частности, язык системы
Ingres Quel.
В результате длительного процесса стандартизации языка к настоящему времени имеется два
принятых международных стандарта SQL - SQL/89 и SQL/92.
Стандарт SQL/89 очень слабый,
многие важные аспекты в нем не определены или оставлены для определения в реализации. С
другой стороны, большинство современных коммерческих реляционных СУБД на самом деле
соответствует стандарту SQL/89 (этого не очень сложно добиться по причине отмеченной выше
слабости стандарта).
Стандарт SQL/92 является существенно более продвинутым. В нем точно специфицированы такие
важные аспекты, как средства манипулирования схемой базы данных, динамический SQL,
расширены возможности языка для формулировки запросов в алгебраическом стиле и т.д. Однако
язык SQL/92 настолько сложен, что к настоящему времени нет практически ни одной СУБД, в
которой он был бы полностью реализован (как правило, реализуется расширенное подмножество
языка).
Ситуация не из приятных. Но тем не менее, внимательный анализ языка показывает, что имеется
практическая возможность создания достаточно переносимых программ с использованием SQL/89.
Для это нужно максимально локализовать те части программы, которые содержат
нестандартизованные конструкции, и стараться не использовать расширения языка, предлагаемые
в конкретной реализации. Понятно, что для этого требуется хорошее знание как SQL/89, так и
особенностей диалекта, реализованного в используемом продукте. К сожалению, в отличие от
ситуации со стандартом языка Си, стандарт SQL/89 не слишком помогает в решении этой
проблемы. В этом стандарте полностью отсутствуют какие-либо рекомендации для мобильного
программирования информационных систем.
Между прочим, аналогичная ситуация существует и в области операционных систем.
Существующий сегодня набор стандартов происходит от интерфейсов операционной системы
UNIX (SVID, POSIX, XPG и т.д.). В большинстве современных операционных систем эти
стандарты поддерживаются, но, как правило, любая ОС содержит множество дополнительных
средств. При этом, естественно, наименее стандартизованы наиболее современные и продвинутые
решения (их просто не успевают стандартизовать).
Наверное, сегодня самым ярким примером
печального положения дел является полная нестандартизованность средств "легковесных
процессов" (threads). Нельзя сказать, что процессы, работающие на общей виртуальной памяти,
действительно обеспечивают возможность параллельного программирования в среде
симметричных мультипроцессорных систем. Это затруднительный в отладке и чреватый скрытыми
(редко проявляющимися) ошибками способ программирования. Однако на сегодняшний день
наука программирования все еще не может предложить более надежный и простой при
использовании подход. Конечно, очень жаль, что отсутствует стандартизация threads.
Если стремиться к достижению переносимости приложения, то следует стараться ограничить себя
минимально достаточным набором стандартных средств. В случае, когда нестандартное решение
некоторой операционной системы позволяет существенно оптимизировать работу
информационной системы, разумно предельно локализовать те места программы, в которых это
решение используется.
То, о чем мы говорили до сих пор, относится большей частью к сравнительно небольшим и
сравнительно централизованным системам (конечно, даже сравнительно централизованные
системы сегодня, как правило, основываются на архитектуре "клиент-сервер"). Однако, если иметь
в виду более масштабные проекты, реализуемые не в локальных, а как минимум корпоративных
сетях, то проблема обеспечения интероперабельности отдельно спроектированных и
разработанных программных компонентов существенно усложняется. При создании крупных
распределенных программных систем практически невозможно обязать многочисленных
разработчиков следовать общей технологии (может быть и потому, что общепринятая технология
сегодня отсутствует).
У разных людей разные вкусы и пристрастия. Одни предпочитают работать в среде открытых
систем (например, с использованием языков Си или Си++ в UNIX-совместимом операционном
окружении). Других больше устраивает замкнутая среда Smalltalk. В конечном же счете система
должна быть интегрирована и по мере возможности обладать достаточной эффективностью.
Проследим наиболее важные вехи в процессе обеспечения интероперабельности распределенных
программных компонентов. Возможно, это частная точка зрения, но кажется, что первым шагом
был механизм "программных гнезд" (sockets), разработанный в университете Беркли. Основным
достижением этой разработки было то, что с использованием единого механизма межпроцессных
взаимодействий можно было интегрировать программные компоненты, произвольным образом
распределенные в локальных или территориально распределенных сетях. (Конечно, мы должны
заметить, что в каждом узле сети должен был поддерживаться механизм программных гнезд.)
