Анализ программы
Компилятор, анализируя программу, сразу разделяет ее на:
пробелы (white spaces);комментарии (comments);основные лексемы (tokens).
Арифметические операции
Наряду с четырьмя обычными арифметическими операциями +, -, *, /, существует оператор получения остатка от деления %, который может быть применен как к целочисленным аргументам, так и к дробным.
Работа с целочисленными аргументами подчиняется простым правилам. Если делится значение a на значение b, то выражение (a/b)*b+(a%b) должно в точности равняться a. Здесь, конечно, оператор деления целых чисел / всегда возвращает целое число. Например:
9/5 возвращает 1 9/(-5) возвращает -1 (-9)/5 возвращает -1 (-9)/(-5) возвращает 1
Остаток может быть положительным, только если делимое было положительным. Соответственно, остаток может быть отрицательным только в случае отрицательного делимого.
9%5 возвращает 4 9%(-5) возвращает 4 (-9)%5 возвращает -4 (-9)%(-5) возвращает -4
Попытка получить остаток от деления на 0 приводит к ошибке.
Деление с остатком для дробных чисел может быть произведено по двум различным алгоритмам. Один из них повторяет правила для целых чисел, и именно он представлен оператором %. Если в рассмотренном примере деления 9 на 5 перейти к дробным числам, значение остатка во всех вариантах не изменится (оно будет также дробным, конечно).
9.0%5.0 возвращает 4.0 9.0%(-5.0) возвращает 4.0 (-9.0)%5.0 возвращает -4.0 (-9.0)%(-5.0) возвращает -4.0
Однако стандарт IEEE 754 определяет другие правила. Такой способ представлен методом стандартного класса Math.IEEEremainder(double f1, double f2). Результат этого метода – значение, которое равно f1-f2*n, где n – целое число, ближайшее к значению f1/f2, а если два целых числа одинаково близки к этому отношению, то выбирается четное. По этому правилу значение остатка будет другим:
Math.IEEEremainder(9.0, 5.0) возвращает -1.0 Math.IEEEremainder(9.0, -5.0) возвращает -1.0 Math.IEEEremainder(-9.0, 5.0) возвращает 1.0 Math.IEEEremainder(-9.0, -5.0) возвращает 1.0
Унарные операторы инкрементации ++ и декрементации --, как обычно, можно использовать как справа, так и слева.
int x=1; int y=++x;
В этом примере оператор ++ стоит перед переменной x, это означает, что сначала произойдет инкрементация, а затем значение x будет использовано для инициализации y. В результате после выполнения этих строк значения x и y будут равны 2.
int x=1; int y=x++;
А в этом примере сначала значение x будет использовано для инициализации y, и лишь затем произойдет инкрементация. В результате значение x будет равно 2, а y будет равно 1.
Битовые операции
Прежде чем переходить к битовым операциям, необходимо уточнить, каким именно образом целые числа представляются в двоичном виде. Конечно, для неотрицательных величин это практически очевидно:
0 0 1 1 2 10 3 11 4 100 5 101
и так далее. Однако как представляются отрицательные числа? Во-первых, вводят понятие знакового бита. Первый бит начинает отвечать за знак, а именно 0 означает положительное число, 1 – отрицательное. Но не следует думать, что остальные биты остаются неизменными. Например, если рассмотреть 8-битовое представление:
-1 10000001 // это НЕВЕРНО! -2 10000010 // это НЕВЕРНО! -3 10000011 // это НЕВЕРНО!
Такой подход неверен! В частности, мы получаем сразу два представления нуля – 00000000 и 100000000, что нерационально. Правильный алгоритм можно представить себе так. Чтобы получить значение -1, надо из 0 вычесть 1:
00000000 - 00000001 ------------ - 11111111
Итак, -1 в двоичном виде представляется как 11111111. Продолжаем применять тот же алгоритм (вычитаем 1):
0 00000000 -1 11111111 -2 11111110 -3 11111101
и так далее до значения 10000000, которое представляет собой наибольшее по модулю отрицательное число. Для 8-битового представления наибольшее положительное число 01111111 (=127), а наименьшее отрицательное 10000000 (=-128). Поскольку всего 8 бит определяет 28=256 значений, причем одно из них отводится для нуля, то становится ясно, почему наибольшие по модулю положительные и отрицательные значения различаются на единицу, а не совпадают.
Как известно, битовые операции "и", "или", "исключающее или" принимают два аргумента и выполняют логическое действие попарно над соответствующими битами аргументов. При этом используются те же обозначения, что и для логических операторов, но, конечно, только в первом (одиночном) варианте. Например, вычислим выражение 5&6:
00000101 & 00000110 ------------- 00000100
// число 5 в двоичном виде // число 6 в двоичном виде
//проделали операцию "и" попарно над битами // в каждой позиции
То есть выражение 5&6 равно 4.
Исключение составляет лишь оператор "не" или "NOT", который для побитовых операций записывается как ~ (для логических было !). Этот оператор меняет каждый бит в числе на противоположный. Например, ~(-1)=0. Можно легко установить общее правило для получения битового представления отрицательных чисел:
Если n – целое положительное число, то -n в битовом представлении равняется ~(n-1).
Наконец, осталось рассмотреть лишь операторы побитового сдвига. В Java есть один оператор сдвига влево и два варианта сдвига вправо. Такое различие связано с наличием знакового бита.
При сдвиге влево оператором << все биты числа смещаются на указанное количество позиций влево, причем освободившиеся справа позиции заполняются нулями. Эта операция аналогична умножению на 2n и действует вполне предсказуемо, как при положительных, так и при отрицательных аргументах.
Рассмотрим примеры применения операторов сдвига для значений типа int, т.е. 32-битных чисел. Пусть положительным аргументом будет число 20, а отрицательным -21.
// Сдвиг влево для положительного числа 20 20 << 00 = 00000000000000000000000000010100 = 20 20 << 01 = 00000000000000000000000000101000 = 40 20 << 02 = 00000000000000000000000001010000 = 80 20 << 03 = 00000000000000000000000010100000 = 160 20 << 04 = 00000000000000000000000101000000 = 320 ... 20 << 25 = 00101000000000000000000000000000 = 671088640 20 << 26 = 01010000000000000000000000000000 = 1342177280 20 << 27 = 10100000000000000000000000000000 = -1610612736 20 << 28 = 01000000000000000000000000000000 = 1073741824 20 << 29 = 10000000000000000000000000000000 = -2147483648 20 << 30 = 00000000000000000000000000000000 = 0 20 << 31 = 00000000000000000000000000000000 = 0 // Сдвиг влево для отрицательного числа -21 -21 << 00 = 11111111111111111111111111101011 = -21 -21 << 01 = 11111111111111111111111111010110 = -42 -21 << 02 = 11111111111111111111111110101100 = -84 -21 << 03 = 11111111111111111111111101011000 = -168 -21 << 04 = 11111111111111111111111010110000 = -336 -21 << 05 = 11111111111111111111110101100000 = -672 ... -21 << 25 = 11010110000000000000000000000000 = -704643072 -21 << 26 = 10101100000000000000000000000000 = -1409286144 -21 << 27 = 01011000000000000000000000000000 = 1476395008 -21 << 28 = 10110000000000000000000000000000 = -1342177280 -21 << 29 = 01100000000000000000000000000000 = 1610612736 -21 << 30 = 11000000000000000000000000000000 = -1073741824 -21 << 31 = 10000000000000000000000000000000 = -2147483648
Как видно из примера, неожиданности возникают тогда, когда значащие биты начинают занимать первую позицию и влиять на знак результата.
При сдвиге вправо все биты аргумента смещаются на указанное количество позиций, соответственно, вправо. Однако встает вопрос – каким значением заполнять освобождающиеся позиции слева, в том числе и отвечающую за знак. Есть два варианта. Оператор >> использует для заполнения этих позиций значение знакового бита, то есть результат всегда имеет тот же знак, что и начальное значение. Второй оператор >>> заполняет их нулями, то есть результат всегда положительный.
// Сдвиг вправо для положительного числа 20 // Оператор >> 20 >> 00 = 00000000000000000000000000010100 = 20 20 >> 01 = 00000000000000000000000000001010 = 10 20 >> 02 = 00000000000000000000000000000101 = 5 20 >> 03 = 00000000000000000000000000000010 = 2 20 >> 04 = 00000000000000000000000000000001 = 1 20 >> 05 = 00000000000000000000000000000000 = 0 // Оператор >>> 20 >>> 00 = 00000000000000000000000000010100 = 20 20 >>> 01 = 00000000000000000000000000001010 = 10 20 >>> 02 = 00000000000000000000000000000101 = 5 20 >>> 03 = 00000000000000000000000000000010 = 2 20 >>> 04 = 00000000000000000000000000000001 = 1 20 >>> 05 = 00000000000000000000000000000000 = 0
Очевидно, что для положительного аргумента операторы >> и >>> работают совершенно одинаково. Дальнейший сдвиг на большее количество позиций будет также давать нулевой результат.
// Сдвиг вправо для отрицательного числа -21 // Оператор >> -21 >> 00 = 11111111111111111111111111101011 = -21 -21 >> 01 = 11111111111111111111111111110101 = -11 -21 >> 02 = 11111111111111111111111111111010 = -6 -21 >> 03 = 11111111111111111111111111111101 = -3 -21 >> 04 = 11111111111111111111111111111110 = -2 -21 >> 05 = 11111111111111111111111111111111 = -1 // Оператор >>> -21 >>> 00 = 11111111111111111111111111101011 = -21 -21 >>> 01 = 01111111111111111111111111110101 = 2147483637 -21 >>> 02 = 00111111111111111111111111111010 = 1073741818 -21 >>> 03 = 00011111111111111111111111111101 = 536870909 -21 >>> 04 = 00001111111111111111111111111110 = 268435454 -21 >>> 05 = 00000111111111111111111111111111 = 134217727 ... -21 >>> 24 = 00000000000000000000000011111111 = 255 -21 >>> 25 = 00000000000000000000000001111111 = 127 -21 >>> 26 = 00000000000000000000000000111111 = 63 -21 >>> 27 = 00000000000000000000000000011111 = 31 -21 >>> 28 = 00000000000000000000000000001111 = 15 -21 >>> 29 = 00000000000000000000000000000111 = 7 -21 >>> 30 = 00000000000000000000000000000011 = 3 -21 >>> 31 = 00000000000000000000000000000001 = 1
Как видно из примеров, эти операции аналогичны делению на 2n. Причем, если для положительных аргументов с ростом n результат закономерно стремится к 0, то для отрицательных предельным значением является -1.
Целочисленные литералы
Целочисленные литералы позволяют задавать целочисленные значения в десятеричном, восьмеричном и шестнадцатеричном виде. Десятеричный формат традиционен и ничем не отличается от правил, принятых в других языках. Значения в восьмеричном виде начинаются с нуля, и, конечно, использование цифр 8 и 9 запрещено. Запись шестнадцатеричных чисел начинается с 0x или 0X (цифра 0 и латинская ASCII-буква X в произвольном регистре). Таким образом, ноль можно записать тремя различными способами:
0 00 0x0
Как обычно, для записи цифр 10-15 в шестнадцатеричном формате используются буквы A, B, C, D, E, F, прописные или строчные. Примеры таких литералов:
0xaBcDeF, 0xCafe, 0xDEC
Типы данных рассматриваются ниже, однако здесь необходимо упомянуть два целочисленных типа int и long длиной 4 и 8 байт, соответственно (или 32 и 64 бита, соответственно). Оба эти типа знаковые, т.е. тип int хранит значения от -231 до 231-1, или от -2.147.483.648 до 2.147.483.647. По умолчанию целочисленный литерал имеет тип int, а значит, в программе допустимо использовать литералы только от 0 до 2147483648, иначе возникнет ошибка компиляции. При этом литерал 2147483648 можно использовать только как аргумент унарного оператора - :
int x = -2147483648; \\ верно int y = 5-2147483648; \\ здесь возникнет \\ ошибка компиляции
Соответственно, допустимые литералы в восьмеричной записи должны быть от 00 до 017777777777 (=231-1), с унарным оператором - допустимо также -020000000000 (= -231). Аналогично для шестнадцатеричного формата – от 0x0 до 0x7fffffff (=231-1), а также -0x80000000 (= -231).
Тип long имеет длину 64 бита, а значит, позволяет хранить значения от -263 до 263-1. Чтобы ввести такой литерал, необходимо в конце поставить латинскую букву L или l, тогда все значение будет трактоваться как long. Аналогично можно выписать максимальные допустимые значения для них:
9223372036854775807L 0777777777777777777777L 0x7fffffffffffffffL // наибольшие отрицательные значения: -9223372036854775808L -01000000000000000000000L -0x8000000000000000L
Другие примеры целочисленных литералов типа long:
0L, 123l, 0xC0B0L
Дополнение. Работа с операторами
Рассмотрим некоторые детали использования операторов в Java. Здесь будут описаны подробности, относящиеся к работе самих операторов. В следующей лекции детально рассматриваются особенности, возникающие при использовании различных типов данных (например, значение операции 1/2 равно 0, а 1/2. равно 0.5).
Дробные литералы
Дробные литералы представляют собой числа с плавающей десятичной точкой. Правила записи таких чисел такие же, как и в большинстве современных языков программирования.
Примеры:
3.14 2. .5 7e10 3.1E-20
Таким образом, дробный литерал состоит из следующих составных частей:
целая часть;десятичная точка (используется ASCII-символ точка);дробная часть;показатель степени (состоит из латинской ASCII-буквы E в произвольном регистре и целого числа с опциональным знаком + или -);окончание-указатель типа.
Целая и дробная части записываются десятичными цифрами, а указатель типа (аналог указателя L или l для целочисленных литералов типа long) имеет два возможных значения – латинская ASCII-буква D (для типа double) или F (для типа float) в произвольном регистре. Они будут подробно рассмотрены ниже.
Необходимыми частями являются:
хотя бы одна цифра в целой или дробной части;десятичная точка или показатель степени, или указатель типа.
Все остальные части необязательные. Таким образом, "минимальные" дробные литералы могут быть записаны, например, так:
1. .1 1e1 1f
В Java есть два дробных типа, упомянутые выше, – float и double. Их длина – 4 и 8 байт или 32 и 64 бита, соответственно. Дробный литерал имеет тип float, если он заканчивается на латинскую букву F в произвольном регистре. В противном случае он рассматривается как значение типа double и может включать в себя окончание D или d, как признак типа double (используется только для наглядности).
// float-литералы: 1f, 3.14F, 0f, 1e+5F // double-литералы: 0., 3.14d, 1e-4, 31.34E45D
В Java дробные числа 32-битного типа float и 64-битного типа double хранятся в памяти в бинарном виде в формате, стандартизированном спецификацией IEEE 754 (полное название – IEEE Standard for Binary Floating-Point Arithmetic, ANSI/IEEE Standard 754-1985 (IEEE, New York)). В этой спецификации описаны не только конечные дробные величины, но и еще несколько особых значений, а именно:
положительная и отрицательная бесконечности (positive/negative infinity);значение "не число", Not-a-Number, сокращенно NaN;положительный и отрицательный нули.
Для этих значений нет специальных обозначений. Чтобы получить такие величины, необходимо либо произвести арифметическую операцию (например, результатом деления ноль на ноль 0.0/0.0 является NaN), либо обратиться к константам в классах Float и Double, а именно POSITIVE_INFINITY, NEGATIVE_INFINITY и NaN. Более подробно работа с этими особенными значениями рассматривается в следующей лекции.
Типы данных накладывают ограничения на возможные значения литералов, как и для целочисленных типов. Максимальное положительное конечное значение дробного литерала:
для float: 3.40282347e+38fдля double: 1.79769313486231570e+308
Кроме того, для дробных величин становится важным еще одно предельное значение – минимальное положительное ненулевое значение:
для float: 1.40239846e-45fдля double: 4.94065645841246544e-324
Попытка указать литерал со слишком большим абсолютным значением (например, 1e40F) приведет к ошибке компиляции. Такая величина должна представляться бесконечностью. Аналогично, указание литерала со слишком малым ненулевым значением (например, 1e-350) также приводит к ошибке. Это значение должно быть округлено до нуля. Однако если округление приводит не к нулю, то компилятор произведет его сам:
// ошибка, выражение должно быть округлено до 0 0.00000000000000000000000000000000000000000001f // ошибки нет, компилятор сам округляет до 1 1.00000000000000000000000000000000000000000001f
Стандартных возможностей вводить дробные значения не в десятичной системе в Java нет, однако классы Float и Double предоставляют много вспомогательных методов, в том числе и для такой задачи.
Идентификаторы
Идентификаторы – это имена, которые даются различным элементам языка для упрощения доступа к ним. Имена имеют пакеты, классы, интерфейсы, поля, методы, аргументы и локальные переменные (все эти понятия подробно рассматриваются в следующих лекциях). Идентификаторы можно записывать символами Unicode, то есть на любом удобном языке. Длина имени не ограничена.
Идентификатор состоит из букв и цифр. Имя не может начинаться с цифры. Java-буквы, используемые в идентификаторах, включают в себя ASCII-символы A-Z (\u0041-\u005a), a-z (\u0061-\u007a), а также знаки подчеркивания _ (ASCII underscore, \u005f) и доллара $ (\u0024). Знак доллара используется только при автоматической генерации кода (чтобы исключить случайное совпадение имен), либо при использовании каких-либо старых библиотек, в которых допускались имена с этим символом. Java-цифры включают в себя обычные ASCII-цифры 0-9 (\u0030-\u0039).
Для идентификаторов не допускаются совпадения с зарезервированными словами (это ключевые слова, булевские литералы true и false и null-литерал null). Конечно, если 2 идентификатора включают в себя разные буквы, которые одинаково выглядят (например, латинская и русская буквы A), то они считаются различными.
В этой лекции уже применялись следующие идентификаторы:
Character, a, b, c, D, x1, x2, Math, sqrt, x, y, i, s, PI, getRadius, circle, getAbs, calculate, condition, getWidth, getHeight, java, lang, String
Также допустимыми являются идентификаторы:
Computer, COLOR_RED, _, aVeryLongNameOfTheMethod
Иерархия классов
Заглянем в документацию. Выберите из меню Help главного окна приложения Java WorkShop строку Java API Documentation. На экране появится окно браузера, встроенного в Java WorkShop. С помощью этого браузера вы сможете просматривать содержимое справочной системы.
В разделе Java API Packages выберите библиотеку классов java.applet, а затем в разделе Class Index - строку Applet. Вы увидите иерархию классов:
java.lang.Object | +---java.awt.Component | +---java.awt.Container | +---java.awt.Panel | +---java.applet.Applet
Из этой иерархии видно, что класс java.applet.Applet произошел от класса java.awt.Panel. Этот класс, в свою очередь, определен в библиотеке классов java.awt и произошел от класса java.awt.Container.
Продолжим наши исследования. В классе java.awt.Container снова нет метода paint, но сам этот класс создан на базе класса java.awt.Component.
Но и здесь метода paint нет. Этот метод определен в классе java.awt.Component, который, в свою очередь, произошел от класса java.lang.Object и реализует интерфейс java.awt.image.ImageObserver.
Таким образом мы проследили иерархию классов от класса java.applet.Applet, на базе которого создан наш аплет, до класса java.lang.Object, который является базовым для всех классов в Java.
Метод paint определен в классе java.awt.Component, но так как этот класс является базовым для класса Applet и для нашего класса HelloApplet, мы можем переопределить метод paint.
Исходный текст аплета
Назад Вперед
Полный исходный текст аплета, созданный автоматически мастером проектов Java WorkShop, мы представили в листинге 1.
Листинг 1. Файл HelloApplet.java
import java.applet.Applet; public class HelloApplet extends Applet { /** * Initializes the applet. You never need to * call this directly; it is * called automatically by the system once the * applet is created. */ public void init() {}
/** * Called to start the applet. You never need * to call this directly; it * is called when the applet's * document is visited. */ public void start() {}
/** * Called to stop the applet. This is called * when the applet's document is * no longer on the screen. It is guaranteed * to be called before destroy() * is called. You never need to * call this method directly */ public void stop() {}
/** * Cleans up whatever resources are being held. * If the applet is active * it is stopped. */ public void destroy() {} }
Из-за обилия комментариев вы можете подумать, что исходный текст аплета, который ничего не делает, слишком сложный. Однако это вовсе не так. Вот что получится, если мы уберем все комментарии:
import java.applet.Applet; public class HelloApplet extends Applet { public void init() {} public void start() {} public void stop() {} public void destroy() {} }
Исходный текст нашего аплета начинается со строки, подключающей оператором import библиотеку классов java.applet.Applet.
Оператор import должен располагаться в файле исходного текста перед другими операторами (за исключением операторов комментария). В качестве параметра оператору import передается имя подключаемого класса из библиотеки классов. Если же необходимо подключить все классы данной библиотеки, вместо имени класса указывается символ "*".
Напомним, что библиотека java.applet.Applet содержит классы, необходимые для создания аплетов, то есть разновидности приложений Java, встраиваемых в документы HTML и работающих под управлением браузера Internet.
Еще одна библиотека классов, которая нам скоро понадобится, это java.awt. С ее помощью аплет может выполнять в своем окне рисование различных изображений или текста. Преимущества данного метода перед использованием для рисования традиционного программного интерфейса операционной системы заключаются в том, что он работает на любой компьютерной платформе.
Далее в исходном тексте аплета определяется класс типа public с именем HelloApplet. Напомним, что это имя должно обязательно совпадать с именем файла, содержащего исходный текст этого класса.
public class HelloApplet extends Applet { . . . }
Определенный нами класс HelloApplet с помощью ключевого слова extends наследуется от класса Applet. При этом методам класса HelloApplet становятся доступными все методы и данные класса, за исключением определенных как private. Класс Applet определен в библиотеке классов java.applet.Applet, которую мы подключили оператором import.
Назад Вперед

О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Исходный текст документа HTML
Назад Вперед
Кроме файла исходного текста аплета мастер проектов создал файл документа HTML HelloApplet.tmp.html, представленный в листинге 2.
Листинг 2. Файл HelloApplet.tmp.html
<applet name="HelloApplet" code="HelloApplet" codebase="file:/e:/sun/vol3/src/HelloApplet" width="500" height="600" align="Top" alt="If you had a java-enabled browser, you would see an applet here."> </applet>
С помощью оператора <applet> наш аплет встраивается в этот документ. Оператор <APPLET> используется в паре с оператором </APPLET> и имеет следующие параметры:
| Параметр | Описание | |
| ALIGN | Выравнивание окна аплета относительно окружающего его текста. Возможны следующие значения:
LEFT - выравнивание влево относительно окружающего текста; CENTER - центрирование; RIGHT - выравнивание вправо относительно окружающего текста; TOP - выравнивание по верхней границе; MIDDLE - центрирование по вертикали; BOTTOM - выравнивание по нижней границе | |
| ALT | С помощью этого параметра можно задать текст, который будет отображаться в окне аплета в том случае, если браузер не может работать с аплетами Java | |
| CODE | Имя двоичного файла, содержащего байт-код аплета. По умолчанию путь к этому файлу указывается относительно каталога с файлом HTML, в который встроен аплет. Такое поведение может быть изменено параметром CODEBASE | |
| CODEBASE | Базовый адрес URL аплета, то есть путь к каталогу, содержащему аплет | |
| HEIGHT | Ширина окна аплета в пикселах | |
| WIDTH | Высота окна аплета в пикселах | |
| HSPACE | Зазор слева и справа от окна аплета | |
| VSPACE | Зазор сверху и снизу от окна аплета | |
| NAME | Идентификатор аплета, который может быть использован другими аплетами, расположенными в одном и том же документе HTML, а также сценариями JavaScript | |
| TITLE | Строка заголовка |
Дополнительно между операторами <APPLET> и </APPLET> вы можете задать параметры аплета. Для этого используется оператор <PARAM>, который мы рассмотрим позже.