Основным недостатком программных гнезд является то, что это чисто транспортный механизм. В
частности, представление передаваемых по сети данных является машинно-зависимым.
Следовательно, в каждом узле сети (если она гетерогенна, а это общий случай) нужно уметь
правильно преобразовывать представление данных, получаемых из любого другого узла. Понятно,
что это образует серьезную техническую проблему.
Следующим шагом (очень важным шагом) явилось появление протокола вызова удаленных
процедур (Remote Procedure Calls - RPC) и его реализация. Идея этого механизма очень проста. В
большинстве случаев взаимодействие программных компонентов является асимметричным.
Практически всегда можно выделить клиента, которому требуется некоторая услуга, и сервер,
который такую услугу способен оказать. Более того, как правило, клиент не может продолжать
свое выполнение, пока сервер не произведет требуемые от него действия. Другими словами,
типичным взаимодействием клиента и сервера является процедурное взаимодействие. С точки
зрения клиентской программы обращение к серверу ничем не отличается от вызова локальной
процедуры. При реализации механизма вызова удаленных процедур на основании спецификации
интерфейса процедуры на стороне клиента генерируется локальный представитель удаленной
процедуры - stub, а на стороне сервера - специализированный переходник - proxy.
Очень полезной составляющей ( относительно независимой от других составляющих) семейства
протоколов RPC является протокол внешнего представления данных (External Data Representation
- XDR). В этом протоколе специфицировано машинно-независимое представление данных,
понимаемых механизмом RPC. Идея состоит в том, что при передаче параметров вызова
удаленной процедуры и при получении ее ответных параметров происходит двойное
преобразование данных сначала из исходного машинно-зависимого формата в формат XDR, а
затем из этого формата в машинно-зависимый целевой формат. В результате взаимодействующие
программы избавлены от потребности знания специфики машинно-зависимых представлений
данных. Возможно, именно протокол XDR обладает определяющим значением в связке
протоколов вызова удаленных процедур (хотя, конечно, возможности XDR довольно
ограничены).
Наконец, видимо наиболее перспективным на сегодняшний день является подход, предложенный и
специфицированный международным консорциумом Object Management Group (OMG). Опять-
таки, основная идея проста. Как бы мы не стремились выработать единые языковые средства для
разработки распределенных информационных систем, похоже, что это стремление останется среди
других благородных, но недостижимых задач человечества. Унификация невозможна. Имеется
много разных подходов, каждый из которых в чем-то превосходит другие. Нельзя сказать, что
какой-то подход является определяющим. Пожалуй, единственное, на чем сходится подавляющее
большинство исследователей и разработчиков распределенных программных систем, это
склонность к использованию парадигмы объектной ориентации.
Не будем подробно останавливаться на преимуществах этой парадигмы (об этом давно написаны
целые книги). Однако все-таки заметим, что объектно-ориентированный стиль проектирования и
разработки программных систем (и в особенности информационных систем) стимулирует
повторное использование программных компонентов (за счет наличия механизма наследования
классов), обеспечивает независимость использования информационных ресурсов от особенностей
их реализации (за счет применения принципов инкапсуляции), наконец, при проектировании и
разработке информационных систем позволяет производить комплексную разработку структур
данных и управляющих ими процедур (с применением технологии объектно-ориентированных
систем баз данных).
Все это прекрасно. Но проблема состоит в том, что отсутствует общая объектная модель. В разных
объектно-ориентированных системах программирования и системах баз данных гораздо больше
общего, чем различного, но их различия часто принципиальны настолько, что объекты,
разработанные и созданные в разных системах, не способны взаимодействовать. Они не понимают
друг друга, они не интероперабельны. А это, конечно, очень плохо. Особенно плохо по той
причине, что постоянное наращивание возможностей Internet делает принципиально возможным
использование информационных ресурсов вне зависимости от их реального расположения.
Активность OMG предлагает ограниченное, но практически достижимое решение этой проблемы.