Изменяем исходный текст аплета
Назад Вперед
Теперь давайте попробуем немного изменить исходный текст аплета, чтобы заставить его рисовать в своем окне текстовую строку "Hello, Java world".
Вначале измените исходный текст так, как это показано на рис. 6.
 |
Рис. 6. Измененный исходный текст аплета HelloApplet
Для того чтобы увидеть рисунок в увеличенном виде, сделайте щелчок мышью по изображению |
Здесь мы намеренно внесли в исходный текст ошибку, чтобы показать, как Java WorkShop отреагирует на нее. Как видно из рисунка, сообщение об ошибке отображается на странице блокнота с названием Build. Текст сообщения гласит, что компилятор не смог найти определение класса Graphics, на который есть ссылка в девятой строке.
Добавим строку импортирования класса java.awt.*, как это показано в листинге 3.
Листинг 3. Файл HelloApplet.java (новый вариант)
import java.applet.Applet; import java.awt.*;
public class HelloApplet extends Applet { public String getAppletInfo() { return "HelloJava Applet"; } public void paint(Graphics g) { g.drawString("Hello, Java world!", 20, 20); } }
Теперь исходный текст аплета транслируется без ошибок (рис. 7).
 |
Рис. 7. Измененный исходный текст успешно оттранслирован
Для того чтобы увидеть рисунок в увеличенном виде, сделайте щелчок мышью по изображению |
Если запустить аплет на выполнение, в его окне будет нарисована строка "Hello, Java world" (рис. 8).

Рис. 8. Теперь наш аплет "умеет" рисовать в своем окне текстовые строки
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Ключевые слова
Ключевые слова – это зарезервированные слова, состоящие из ASCII-символов и выполняющие различные задачи языка. Вот их полный список (48 слов):
abstract double int strictfp boolean else interface super break extends long switch byte final native synchronized case finally new this catch float package throw char for private throws class goto protected transient const if public try continue implements return void default import short volatile do instanceof static while
Ключевые слова goto и const зарезервированы, но не используются. Это сделано для того, чтобы компилятор мог правильно отреагировать на их использование в других языках. Напротив, оба булевских литерала true, false и null-литерал null часто считают ключевыми словами (возможно, потому, что многие средства разработки подсвечивают их таким же образом), однако это именно литералы.
Значение всех ключевых слов будет рассматриваться в следующих лекциях.
Кодировка
Технология Java, как платформа, изначально спроектированная для Глобальной сети Internet, должна быть многоязыковой, а значит, обычный набор символов ASCII (American Standard Code for Information Interchange, Американский стандартный код обмена информацией), включающий в себя лишь латинский алфавит, цифры и простейшие специальные знаки (скобки, знаки препинания, арифметические операции и т.д.), недостаточен. Поэтому для записи текста программы применяется более универсальная кодировка Unicode.
Как известно, Unicode представляет символы кодом из 2 байт, описывая, таким образом, 65535 символов. Это позволяет поддерживать практически все распространенные языки мира. Первые 128 символов совпадают с набором ASCII. Однако понятно, что требуется некоторое специальное обозначение, чтобы иметь возможность задавать в программе любой символ Unicode, ведь никакая клавиатура не позволяет вводить более 65 тысяч различных знаков. Эта конструкция представляет символ Unicode, используя только символы ASCII. Например, если в программу нужно вставить знак с кодом 6917, необходимо его представить в шестнадцатеричном формате (1B05) и записать:
\u1B05,
причем буква u должна быть строчной, а шестнадцатеричные цифры A, B, C, D, E, F можно использовать произвольно, как заглавные, так и строчные. Таким образом можно закодировать все символы Unicode от \u0000 до \uFFFF. Буквы русского алфавита начинаются с \u0410 (только буква Ё имеет код \u0401) по \u044F (код буквы ё \u0451). В последних версиях JDK в состав демонстрационных приложений и апплетов входит небольшая программа SymbolTest, позволяющая просматривать весь набор символов Unicode. Ее аналог несложно написать самостоятельно. Для перекодирования больших текстов служит утилита native2ascii, также входящая в JDK. Она может работать как в прямом режиме — переводить из разнообразных кодировок в Unicode, записанный ASCII-символами, так и в обратном (опция -reverse) — из Unicode в стандартную кодировку операционной системы.
В версиях языка Java до 1.1 применялся Unicode версии 1.1.5, в последнем выпуске 1.4 используется 3.0. Таким образом, Java следит за развитием стандарта и базируется на современных версиях. Для любой JDK точную версию Unicode, используемую в ней, можно узнать из документации к классу Character. Официальный web-сайт стандарта, где можно получить дополнительную информацию,— http://www.unicode.org/.
Итак, используя простейшую кодировку ASCII, можно ввести произвольную последовательность символов Unicode. Далее будет показано, что Unicode используется не для всех лексем, а только для тех, для которых важна поддержка многих языков, а именно: комментарии, идентификаторы, символьные и строковые литералы. Для записи остальных лексем вполне достаточно ASCII-символов.
Комментарии не
Комментарии не влияют на результирующий бинарный код и используются только для ввода пояснений к программе.
В Java комментарии бывают двух видов:
строчныеблочные
Строчные комментарии начинаются с ASCII-символов // и длятся до конца текущей строки. Как правило, они используются для пояснения именно этой строки, например:
int y=1970; // год рождения
Блочные комментарии располагаются между ASCII-символами /* и */, могут занимать произвольное количество строк, например:
/* Этот цикл не может начинаться с нуля из-за особенностей алгоритма */ for (int i=1; i<10; i++) { ... }
Часто блочные комментарии оформляют следующим образом (каждая строка начинается с *):
/* * Описание алгоритма работы * следующего цикла while */ while (x > 0) { ... }
Блочный комментарий не обязательно должен располагаться на нескольких строках, он может даже находиться в середине оператора:
float s = 2*Math.PI/*getRadius()*/; // Закомментировано для отладки
В этом примере блочный комментарий разбивает арифметические операции. Выражение Math.PI предоставляет значение константы PI, определенное в классе Math. Вызов метода getRadius() теперь закомментирован и не будет произведен, переменная s всегда будет принимать значение 2 PI. Завершает строку строчный комментарий.
Комментарии не могут находиться в символьных и строковых литералах, идентификаторах (эти понятия подробно рассматриваются далее в этой лекции). Следующий пример содержит случаи неправильного применения комментариев:
// В этом примере текст /*…*/ станет просто // частью строки s String s = "text/*just text*/"; /* Следующая строка станет причиной ошибки при компиляции, так как комментарий разбил имя метода getRadius() */ circle.get/*comment*/Radius();
А такой код допустим:
// Комментарий может разделять вызовы функций: cirle./*comment*/getRadius();
// Комментарий может заменять пробелы: int/*comment*/x=1;
В последней строке между названием типа данных int и названием переменной x обязательно должен быть пробел или, как в данном примере, комментарий.
Комментарии не могут быть вложенными. Символы /*, */, // не имеют никакого особенного значения внутри уже открытых комментариев, как строчных, так и блочных. Таким образом, в примере
/* начало комментария /* // /** завершение: */
описан только один блочный комментарий. А в следующем примере (строки кода пронумерованы для удобства)
1. /* 2. comment 3. /* 4. more comments 5. */ 6. finish 7. */
компилятор выдаст ошибку. Блочный комментарий начался в строке 1 с комбинации символов /*. Вторая открывающая комбинация /* на строке 3 будет проигнорирована, так как находится уже внутри комментария. Символы */ в строке 5 завершат его, а строка 7 породит ошибку – попытка закрыть комментарий, который не был начат.
Любые комментарии полностью удаляются из программы во время компиляции, поэтому их можно использовать неограниченно, не опасаясь, что это повлияет на бинарный код. Основное их предназначение - сделать программу простой для понимания, в том числе и для других разработчиков, которым придется в ней разбираться по какой-либо причине. Также комментарии зачастую используются для временного исключения частей кода, например:
int x = 2; int y = 0; /* if (x > 0) y = y + x*2; else y = -y - x*4; */ y = y*y;// + 2*x;
В этом примере закомментировано выражение if-else и оператор сложения +2*x.
Как уже говорилось выше, комментарии можно писать символами Unicode, то есть на любом языке, удобном разработчику.
Кроме этого, существует особый вид блочного комментария – комментарий разработчика. Он применяется для автоматического создания документации кода. В стандартную поставку JDK, начиная с версии 1.0, входит специальная утилита javadoc. На вход ей подается исходный код классов, а на выходе получается удобная документация в HTML-формате, которая описывает все классы, все их поля и методы. При этом активно используются гиперссылки, что существенно упрощает изучение программы (например, читая описание метода, можно с помощью одного нажатия мыши перейти на описание типов, используемых в качестве аргументов или возвращаемого значения). Однако понятно, что одного названия метода и перечисления его аргументов недостаточно для понимания его работы. Необходимы дополнительные пояснения от разработчика.
Комментарий разработчика записывается так же, как и блочный. Единственное различие в начальной комбинации символов – для документации комментарий необходимо начинать с /**. Например:
/** * Вычисление модуля целого числа. * Этот метод возвращает * абсолютное значение аргумента x. */ int getAbs(int x) { if (x>=0) return x; else return -x; }
Первое предложение должно содержать краткое резюме всего комментария. В дальнейшем оно будет использовано как пояснение этой функции в списке всех методов класса (ниже будут описаны все конструкции языка, для которых применяется комментарий разработчика).
Поскольку в результате создается HTML-документация, то и комментарий необходимо писать по правилам HTML. Допускается применение тегов, таких как <b> и <p> . Однако теги заголовков с <h1> по <h6> и <hr> использовать нельзя, так как они активно применяются javadoc для создания структуры документации.
Символ * в начале каждой строки и предшествующие ему пробелы и знаки табуляции игнорируются. Их можно не использовать вообще, но они удобны, когда необходимо форматирование, скажем, в примерах кода.
/** * Первое предложение - краткое * описание метода. * <p> * Так оформляется пример кода: * <blockquote> * <pre> * if (condition==true) { * x = getWidht(); * y = x.getHeight(); * } * </pre></blockquote> * А так описывается HTML-список: * <ul> * <li>Можно использовать наклонный шрифт * <i>курсив</i>, * <li>или жирный <b>жирный</b>. * </ul> */ public void calculate (int x, int y) { ... }
Из этого комментария будет сгенерирован HTML-код, выглядящий примерно так:
Первое предложение – краткое описание метода.
Так оформляется пример кода:
if (condition==true) { x = getWidht(); y = x.getHeight(); }
А так описывается HTML-список:
• Можно использовать наклонный шрифт курсив, • или жирный жирный.
Наконец, javadoc поддерживает специальные теги. Они начинаются с символа @. Подробное описание этих тегов можно найти в документации. Например, можно использовать тег @see, чтобы сослаться на другой класс, поле или метод, или даже на другой Internet-сайт.
/** * Краткое описание. * * Развернутый комментарий. * * @see java.lang.String * @see java.lang.Math#PI * @see <a href="java.sun.com">Official * Java site</a> */
Первая ссылка указывает на класс String (java.lang – название библиотеки, в которой находится этот класс), вторая – на поле PI класса Math (символ # разделяет название класса и его полей или методов), третья ссылается на официальный сайт Java.
Комментарии разработчика могут быть записаны перед объявлением классов, интерфейсов, полей, методов и конструкторов. Если записать комментарий /** … */ в другой части кода, то ошибки не будет, но он не попадет в документацию, генерируемую javadoc. Кроме того, можно описать пакет (так называются библиотеки, или модули, в Java). Для этого необходимо создать специальный файл package.html, сохранить в нем комментарий и поместить его в каталог пакета. HTML-текст, содержащийся между тегами <body> и </body>, будет помещен в документацию, а первое предложение будет использоваться для краткой характеристики этого пакета.
Лексемы
Итак, мы рассмотрели пробелы (в широком смысле этого слова, т.е. все символы, отвечающие за форматирование текста программы) и комментарии, применяемые для ввода пояснений к коду. С точки зрения программиста они применяются для того, чтобы сделать программу более читаемой и понятной для дальнейшего развития.
С точки зрения компилятора, а точнее его части, отвечающей за лексический разбор, основная роль пробелов и комментариев – служить разделителями между лексемами, причем сами разделители далее отбрасываются и на компилированный код не влияют. Например, все следующие примеры объявления переменной эквивалентны:
// Используем пробел в качестве разделителя. int x = 3 ;
// здесь разделителем является перевод строки int x = 3 ;
// здесь разделяем знаком табуляции int x = 3 ;
/* * Единственный принципиально необходимый * разделитель между названием типа данных * int и именем переменной x здесь описан * комментарием блочного типа. */ int/**/x=3;
Конечно, лексемы очень разнообразны, и именно они определяют многие свойства языка. Рассмотрим все их виды более подробно.
Литералы
Литералы позволяют задать в программе значения для числовых, символьных и строковых выражений, а также null-литералов. Всего в Java определены следующие виды литералов:
целочисленный (integer); дробный (floating-point);булевский (boolean);символьный (character);строковый (string);null-литерал (null-literal).
Рассмотрим их по отдельности.
Логические литералы
Логические литералы имеют два возможных значения – true и false. Эти два зарезервированных слова не являются ключевыми, но также не могут использоваться в качестве идентификатора.
Логические операторы
Логические операторы "и" и "или" (& и |) можно использовать в двух вариантах. Это связано с тем, что, как легко убедиться, для каждого оператора возможны случаи, когда значение первого операнда сразу определяет значение всего логического выражения. Если вторым операндом является значение некоторой функции, то появляется выбор – вызывать ее или нет, причем это решение может сказаться как на скорости, так и на функциональности программы.
Первый вариант операторов (&, |) всегда вычисляет оба операнда, второй же – ( &&, || ) не будет продолжать вычисления, если значение выражения уже очевидно. Например:
int x=1; (x>0) | calculate(x) // в таком выражении // произойдет вызов // calculate (x>0) || calculate(x) // а в этом - нет
Логический оператор отрицания "не" записывается как ! и, конечно, имеет только один вариант использования. Этот оператор меняет булевское значение на противоположное.
int x=1; x>0 // выражение истинно !(x>0) // выражение ложно
Оператор с условием ? : состоит из трех частей – условия и двух выражений. Сначала вычисляется условие (булевское выражение), а на основании результата значение всего оператора определяется первым выражением в случае получения истины и вторым – если условие ложно. Например, так можно вычислить модуль числа x:
x>0 ? x : -x
Метод destroy
Перед удалением аплета из памяти вызывается метод destroy, который определен в базовом классе Applet как пустая заглушка. Мастер проектов добавляет в исходный текст класса переопределение метода destroy, которое вы можете при необходимости изменить.
Методу destroy обычно поручают все необходимые операции, которые следует выполнить перед удалением аплета. Например, если в методе init вы создавали какие-либо потоки, в методе destroy их нужно завершить.
Метод getAppletInfo
Назад Вперед
Базовый класс Applet содержит определение метода getAppletInfo, возвращающее значение null. В нашем классе HelloApplet, который является дочерним по отношению к классу Applet, мы переопределили метод getAppletInfo из базового класса следующим образом:
public String getAppletInfo() { return "HelloJava Applet"; }
Теперь метод getAppletInfo возвращает текстовую информацию об аплете в виде объекта класса String.
Этой информацией могут воспользоваться другие аплеты или сценарии JavaScript, например, для определения возможности взаимодействия с аплетом.
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Метод init
Метод init определен в базовом классе Applet, от которого наследуются все аплеты. Определение его таково, что этот метод ровным счетом ничего не делает.
Когда вызывается метод init и зачем он нужен?
Метод init вызывается тогда, когда браузер загружает в свое окно документ HTML с оператором <APPLET>, ссылающимся на данный аплет. В этот момент аплет может выполнять инициализацию, или, например, создавать потоки, если он работает в многопоточном режиме.
Существует контрпара для метода init - метод destroy. О нем мы расскажем ниже.
Метод paint
Назад Вперед
Наиболее интересен для нас метод paint, который выполняет рисование в окне аплета. Вот его исходный текст:
public void paint(Graphics g) { g.drawString("Hello, Java world!", 20, 20); }
Если посмотреть определение класса Applet, которое находится в файле JavaWorkshop20\JDK\src\java\applet\Applet.java, то в нем нет метода paint. В каком же классе определен этот метод?
Метод start
Метод start вызывается после метода init в момент, когда пользователь начинает просматривать документ HTML с встроенным в него аплетом.
Вы можете модифицировать текст этого метода, если при каждом посещении пользователем страницы с аплетом необходимо выполнять какую-либо инициализацию.
Метод stop
Дополнением к методу start служит метод stop. Он получает управление, когда пользователь покидает страницу с аплетом и загружает в окно браузера другую страницу. Заметим, что метод stop вызывается перед методом destroy.
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Методы в классе HelloApplet
Назад Вперед
Создавая файл HelloApplet.java, мастер проектов системы Java WorkShop определила в классе HelloApplet несколько методов, заменив таким образом некоторые методы базового класса Applet.
Null-литерал
Null-литерал может принимать всего одно значение: null. Это литерал ссылочного типа, причем эта ссылка никуда не ссылается, объект отсутствует. Разумеется, его можно применять к ссылкам любого объектного типа данных. Типы данных подробно рассматриваются в следующей лекции.
Операторы
Операторы используются в различных операциях – арифметических, логических, битовых, операциях сравнения и присваивания. Следующие 37 лексем (все состоят только из ASCII-символов) являются операторами языка Java:
= > < ! ~ ? : == <= >= != && || ++ -- + - * / & | ^ % << >> >>> += -= *= /= &= |= ^= %= <<= >>= >>>=
Большинство из них вполне очевидны и хорошо известны из других языков программирования, однако некоторые нюансы в работе с операторами в Java все же присутствуют, поэтому в конце лекции приводятся краткие комментарии к ним.
Операторы присваивания и сравнения
Во-первых, конечно же, различаются оператор присваивания = и оператор сравнения ==.
x = 1; // присваиваем переменной x значение 1 x == 1 // сравниваем значение переменной x с // единицей
Оператор сравнения всегда возвращает булевское значение true или false. Оператор присваивания возвращает значение правого операнда. Поэтому обычная опечатка в языке С, когда эти операторы путают:
// пример вызовет ошибку компилятора if (x=0) { // здесь должен применяться оператор // сравнения == ... }
в Java легко устраняется. Поскольку выражение x=0 имеет числовое значение 0, а не булевское (и тем более не воспринимается как всегда истинное), то компилятор сообщает об ошибке (необходимо писать x==0).
Условие "не равно" записывается как !=. Например:
if (x!=0) { float f = 1./x; }
Сочетание какого-либо оператора с оператором присваивания = (см. нижнюю строку в полном перечне в разделе "Операторы") используется при изменении значения переменной. Например, следующие две строки эквивалентны:
x = x + 1; x += 1;
Первый аплет Java
Назад Вперед
В предыдущем разделе мы создавали автономное приложение Java, работающее под управлением виртуальной машины Java. Теперь мы создадим приложение другого типа - аплет.
Аплет Java тоже выполняется под управлением виртуальной машины Java, но встроенной в браузер. Когда браузер загружает в свое окно документ HTML с аплетом, байт-код аплета начинает свою работу.
Внешне аплет выглядит как окно заданного размера. Он может рисовать внутри этого окна (и только в нем) произвольные изображения и текст.
Двоичный файл с интерпретируемым байт-кодом Java располагается на сервере Web. В документе HTML с помощью оператора <APPLET> организуется ссылка на этот двоичный файл.
Когда пользователь загружает в браузер документ HTML с аплетом, файл аплета переписывается с сервера Web на рабочую станцию пользователя. После этого браузер начинает его выполнение.
Возможно, вам не понравится такая идея, как запуск чужого аплета на своем компьютере - мало ли чего этот аплет может там сделать. Однако аплеты, в отличие от обычных приложений Java, сильно ограничены в своих правах. Например, они не могут читать локальные файлы и тем более в них писать. Есть также ограничения и на передачу данных через сеть: аплет может обмениваться данными только с тем сервером Web, с которого он был загружен.
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Пример программы
В заключение для примера приведем простейшую программу (традиционное Hello, world!), а затем классифицируем и подсчитаем используемые лексемы:
public class Demo { /** * Основной метод, с которого начинается * выполнение любой Java программы. */ public static void main (String args[]) { System.out.println("Hello, world!"); } }
Итак, в приведенной программе есть один комментарий разработчика, 7 идентификаторов, 5 ключевых слов, 1 строковый литерал, 13 разделителей и ни одного оператора. Этот текст можно сохранить в файле Demo.java, скомпилировать и запустить (работа с JDK и стандартными утилитами была рассмотрена в первой лекции). Результатом работы будет, как очевидно:
Hello, world!
Пробелы
Пробелами в данном случае называют все символы, разбивающие текст программы на лексемы. Это как сам символ пробела (space, \u0020, десятичный код 32), так и знаки табуляции и перевода строки. Они используются для разделения лексем, а также для оформления кода, чтобы его было легче читать. Например, следующую часть программы (вычисление корней квадратного уравнения):
double a = 1, b = 1, c = 6; double D = b * b - 4 * a * c;
if (D >= 0) { double x1 = (-b + Math.sqrt (D)) / (2 * a); double x2 = (-b - Math.sqrt (D)) / (2 * a); }
можно записать и в таком виде:
double a=1,b=1,c=6;double D=b*b-4*a*c;if(D>=0) {double x1=(-b+Math.sqrt(D))/(2*a);double x2=(-b-Math.sqrt(D))/(2*a);}
В обоих случаях компилятор сгенерирует абсолютно одинаковый код. Единственное соображение, которым должен руководствоваться разработчик,— легкость чтения и дальнейшей поддержки такого кода.
Для разбиения текста на строки в ASCII используется два символа - "возврат каретки" (carriage return, CR, \u000d, десятичный код 13) и символ новой строки (linefeed, LF, \u000a, десятичный код 10). Чтобы не зависеть от особенностей используемой платформы, в Java применяется наиболее гибкий подход. Завершением строки считается:
ASCII-символ LF, символ новой строки;
ASCII-символ CR, "возврат каретки";символ CR, за которым сразу же следует символ LF.
Разбиение на строки важно для корректного разбиения на лексемы (как уже говорилось, завершение строки также служит разделителем между лексемами), для правильной работы со строковыми комментариями (см. следующую тему "Комментарии"), а также для вывода отладочной информации (при выводе ошибок компиляции и времени исполнения указывается, на какой строке исходного кода они возникли). Итак, пробелами в Java считаются:
ASCII-символ SP, space, пробел, \u0020, десятичный код 32;
ASCII-символ HT, horizontal tab, символ горизонтальной табуляции, \u0009, десятичный код 9;
ASCII-символ FF, form feed, символ перевода страницы (был введен для работы с принтером), \u000c, десятичный код 12;завершение строки.
Разделители
Разделители – это специальные символы, которые используются в служебных целях языка. Назначение каждого из них будет рассмотрено по ходу изложения курса. Вот их полный список:
( ) [ ] { } ; . ,
Символьные литералы
Символьные литералы описывают один символ из набора Unicode, заключенный в одиночные кавычки, или апострофы (ASCII-символ single quote, \u0027). Например:
'a' // латинская буква а ' ' // пробел 'K' // греческая буква каппа
Также допускается специальная запись для описания символа через его код (см. тему "Кодировка"). Примеры:
'\u0041' // латинская буква A '\u0410' // русская буква А '\u0391' // греческая буква A
Символьный литерал должен содержать строго один символ, или специальную последовательность, начинающуюся с \. Для записи специальных символов (неотображаемых и служебных, таких как ", ', \) используются следующие обозначения:
\b \u0008 backspace BS – забой \t \u0009 horizontal tab HT – табуляция \n \u000a linefeed LF – конец строки \f \u000c form feed FF – конец страницы \r \u000d carriage return CR – возврат каретки \" \u0022 double quote " – двойная кавычка \' \u0027 single quote ' – одинарная кавычка \\ \u005c backslash \ – обратная косая черта \шестнадцатеричный код от \u0000 до \u00ff символа в шестнадцатеричном формате.