Это общая архитектура Object Management Architecture (OMA) и ее конкретное воплощение
Common Object Request Broker Architecture (CORBA). Мы остановимся только на наиболее
ключевых аспектах. Прежде всего, поскольку на сегодня отсутствует (и вряд ли появится в
ближайшем будущем) объектная модель, которая могла бы служить "общей крышей" для
существующих объектно-ориентированных языков и систем программирования, то единственным
практически возможным выходом была выработка минимальной объектной модели, обладающей
ограниченными возможностями, но имеющая явные аналоги в наиболее распространенных
объектных системах. В архитектуре CORBA такая минимальная модель называется Core Object
Model, и ей соответствует язык спецификации (не программирования!) интерфейсов объектов
Interface Definition Language (IDL).
Чтобы обеспечить возможность взаимодействия объекта, существующего в одной системе
программирования, с некоторым объектом из другой системы программирования, в исходный
текст первого объекта (правильнее сказать, его класса) должна быть помещена спецификация на
языке IDL интерфейса того объекта, метод которого должен быть вызван. Аналогичная
спецификация должна быть помещена на стороне вызываемого объекта. Далее исходные тексты
должны быть обработаны соответствующим прекомпилятором IDL (таких прекомпиляторов
должно иметься ровно столько, сколько поддерживается интероперабельных объектных сред;
сегодня специфицированы правила встраивания IDL в программы на языках Си, Си++ и
Smalltalk). Спецификация интерфейса объекта на языке IDL представляет собой главным образом
набор сигнатур методов объекта. В каждой сигнатуре определяется имя метода, список имен и
типов данных входных параметров, а также список имен и типов данных результатов выполнения
метода. Кроме того, IDL позволяет определять структурные типы данных (конечно,
прекомпилятор IDL на основе определений таких типов производит спецификации типов целевой
системы программирования)
Что же является результатом работы прекомпилятора? Все очень похоже на RPC... На стороне
клиента генерируется текст объекта-stub, который играет роль локального представителя
удаленного объекта (с ограничениями, свойственными IDL). Работа с этим объектом-посредником
происходит по правилам соответствующей системы программирования: в среде Си++ stub - это
объект Си++, в среде Smalltalk - это объект Smalltalk и т.д. С другой стороны, в коде,
генерируемом в stub, заложены знания о том, что требуется сделать для обращения к методу
удаленного объекта.
На стороне сервера генерируется текст объекта-sceleton, своего рода посредника при доступе к
удаленному объекту. С одной стороны, sceleton "знает", что обращение является удаленным. С
другой стороны такой посредник умеет обращаться к удаленному объекту по правилам его
системы программирования.
Конечно, для доставки сообщения от клиента к серверу и получения ответных результатов должен
существовать системный (вернее, полусистемный - middle-ware) компонент, отвечающий именно за
выполнение таких функций. В архитектуре CORBA такой компонент называется брокером
объектных заявок (Object Request Broker - ORB). В функции ORB главным образом входит
передача данных в машинно-независимом формате от клиента серверу и от сервера клиенту. Кроме
того, ORB отвечает за правильное указание сетевого адреса объекта-сервера.
Интерфейс между stub, sceleton и ORB основан на специфицированном в описании архитектуры
CORBA интерфейсе прикладного уровня (Application Programmer Interface - API). Этот интерфейс
на самом деле открыт для программистов. На нем основан метод динамического вызова объектов
без потребности спецификации их интерфейсов на языке IDL. Естественно, программирование на
уровне API ORB является гораздо более обременяющим делом, чем если бы использовался IDL.
Однако иногда интерфейсы вызываемых удаленных объектов просто неизвестны в статике; их
можно получить только на стадии выполнения программы, и тогда без использования API
обойтись не удается.
OMG не обладает правами международной организации по стандартизации. Тем не менее,
принимаемые в этой организации документы обладают исключительно высоким международным
авторитетом и становятся фактическими стандартами. Проблемой стандарта OMG CORBA было
то, что отсутствовала стандартизация взаимодействий уровня ORB-ORB. В результате ORB'ы,
производимые разными компаниями, не могли совместно работать. Теперь уже ORB'ы не
понимали друг друга. В прошлом году OMG приняла новый стандарт CORBA-2, в котором
специфицирован протокол взаимодействий между ORB'ами. Реализации этого протокола уже
появились, и имеется надежда на реальное использование информационных ресурсов Internet. Дай-
то Бог!
Конечно, CORBA - это далеко не все, что требуется. Это всем понятно, но далеко не понятно, а что
же нужно. Это ужасно сложная и непонятная тема - семантическая интероперабельность объектных
систем.
[]
[]
[]