Первая колонка описывает стандартные обозначения специальных символов, используемые в Java-программах. Вторая колонка представляет их в стандартном виде Unicode-символов. Третья колонка содержит английские и русские описания. Использование \ в комбинации с другими символами приведет к ошибке компиляции.
Поддержка ввода символов через восьмеричный код обеспечивается для совместимости с С. Например:
'\101' // Эквивалентно '\u0041'
Однако таким образом можно задать лишь символы от \u0000 до \u00ff (т.е. с кодом от 0 до 255), поэтому Unicode-последовательности предпочтительней.
Поскольку обработка Unicode-последовательностей (\uhhhh) производится раньше лексического анализа, то следующий пример является ошибкой:
'\u000a' // символ конца строки
Компилятор сначала преобразует \u000a в символ конца строки и кавычки окажутся на разных строках кода, что является ошибкой. Необходимо использовать специальную последовательность:
'\n' // правильное обозначение конца строки
Аналогично и для символа \u000d (возврат каретки) необходимо использовать обозначение \r.
Специальные символы можно использовать в составе как символьных, так и строковых литералов.
Создание проекта аплета
Назад Вперед
Проект аплета создается таким же способом, что и проект автономного приложения Java, однако мастеру проектов необходимо указать другие параметры.
В первой диалоговой панели мастера проектов следует включить переключатели Applet и No GUI (рис. 1).
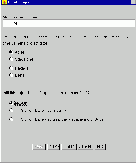 |
Рис. 1. Первая диалоговая панель мастера проектов
Для того чтобы увидеть рисунок в увеличенном виде, сделайте щелчок мышью по изображению |
Сделав это, нажмите кнопку Next. На экране появится вторая диалоговая панель мастера проектов. Здесь вы должны указать путь к каталогу, куда мастер проектов запишет файлы проекта, а также включить переключатель No (рис. 2).
 |
Рис. 2. Вторая диалоговая панель мастера проектов
Для того чтобы увидеть рисунок в увеличенном виде, сделайте щелчок мышью по изображению |
В результате мастер проектов создаст исходные тексты аплета, а также добавит новый проект в портфель personal (если этот портфель остался активным в последний раз, когда вы запускали Java WorkShop). Новый проект называется HelloApplet (рис. 3).

Рис. 3. Новый проект появился в активном портфеле personal
Исходный текст аплета будет создан автоматически и загружен в окно редактирования системы Java WorkShop (рис. 4).
 |
Рис. 4. Исходный текст аплета загружен в окно редактирования
Для того чтобы увидеть рисунок в увеличенном виде, сделайте щелчок мышью по изображению |
Вы можете оттранслировать полученный исходный текст и запустить аплет на выполнение. Он будет работать под управлением программы просмотра аплетов appletviewer, которая входит в состав Java WorkShop.
Пока в окне нашего аплета ничего нет (рис. 5), однако скоро мы исправим это положение.

Рис. 5. Окно аплета, созданного автоматически мастером проектов
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Строковые литералы
Строковые литералы состоят из набора символов и записываются в двойных кавычках. Длина может быть нулевой или сколь угодно большой. Любой символ может быть представлен специальной последовательностью, начинающейся с \ (см. "Символьные литералы").
"" // литерал нулевой длины "\"" //литерал, состоящий из одного символа " "Простой текст" //литерал длины 13
Строковый литерал нельзя разбивать на несколько строк в коде программы. Если требуется текстовое значение, состоящее из нескольких строк, то необходимо воспользоваться специальными символами \n и/или \r. Если же текст просто слишком длинный, чтобы уместиться на одной строке кода, можно использовать оператор конкатенации строк +. Примеры строковых литералов:
// выражение-константа, составленное из двух // литералов "Длинный текст " + "с переносом" /* * Строковый литерал, содержащий текст * из двух строк: * Hello, world! * Hello! */ "Hello, world!\r\nHello!"
На строковые литералы распространяются те же правила, что и на символьные в отношении использования символов новой строки \u000a и \u000d.
Каждый строковый литерал является экземпляром класса String. Это определяет некоторые необычные свойства строковых литералов, которые будут рассмотрены в следующей лекции.
Виды лексем
Ниже перечислены все виды лексем в Java:
идентификаторы (identifiers);ключевые слова (key words);
литералы (literals);разделители (separators);операторы (operators).
Рассмотрим их по отдельности.
Вызов метода paint
Метод paint вызывается, когда необходимо перерисовать окно аплета. Если вы создавали приложения для операционной системы Windows, то наверняка знакомы с сообщением WM_PAINT, которое поступает в функцию окна приложения при необходимости его перерисовки.
Перерисовка окна приложения Windows и окна аплета обычно выполняется асинхронно по отношению к работе приложения или аплета. В любой момент времени аплет должен быть готов перерисовать содержимое своего окна.
Такая техника отличается о той, к которой вы, возможно, привыкли, создавая обычные программы для MS-DOS. Программы MS-DOS сами определяют, когда им нужно рисовать на экране, причем рисование может выполняться из разных мест программы. Аплеты, так же как и приложения Windows, выполняют рисование в своих окнах централизованно. Аплет делает это в методе paint, а приложение Windows - при обработке сообщения WM_PAINT.
Обратите внимание, что методу paint в качестве параметра передается ссылка на объект Graphics:
public void paint(Graphics g) { . . . }
По своему смыслу этот объект напоминает контекст отображения, с которым хорошо знакомы создатели приложений Windows. Контекст отображения - это как бы холст, на котором аплет может рисовать изображение или писать текст. Многочисленные методы класса Graphics позволяют задавать различные параметры холста, такие, например, как цвет или шрифт.
Наше приложение вызывает метод drawString, который рисует текстовую строку в окне аплета:
g.drawString("Hello, Java world!", 20, 20);
Вот прототип этого метода:
public abstract void drawString(String str, int x, int y);
Через первый параметр методу drawString передается текстовая строка в виде объекта класса String. Второй и третий параметр определяют, соответственно, координаты точки, в которой начнется рисование строки.
В какой координатной системе?
Аплеты используют систему координат, которая соответствует режиму отображения MM_TEXT, знакомому тем, кто создавал приложения Windows. Начало этой системы координат расположено в левом верхнем углу окна аплета, ось X направлена слева направо, а ось Y - сверху вниз (рис. 9).
В этой лекции были рассмотрены
В этой лекции были рассмотрены основы лексического анализа программ Java. Для их записи применяется универсальная кодировка Unicode, позволяющая использовать любой язык помимо традиционного английского. Еще раз напомним, что использование Unicode возможно и необходимо в следующих конструкциях:
комментарии;
идентификаторы;символьные и строковые литералы.
Остальные же (пробелы, ключевые слова, числовые, булевские и null-литералы, разделители и операторы) легко записываются с применением лишь ASCII-символов. В то же время любой Unicode-символ также можно задать в виде специальной последовательности ASCII-символов.
Во время анализа компилятор выделяет из текста программы <пробелы> (были рассмотрены все символы, которые рассматриваются как пробелы) и комментарии, которые полностью удаляются из кода (были рассмотрены все виды комментариев, в частности комментарий разработчика). Пробелы и все виды комментариев служат для разбиения текста программы на лексемы. Были рассмотрены все виды лексем, в том числе все виды литералов.
В дополнении были рассмотрены особенности применения различных операторов.
Аплет Draw
Назад Вперед
В этом разделе мы приведем исходные тексты аплета Draw, в которых демонстрируется использование различных функций рисования.
На рис. 11 показано окно этого аплета.

Рис. 11. Окно аплета Draw
В верхней части окна мы вывели список вех шрифтов, доступных аплету, а также примеры оформления строки Test string с использованием этих шрифтов.
В нижней части окна нарисовано несколько геометрических фигур.
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Битовые маски стиля шрифта
BOLD
public final static int BOLD;
ITALIC
public final static int ITALIC;
PLAIN
public final static int PLAIN;
Булевский тип
Булевский тип представлен всего одним типом boolean, который может хранить всего два возможных значения – true и false. Величины именно этого типа получаются в результате операций сравнения.
Над булевскими аргументами можно производить следующие операции:
операции сравнения (возвращают булевское значение)
==, !=
логические операции (возвращают булевское значение)
!
&, |, ^
&&, ||
оператор с условием ? : оператор конкатенации со строкой +
Логические операторы && и || обсуждались в предыдущей лекции. В операторе с условием ? : первым аргументом может быть только значение типа boolean. Также допускается, чтобы второй и третий аргументы одновременно имели булевский тип.
Операция конкатенации со строкой превращает булевскую величину в текст "true" или "false" в зависимости от значения.
Только булевские выражения допускаются для управления потоком вычислений, например, в качестве критерия условного перехода if.
Никакое число не может быть интерпретировано как булевское выражение. Если предполагается, что ненулевое значение эквивалентно истине (по правилам языка С), то необходимо записать x!=0. Ссылочные величины можно преобразовывать в boolean выражением ref!=null.
Целочисленные типы
Целочисленные типы – это byte, short, int, long, также к ним относят и char. Первые четыре типа имеют длину 1, 2, 4 и 8 байт соответственно, длина char – 2 байта, это непосредственно следует из того, что все символы Java описываются стандартом Unicode. Длины типов приведены только для оценки областей значения. Как уже говорилось, память в Java представляется виртуальной и вычислить, сколько физических ресурсов займет та или иная переменная, так прямолинейно не получится.
4 основных типа являются знаковыми. char добавлен к целочисленным типам данных, так как с точки зрения JVM символ и его код – понятия взаимооднозначные. Конечно, код символа всегда положительный, поэтому char – единственный беззнаковый тип. Инициализировать его можно как символьным, так и целочисленным литералом. Во всем остальном char – полноценный числовой тип данных, который может участвовать, например, в арифметических действиях, операциях сравнения и т.п. В таблице 4.1 сведены данные по всем разобранным типам:
|
byte | 1 |
-128 .. 127 |
|
short | 2 |
-32.768 .. 32.767 |
|
int | 4 |
-2.147.483.648 .. 2.147.483.647 |
|
long | 8 |
-9.223.372.036.854.775.808 .. 9.223.372.036.854.775.807 (примерно 1019) |
|
char | 2 |
'\u0000' .. '\uffff', или 0 .. 65.535 |
Обратите внимание, что int вмещает примерно 2 миллиарда, а потому подходит во многих случаях, когда не требуются сверхбольшие числа. Чтобы представить себе размеры типа long, укажем, что именно он используется в Java для отсчета времени. Как и во многих языках, время отсчитывается от 1 января 1970 года в миллисекундах. Так вот, вместимость long позволяет отсчитывать время на протяжении миллионов веков(!), причем как в будущее, так и в прошлое.
Почему были выделены именно эти два типа, int и long? Дело в том, что целочисленные литералы имеют тип int по умолчанию, или тип long, если стоит буква L или l. Именно поэтому корректным литералом считается только такое число, которое укладывается в 4 или 8 байт, соответственно. Иначе компилятор сочтет это ошибкой. Таким образом, следующие литералы являются корректными:
1 -2147483648 2147483648L 0L 111111111111111111L
Над целочисленными аргументами можно производить следующие операции:
операции сравнения (возвращают булевское значение)
<, <=, >, >=
==, !=
числовые операции (возвращают числовое значение) унарные операции + и - арифметические операции +, -, *, /, % операции инкремента и декремента (в префиксной и постфиксной форме): ++ и -- операции битового сдвига <<, >>, >>> битовые операции ~, &, |, ^
оператор с условием ? : оператор приведения типовоператор конкатенации со строкой +
Операторы сравнения вполне очевидны и отдельно мы их рассматривать не будем. Их результат всегда булевского типа (true или false).
Работа числовых операторов также понятна, к тому же пояснялась в предыдущей лекции. Единственное уточнение можно сделать относительно операторов + и -, которые могут быть как бинарными (иметь два операнда), так и унарными (иметь один операнд). Бинарные операнды являются операторами сложения и вычитания, соответственно. Унарный оператор + возвращает значение, равное аргументу (+x всегда равно x). Унарный оператор -, примененный к значению x, возвращает результат, равный 0-x. Неожиданный эффект имеет место в том случае, если аргумент равен наименьшему возможному значению примитивного типа.
int x=-2147483648; // наименьшее возможное // значение типа int int y=-x;
Теперь значение переменной y на самом деле равно не 2147483648, поскольку такое число не укладывается в область значений типа int, а в точности равно значению x! Другими словами, в этом примере выражение -x==x истинно!
Дело в том, что если при выполнении числовых операций над целыми числами возникает переполнение и результат не может быть сохранен в данном примитивном типе, то Java не создает никаких ошибок. Вместо этого все старшие биты, которые превышают вместимость типа, просто отбрасываются. Это может привести не только к потере точной абсолютной величины результата, но даже к искажению его знака, если на месте знакового бита окажется противоположное значение.
int x= 300000; print(x*x);
Результатом такого примера будет:
-194313216
Возвращаясь к инвертированию числа -2147483648, мы видим, что математический результат равен в точности +231, или, в двоичном формате, 1000 0000 0000 0000 0000 0000 0000 0000 (единица и 31 ноль). Но тип int рассматривает первую единицу как знаковый бит, и результат получается равным -2147483648.
Таким образом, явное выписывание в коде литералов, которые слишком велики для используемых типов, приводит к ошибке компиляции (см. лекцию 3). Если же переполнение возникает в результате выполнения операции, "лишние" биты просто отбрасываются.
Подчеркнем, что выражение типа -5 не является целочисленным литералом. На самом деле оно состоит из литерала 5 и оператора -. Напомним, что некоторые литералы (например, 2147483648) могут встречаться только в сочетании с унарным оператором -.
Кроме того, числовые операции в Java обладают еще одной особенностью. Хотя целочисленные типы имеют длину 8, 16, 32 и 64 бита, вычисления проводятся только с 32-х и 64-х битной точностью. А это значит, что перед вычислениями может потребоваться преобразовать тип одного или нескольких операндов.
Если хотя бы один аргумент операции имеет тип long, то все аргументы приводятся к этому типу и результат операции также будет типа long. Вычисление будет произведено с точностью в 64 бита, а более старшие биты, если таковые появляются в результате, отбрасываются.
Если же аргументов типа long нет, то вычисление производится с точностью в 32 бита, и все аргументы преобразуются в int (это относится к byte, short, char). Результат также имеет тип int. Все биты старше 32-го игнорируются.
Никакого способа узнать, произошло ли переполнение, нет. Расширим рассмотренный пример:
int i=300000; print(i*i); // умножение с точностью 32 бита long m=i; print(m*m); // умножение с точностью 64 бита print(1/(m-i)); // попробуем получить разность // значений int и long
Результатом такого примера будет:
-194313216 90000000000
затем мы получим ошибку деления на ноль, поскольку переменные i и m хоть и разных типов, но хранят одинаковое математическое значение и их разность равна нулю. Первое умножение производилось с точностью в 32 бита, более старшие биты были отброшены. Второе – с точностью в 64 бита, ответ не исказился.
Вопрос приведения типов, и в том числе специальный оператор для такого действия, подробно рассматривается в следующих лекциях. Однако здесь хотелось бы отметить несколько примеров, которые не столь очевидны и могут создать проблемы при написании программ. Во-первых, подчеркнем, что результатом операции с целочисленными аргументами всегда является целое число. А значит, в следующем примере
double x = 1/2;
переменной x будет присвоено значение 0, а не 0.5, как можно было бы ожидать. Подробно операции с дробными аргументами рассматриваются ниже, но чтобы получить значение 0.5, достаточно написать 1./2 (теперь первый аргумент дробный и результат не будет округлен).
Как уже упоминалось, время в Java измеряется в миллисекундах. Попробуем вычислить, сколько миллисекунд содержится в неделе и в месяце:
print(1000*60*60*24*7); // вычисление для недели print(1000*60*60*24*30); // вычисление для месяца
Необходимо перемножить количество миллисекунд в одной секунде (1000), секунд – в минуте (60), минут – в часе (60), часов – в дне (24) и дней — в неделе и месяце (7 и 30, соответственно). Получаем:
604800000 -1702967296
Очевидно, во втором вычислении произошло переполнение. Достаточно сделать последний аргумент величиной типа long:
print(1000*60*60*24*30L); // вычисление для месяца
Получаем правильный результат:
2592000000
Подобные вычисления разумно переводить на 64-битную точность не на последней операции, а заранее, чтобы избежать переполнения.
Понятно, что типы большей длины могут хранить больший спектр значений, а потому Java не позволяет присвоить переменной меньшего типа значение большего типа. Например, такие строки вызовут ошибку компиляции:
// пример вызовет ошибку компиляции int x=1; byte b=x;
Хотя для программиста и очевидно, что переменная b должна получить значение 1, что легко укладывается в тип byte, однако компилятор не может вычислять значение переменной x при обработке второй строки, он знает лишь, что ее тип – int.
А вот менее очевидный пример:
// пример вызовет ошибку компиляции byte b=1; byte c=b+1;
И здесь компилятор не сможет успешно завершить работу. При операции сложения значение переменной b будет преобразовано в тип int и таким же будет результат сложения, а значит, его нельзя так просто присвоить переменной типа byte.
Аналогично:
// пример вызовет ошибку компиляции int x=2; long y=3; int z=x+y;
Здесь результат сложения будет уже типа long. Точно так же некорректна такая инициализация:
// пример вызовет ошибку компиляции byte b=5; byte c=-b;
Даже унарный оператор "-" проводит вычисления с точностью не меньше 32 бит.
Хотя во всех случаях инициализация переменных приводилась только для примера, а предметом рассмотрения были числовые операции, укажем корректный способ преобразовать тип числового значения:
byte b=1; byte c=(byte)-b;
Итак, все числовые операторы возвращают результат типа int или long. Однако существует два исключения.
Первое из них – операторы инкрементации и декрементации. Их действие заключается в прибавлении или вычитании единицы из значения переменной, после чего результат сохраняется в этой переменной и значение всей операции равно значению переменной (до или после изменения, в зависимости от того, является оператор префиксным или постфиксным). А значит, и тип значения совпадает с типом переменной. (На самом деле, вычисления все равно производятся с точностью минимум 32 бита, однако при присвоении переменной результата его тип понижается.)
byte x=5; byte y1=x++; // на момент начала исполнения x равен 5 byte y2=x--; // на момент начала исполнения x равен 6 byte y3=++x; // на момент начала исполнения x равен 5 byte y4=--x; // на момент начала исполнения x равен 6 print(y1); print(y2); print(y3); print(y4);
В результате получаем:
5 6 6 5
Никаких проблем с присвоением результата операторов ++ и -- переменным типа byte. Завершая рассмотрение этих операторов, приведем еще один пример:
byte x=-128; print(-x);
byte y=127; print(++y);
Результатом будет:
128 -128
Этот пример иллюстрирует вопросы преобразования типов при вычислениях и случаи переполнения.
Вторым исключением является оператор с условием ? :. Если второй и третий операнды имеют одинаковый тип, то и результат операции будет такого же типа.
byte x=2; byte y=3; byte z=(x>y) ? x : y; // верно, x и y одинакового типа byte abs=(x>0) ? x : -x; // неверно!
Последняя строка неверна, так как третий аргумент содержит числовую операцию, стало быть, его тип int, а значит, и тип всей операции будет int, и присвоение некорректно. Даже если второй аргумент имеет тип byte, а третий – short, значение будет типа int.
Наконец, рассмотрим оператор конкатенации со строкой. Оператор + может принимать в качестве аргумента строковые величины. Если одним из аргументов является строка, а вторым – целое число, то число будет преобразовано в текст и строки объединятся.
int x=1; print("x="+x);
Результатом будет:
x=1
Обратите внимание на следующий пример:
print(1+2+"text"); print("text"+1+2);
Его результатом будет:
3text text12
Отдельно рассмотрим работу с типом char. Значения этого типа могут полноценно участвовать в числовых операциях:
char c1=10; char c2='A'; // латинская буква A (\u0041, код 65) int i=c1+c2-'B';
Переменная i получит значение 9.
Рассмотрим следующий пример:
char c='A'; print(c); print(c+1); print("c="+c); print('c'+'='+с);
Его результатом будет:
A 66 c=A 225
В первом случае в метод print было передано значение типа char, поэтому отобразился символ. Во втором случае был передан результат сложения, то есть число, и именно число появилось на экране. Далее при сложении со строкой тип char был преобразован в текст в виде символа. Наконец в последней строке произошло сложение трех чисел: 'c' (код 99), '=' (код 61) и переменной c (т.е. код 'A' - 65).
Для каждого примитивного типа существуют специальные вспомогательные классы-обертки (wrapper classes). Для типов byte, short, int, long, char это Byte, Short, Integer, Long, Character. Эти классы содержат многие полезные методы для работы с целочисленными значениями. Например, преобразование из текста в число. Кроме того, есть класс Math, который хоть и предназначен в основном для работы с дробными числами, но также предоставляет некоторые возможности и для целых.
В заключение подчеркнем, что единственные операции с целыми числами, при которых Java генерирует ошибки,– это деление на ноль (операторы / и %).
Документ HTML для аплета Draw
Документ HTML для аплета Draw не имеет никаких особенностей. Он представлен в листинге 2.
Листинг 2. Файл draw.tmp.html
<applet name="draw" code="draw" codebase="file:/e:/Sun/Articles/vol4/src/draw" width="250" height="350" align="Top" alt="If you had a java-enabled browser, you would see an applet here." > <param name="TestString" value="Test string"> <hr>If your browser recognized the applet tag, you would see an applet here.<hr> </applet>
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Дробные типы
Дробные типы – это float и double. Их длина - 4 и 8 байт, соответственно. Оба типа знаковые. Ниже в таблице сведены их характеристики:
|
float | 4 |
3.40282347e+38f ; 1.40239846e-45f |
|
double | 8 |
1.79769313486231570e+308 ; 4.94065645841246544e-324 |
Для целочисленных типов область значений задавалась верхней и нижней границами, весьма близкими по модулю. Для дробных типов добавляется еще одно ограничение – насколько можно приблизиться к нулю, другими словами – каково наименьшее положительное ненулевое значение. Таким образом, нельзя задать литерал заведомо больший, чем позволяет соответствующий тип данных, это приведет к ошибке overflow. И нельзя задать литерал, значение которого по модулю слишком мало для данного типа, компилятор сгенерирует ошибку underflow.
// пример вызовет ошибку компиляции float f = 1e40f; // значение слишком велико, overflow double d = 1e-350; // значение слишком мало, underflow
Напомним, что если в конце литерала стоит буква F или f, то литерал рассматривается как значение типа float. По умолчанию дробный литерал имеет тип double, при желании это можно подчеркнуть буквой D или d.
Над дробными аргументами можно производить следующие операции:
операции сравнения (возвращают булевское значение)
<, <=, >, >=
==, !=
числовые операции (возвращают числовое значение) унарные операции + и - арифметические операции +, -, *, /, % операции инкремента и декремента (в префиксной и постфиксной форме): ++ и --
оператор с условием ? : оператор приведения типовоператор конкатенации со строкой +
Практически все операторы действуют по тем же принципам, которые предусмотрены для целочисленных операторов (оператор деления с остатком % рассматривался в предыдущей лекции, а операторы ++ и -- также увеличивают или уменьшают значение переменной на единицу). Уточним лишь, что операторы сравнения корректно работают и в случае сравнения целочисленных значений с дробными. Таким образом, в основном необходимо рассмотреть вопросы переполнения и преобразования типов при вычислениях.
Для дробных вычислений появляется уже два типа переполнения – overflow и underflow. Тем не менее, Java и здесь никак не сообщает о возникновении подобных ситуаций. Нет ни ошибок, ни других способов обнаружить их. Более того, даже деление на ноль не приводит к некорректной ситуации. А значит, дробные вычисления вообще не порождают никаких ошибок.
Такая свобода связана с наличием специальных значений дробного типа. Они определяются спецификацией IEEE 754 и уже перечислялись в лекции 3:
положительная и отрицательная бесконечности (positive/negative infinity);значение "не число", Not-a-Number, сокращенно NaN;положительный и отрицательный нули.
Все эти значения представлены как для типа float, так и для double.
Положительную и отрицательную бесконечности можно получить следующим образом:
1f/0f // положительная бесконечность, // тип float -1d/0d // отрицательная бесконечность, // тип double
Также в классах Float и Double определены константы POSITIVE_INFINITY и NEGATIVE_INFINITY. Как видно из примера, такие величины получаются при делении конечных величин на ноль.
Значение NaN можно получить, например, в результате следующих действий:
0.0/0.0 // деление ноль на ноль (1.0/0.0)*0.0 // умножение бесконечности на ноль
Эта величина также представлена константами NaN в классах Float и Double.
Величины положительный и отрицательный ноль записываются очевидным образом:
0.0 // дробный литерал со значением // положительного нуля +0.0 // унарная операция +, ее значение - // положительный ноль -0.0 // унарная операция -, ее значение - // отрицательный ноль
Все дробные значения строго упорядочены. Отрицательная бесконечность меньше любого другого дробного значения, положительная – больше. Значения +0.0 и -0.0 считаются равными, то есть выражение 0.0==-0.0 истинно, а 0.0>-0.0 – ложно. Однако другие операторы различают их, например, выражение 1.0/0.0 дает положительную бесконечность, а 1.0/-0.0 – отрицательную.
Единственное исключение - значение NaN. Если хотя бы один из аргументов операции сравнения равняется NaN, то результат заведомо будет false (для оператора != соответственно всегда true). Таким образом, единственное значение x, при котором выражение x!=x истинно,– именно NaN.
Возвращаемся к вопросу переполнения в числовых операциях. Если получаемое значение слишком велико по модулю (overflow), то результатом будет бесконечность соответствующего знака.
print(1e20f*1e20f); print(-1e200*1e200);
В результате получаем:
Infinity -Infinity
Если результат, напротив, получается слишком мал (underflow), то он просто округляется до нуля. Так же поступают и в том случае, когда количество десятичных знаков превышает допустимое:
print(1e-40f/1e10f); // underflow для float print(-1e-300/1e100); // underflow для double float f=1e-6f; print(f); f+=0.002f; print(f); f+=3; print(f); f+=4000; print(f);
Результатом будет:
0.0 -0.0
1.0E-6 0.002001 3.002001 4003.002
Как видно, в последней строке был утрачен 6-й разряд после десятичной точки.
Другой пример (из спецификации языка Java):
double d = 1e-305 * Math.PI; print(d); for (int i = 0; i < 4; i++) print(d /= 100000);
Результатом будет:
3.141592653589793E-305 3.1415926535898E-310 3.141592653E-315 3.142E-320 0.0
Таким образом, как и для целочисленных значений, явное выписывание в коде литералов, которые слишком велики (overflow) или слишком малы (underflow) для используемых типов, приводит к ошибке компиляции (см. лекцию 3). Если же переполнение возникает в результате выполнения операции, то возвращается одно из специальных значений.
Теперь перейдем к преобразованию типов. Если хотя бы один аргумент имеет тип double, то значения всех аргументов приводятся к этому типу и результат операции также будет иметь тип double. Вычисление будет произведено с точностью в 64 бита.
Если же аргументов типа double нет, а хотя бы один аргумент имеет тип float, то все аргументы приводятся к float, вычисление производится с точностью в 32 бита и результат имеет тип float.
Эти утверждения верны и в случае, если один из аргументов целочисленный. Если хотя бы один из аргументов имеет значение NaN, то и результатом операции будет NaN.
Еще раз рассмотрим простой пример:
print(1/2); print(1/2.);
Результатом будет:
0 0.5
Достаточно одного дробного аргумента, чтобы результат операции также имел дробный тип.
Более сложный пример:
int x=3; int y=5; print (x/y); print((double)x/y); print(1.0*x/y);
Результатом будет:
0 0.6 0.6
В первый раз оба аргумента были целыми, поэтому в результате получился ноль. Однако поскольку оба операнда представлены переменными, в этом примере нельзя просто поставить десятичную точку и таким образом перевести вычисления в дробный тип. Необходимо либо преобразовать один из аргументов (второй вывод на экран), либо вставить еще одну фиктивную операцию с дробным аргументом (последняя строка).
Приведение типов подробно рассматривается в другой лекции, однако обратим здесь внимание на несколько моментов.
Во-первых, при приведении дробных значений к целым типам дробная часть просто отбрасывается. Например, число 3.84 будет преобразовано в целое 3, а -3.84 превратится в -3. Для математического округления необходимо воспользоваться методом класса Math.round(…).
Во-вторых, при приведении значений int к типу float и при приведении значений типа long к типу float и double возможны потери точности, несмотря на то, что эти дробные типы вмещают гораздо большие числа, чем соответствующие целые. Рассмотрим следующий пример:
long l=111111111111L; float f = l; l = (long) f; print(l);
Результатом будет:
111111110656
Тип float не смог сохранить все значащие разряды, хотя преобразование от long к float произошло без специального оператора в отличие от обратного перехода.
Для каждого примитивного типа существуют специальные вспомогательные классы-обертки (wrapper classes). Для типов float и double это Float и Double. Эти классы содержат многие полезные методы для работы с дробными значениями. Например, преобразование из текста в число.
Кроме того, класс Math предоставляет большое количество методов для операций над дробными значениями, например, извлечение квадратного корня, возведение в любую степень, тригонометрические и другие. Также в этом классе определены константы PI и основание натурального логарифма E.
Equals()
Этот метод имеет один аргумент типа Object и возвращает boolean. Как уже говорилось, equals() служит для сравнения объектов по значению, а не по ссылке. Сравнивается состояние объекта, у которого вызывается этот метод, с передаваемым аргументом.
Point p1=new Point(2,3); Point p2=new Point(2,3); print(p1.equals(p2));
Результатом будет true.
Поскольку сам Object не имеет полей, а значит, и состояния, в этом классе метод equals возвращает результат сравнения по ссылке. Однако при написании нового класса можно переопределить этот метод и описать правильный алгоритм сравнения по значению (что и сделано в большинстве стандартных классов). Соответственно, в класс Point также необходимо добавить переопределенный метод сравнения:
public boolean equals(Object o) { // Сначала необходимо убедиться, что // переданный объект совместим с типом // Point if (o instanceof Point) { // Типы совместимы, можно провести // преобразование Point p = (Point)o; // Возвращаем результат сравнения // координат return p.x==x && p.y==y; } // Если объект не совместим с Point, // возвращаем false return false; }
Finalize()
Данный метод вызывается при уничтожении объекта автоматическим сборщиком мусора (garbage collector). В классе Object он ничего не делает, однако в классе-наследнике позволяет описать все действия, необходимые для корректного удаления объекта, такие как закрытие соединений с БД, сетевых соединений, снятие блокировок на файлы и т.д. В обычном режиме напрямую этот метод вызывать не нужно, он отработает автоматически. Если необходимо, можно обратиться к нему явным образом.
В методе finalize() нужно описывать только дополнительные действия, связанные с логикой работы программы. Все необходимое для удаления объекта JVM сделает сама.
Программирование на Java
Этот метод возвращает объект класса Class, который описывает класс, от которого был порожден этот объект. Класс Class будет рассмотрен ниже. У него есть метод getName(), возвращающий имя класса:
String s = "abc"; Class cl=s.getClass(); print(cl.getName());
Результатом будет строка:
java.lang.String
В отличие от оператора instanceof, метод getClass() всегда возвращает точно тот класс, от которого был порожден объект.
HashCode()
Данный метод возвращает значение int. Цель hashCode() – представить любой объект целым числом. Особенно эффективно это используется в хэш-таблицах (в Java есть стандартная реализация такого хранения данных, она будет рассмотрена позже). Конечно, нельзя потребовать, чтобы различные объекты возвращали различные хэш-коды, но, по крайней мере, необходимо, чтобы объекты, равные по значению (метод equals() возвращает true), возвращали одинаковые хэш-коды.
В классе Object этот метод реализован на уровне JVM. Сама виртуальная машина генерирует число хеш-кодов, основываясь на расположении объекта в памяти.
Исходные тексты аплета Draw
Назад Вперед
Исходные тексты аплета Draw вы найдете в листинге 1.
Листинг 1. Файл draw.java
import java.applet.*; import java.awt.*;
public class draw extends Applet { Toolkit tk; String szFontList[]; FontMetrics fm; int yStart = 20; int yStep; String parm_TestString;
public void init() { tk = Toolkit.getDefaultToolkit(); szFontList = tk.getFontList(); parm_TestString = getParameter("TestString"); }
public String getAppletInfo() { return "Name: draw"; }
public void paint(Graphics g) { int yDraw; Dimension dimAppWndDimension = getSize();
g.clearRect(0, 0, dimAppWndDimension.width - 1, dimAppWndDimension.height - 1);
g.setColor(Color.yellow); g.fillRect(0, 0, dimAppWndDimension.width - 1, dimAppWndDimension.height - 1);
g.setColor(Color.black); g.drawRect(0, 0, dimAppWndDimension.width - 1, dimAppWndDimension.height - 1);
fm = g.getFontMetrics(); yStep = fm.getHeight();
for(int i = 0; i < szFontList.length; i++) { g.setFont(new Font("Helvetica", Font.PLAIN, 12)); g.drawString(szFontList[i], 10, yStart + yStep * i);
fm = g.getFontMetrics(); yStep = fm.getHeight();
g.setFont(new Font(szFontList[i], Font.PLAIN, 12)); g.drawString(parm_TestString, 100, yStart + yStep * i); }
yDraw = yStart + yStep * szFontList.length + yStep;
Polygon p = new Polygon();
p.addPoint(70, yDraw); p.addPoint(150, yDraw + 30); p.addPoint(160, yDraw + 80); p.addPoint(190, yDraw + 60); p.addPoint(140, yDraw + 30); p.addPoint(70, yDraw + 39);
g.drawPolygon(p);
g.setColor(Color.red); g.drawRect(10, yDraw + 85, 200, 100);
g.setColor(Color.black); g.drawArc(10, yDraw + 85, 200, 100, -50, 320); }
public String[][] getParameterInfo() { String[][] info = { { "TestString", "String", "Test string" } }; return info; } }
Извлечение списка шрифтов
Процедура извлечения списка доступных шрифтов достаточно проста и выполняется следующим образом:
Toolkit tk; String szFontList[]; . . . tk = Toolkit.getDefaultToolkit(); szFontList = tk.getFontList();
Аплет вызывает статический метод getDefaultToolkit из класса Toolkit и затем, пользуясь полученной ссылкой, извлекает список шрифтов, записывая его в массив szFontList.
Для чего еще можно использовать класс Toolkit?
Класс Toolkit является абстрактным суперклассом для всех реализаций AWT. Порожденные от него классы используются для привязки различных компонент конкретных реализаций.
Создавая свои аплеты, вы будете редко прибегать к услугам этого класса. Однако в нем есть несколько полезных методов, прототипы которых мы перечислим ниже:
getDefaultToolkit
Получение ссылки на Toolkit
public static Toolkit getDefaultToolkit();
getColorModel
Определение текущей цветовой модели, выбранной в контекст отображения
public abstract ColorModel getColorModel();
getFontList
Получение списка шрифтов, доступных аплету
public abstract String[] getFontList();
getFontMetrics
Получение метрик заданного шрифта
public abstract FontMetrics getFontMetrics(Font font);
getImage
Получение растрового изображения по имени файла
public abstract Image getImage(String filename);
getImage
Получение растрового изображения по адресу URL
public abstract Image getImage(URL url);
getScreenResolution
Определение разрешения экрана в точках на дюйм
public abstract int getScreenResolution();
getScreenSize
Размеры экрана в пикселах
public abstract Dimension getScreenSize();
prepareImage
Подготовка растрового изображения для вывода
public abstract boolean prepareImage( Image image, int width, int height, ImageObserver observer);
sync
Синхронизация состояния Toolkit
public abstract void sync();
Наиболее интересны, с нашей точки зрения, методы getFontList, getScreenResolution и getScreenSize, с помощью которых аплет может, соответственно, получить список шрифтов, определить разрешение и размер экрана. Последние два параметра позволяют сформировать содержимое окна аплета оптимальным образом исходя из объема информации, который может в нем разместиться.
Класс Class
Наконец, последний класс, который будет рассмотрен в этой лекции.
Класс Class является метаклассом для всех классов Java. Когда JVM загружает файл .class, который описывает некоторый тип, в памяти создается объект класса Class, который будет хранить это описание.
Например, если в программе есть строка
Point p=new Point(1,2);
то это означает, что в системе созданы следующие объекты:
объект типа Point, описывающий точку (1,2);объект класса Class, описывающий класс Point;объект класса Class, описывающий класс Object. Поскольку класс Point наследуется от Object, его описание также необходимо;объект класса Class, описывающий класс Class. Это обычный Java-класс, который должен быть загружен по общим правилам.
Одно из применений класса Class уже было рассмотрено – использование метода getClass() класса Object. Если продолжить последний пример с точкой:
Class cl=p.getClass(); // это объект №2 из списка Class cl2=cl.getClass(); // это объект №4 из списка Class cl3=cl2.getClass(); // опять объект №4
Выражение cl2==cl3 верно.
Другое применение класса Class также приводилось в примере применения технологии reflection.
Кроме прямого использования метакласса для хранения в памяти описания классов, Java использует эти объекты и для других целей, которые будут рассмотрены ниже (статические переменные, синхронизация статических методов и т.д.).
Класс Font
Приведем краткое перечисление полей, конструкторов и методов этого класса.
Класс Object
В Java множественное наследование отсутствует. Каждый класс может иметь только одного родителя. Таким образом, мы можем проследить цепочку наследования от любого класса, поднимаясь все выше. Существует класс, на котором такая цепочка всегда заканчивается, это класс Object. Именно от него наследуются все классы, в объявлении которых явно не указан другой родительский класс. А значит, любой класс напрямую, или через своих родителей, является наследником Object. Отсюда следует, что методы этого класса есть у любого объекта (поля в Object отсутствуют), а потому они представляют особенный интерес.
Рассмотрим основные из них.
Класс String
Как уже указывалось, класс String занимает в Java особое положение. Экземпляры только этого класса можно создавать без использования ключевого слова new. Каждый строковый литерал порождает экземпляр String, и это единственный литерал (кроме null), имеющий объектный тип.
Затем значение любого типа может быть приведено к строке с помощью оператора конкатенации строк, который был рассмотрен для каждого типа, как примитивного, так и объектного.
Еще одним важным свойством данного класса является неизменяемость. Это означает, что, породив объект, содержащий некое значение-строку, мы уже не можем изменить данное значение – необходимо создать новый объект.
String s="a"; s="b";
Во второй строке переменная сменила свое значение, но только создав новый объект класса String.
Поскольку каждый строковый литерал порождает новый объект, что есть очень ресурсоемкая операция в Java, зачастую компилятор стремится оптимизировать эту работу.
Во-первых, если используется несколько литералов с одинаковым значением, для них будет создан один и тот же объект.
String s1 = "abc"; String s2 = "abc"; String s3 = "a"+"bc"; print(s1==s2); print(s1==s3);
Результатом будет:
true true
То есть в случае, когда строка конструируется из констант, известных уже на момент компиляции, оптимизатор также подставляет один и тот же объект.
Если же строка создается выражением, которое может быть вычислено только во время исполнения программы, то оно будет порождать новый объект:
String s1="abc"; String s2="ab"; print(s1==(s2+"c"));
Результатом будет false, так как компилятор не может предсказать результат сложения значения переменной с константой.
В классе String определен метод intern(), который возвращает один и тот же объект-строку для всех экземпляров, равных по значению. То есть если для ссылок s1 и s2 верно выражение s1.equals(s2), то верно и s1.intern()==s2.intern().
Разумеется, в классе переопределены методы equals() и hashCode(). Метод toString() также переопределен и возвращает он сам объект-строку, то есть для любой ссылки s типа String, не равной null, верно выражение s==s.toString().
Как уже указывалось, класс String занимает в Java особое положение. Экземпляры только этого класса можно создавать без использования ключевого слова new. Каждый строковый литерал порождает экземпляр String, и это единственный литерал (кроме null), имеющий объектный тип.
Затем значение любого типа может быть приведено к строке с помощью оператора конкатенации строк, который был рассмотрен для каждого типа, как примитивного, так и объектного.
Еще одним важным свойством данного класса является неизменяемость. Это означает, что, породив объект, содержащий некое значение-строку, мы уже не можем изменить данное значение – необходимо создать новый объект.
String s="a"; s="b";
Во второй строке переменная сменила свое значение, но только создав новый объект класса String.
Поскольку каждый строковый литерал порождает новый объект, что есть очень ресурсоемкая операция в Java, зачастую компилятор стремится оптимизировать эту работу.
Во-первых, если используется несколько литералов с одинаковым значением, для них будет создан один и тот же объект.
String s1 = "abc"; String s2 = "abc"; String s3 = "a"+"bc"; print(s1==s2); print(s1==s3);
Результатом будет:
true true
То есть в случае, когда строка конструируется из констант, известных уже на момент компиляции, оптимизатор также подставляет один и тот же объект.
Если же строка создается выражением, которое может быть вычислено только во время исполнения программы, то оно будет порождать новый объект:
String s1="abc"; String s2="ab"; print(s1==(s2+"c"));
Результатом будет false, так как компилятор не может предсказать результат сложения значения переменной с константой.
В классе String определен метод intern(), который возвращает один и тот же объект-строку для всех экземпляров, равных по значению. То есть если для ссылок s1 и s2 верно выражение s1.equals(s2), то верно и s1.intern()==s2.intern().
Разумеется, в классе переопределены методы equals() и hashCode(). Метод toString() также переопределен и возвращает он сам объект-строку, то есть для любой ссылки s типа String, не равной null, верно выражение s==s.toString().
Контекст отображения
Назад Вперед
Проще всего представить себе контекст отображения как полотно, на котором рисует художник. Точно так же как художник может выбирать для рисования различные инструменты, программист, создающий аплет Java, может выбирать различные методы класса Graphics и задавать различные атрибуты контекста отображения.
Копирование содержимого прямоугольной области
Метод copyArea позволяет скопировать содержимое любой прямоугольной области окна аплета:
public abstract void copyArea( int x, int y, int width, int height, int dx, int dy);
Параметры x, y, width и height задают координаты копируемой прямоугольной области. Область копируется в другую прямоугольную область такого же размера, причем параметры dx и dy определяют координаты последней.
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Линии
Для того чтобы нарисовать прямую тонкую сплошную линию, вы можете воспользоваться методом drawLine, прототип которого приведен ниже:
public abstract void drawLine(int x1, int y1,int x2, int y2);
Концы линии имеют координаты (x1, y1) и (x2, y2), как это показано нарис. 1.

Рис. 1. Рисование прямой линии
К сожалению, в контексте отображения не предусмотрены никакие атрибуты, позволяющие нарисовать пунктирную линию или линию увеличенной толщины.
Метод init
При инициализации аплета метод init извлекает список доступных шрифтов и принимает значение параметра TestString, передаваемое аплету в документе HTML.
Метод paint
Первым делом метод paint определяет размеры окна аплета, вызывая для этого метод getSize:
Dimension dimAppWndDimension = getSize();
Метод getSize возвращает ссылку на объект класса Dimension, хранящий высоту и ширину объекта:
height
Высота
public int height;
width
Ширина
public int width;
В классе Dimension предусмотрено три конструктора и один метод:
public Dimension(); public Dimension(Dimension d); public Dimension(int width, int height);
toString
Получение строки, представляющей класс
public String toString();
После определения размеров окна аплета метод paint стирает содержимое всего окна:
g.clearRect(0, 0, dimAppWndDimension.width - 1, dimAppWndDimension.height - 1);
Далее в контексте отображения устанавливается желтый цвет:
g.setColor(Color.yellow);
Этим цветом заполняется внутренняя область окна аплета, для чего применяется метод fillRect:
g.fillRect(0, 0, dimAppWndDimension.width - 1, dimAppWndDimension.height - 1);
Затем метод paint устанавливает в контексте отображения черный цвет и рисует тонкую черную рамку вокруг окна аплета:
g.setColor(Color.black); g.drawRect(0, 0, dimAppWndDimension.width - 1, dimAppWndDimension.height - 1);
На следующем этапе мы получаем метрики текущего шрифта, выбранного в контекст отображения:
fm = g.getFontMetrics();
Пользуясь этими метриками, мы определяем высоту символов текущего шрифта и записываем ее в поле yStep:
yStep = fm.getHeight();
После этого метод paint запускает цикл по всем шрифтам, установленным в системе:
for(int i = 0; i < szFontList.length; i++) { . . . }
Количество доступных шрифтов равно размеру массива szFontList, которое вычисляется как szFontList.length.
Метод paint выписывает в окне аплета название каждого шрифта, устанавливая для этого шрифт Helvetica размером 12 пикселов:
g.setFont(new Font("Helvetica", Font.PLAIN, 12)); g.drawString(szFontList[i], 10, yStart + yStep * i);
Смещение каждой новой строки с названием шрифта вычисляется исходя из высоты символов установленного шрифта:
fm = g.getFontMetrics(); yStep = fm.getHeight();
После названия шрифта метод paint рисует в окне аплета текстовую строку parm_TestString, полученную через параметр с именем "TestString":
g.setFont(new Font(szFontList[i], Font.PLAIN, 12)); g.drawString(parm_TestString, 100, yStart + yStep * i);
Перед тем как перейти к рисованию геометрических фигур, метод paint запоминает в поле yDraw координату последней строки названия шрифта, сделав отступ высотой yStep :
int yDraw; yDraw = yStart + yStep * szFontList.length + yStep;
Первая фигура, которую рисует наш аплет, это многоугольник.
Мы создаем многоугольник как объект класса Polygon:
Polygon p = new Polygon();
В этот объект при помощи метода addPoint добавляется несколько точек:
p.addPoint(70, yDraw); p.addPoint(150, yDraw + 30); p.addPoint(160, yDraw + 80); p.addPoint(190, yDraw + 60); p.addPoint(140, yDraw + 30); p.addPoint(70, yDraw + 39);
После добавления всех точек метод paint рисует многоугольник, вызывая для этого метод drawPolygon:
g.drawPolygon(p);
Затем мы устанавливаем в контексте отображения красный цвет и рисуем прямоугольник:
g.setColor(Color.red); g.drawRect(10, yDraw + 85, 200, 100);
Затем метод paint вписывает в этот прямоугольник сегмент окружности:
g.setColor(Color.black); g.drawArc(10, yDraw + 85, 200, 100, -50, 320);
Методы
clearRect
Стирание содержимого прямоугольной области
public abstract void clearRect(int x, int y, int width, int height);
clipRect
Задание области ограничения вывода
public abstract void clipRect(int x, int y, int width, int height);
copyArea
Копирование содержимого прямоугольной области
public abstract void copyArea(int x, int y, int width, int height, int dx, int dy);
create
Создание контекста отображения
public abstract Graphics create();
public Graphics create(int x, int y, int width, int height);
dispose
Удаление контекста отображения
public abstract void dispose();
draw3DRect
Рисование прямоугольной области с трехмерным выделением
public void draw3DRect(int x, int y, int width, int height, boolean raised);
drawArc
Рисование сегмента
public abstract void drawArc(int x, int y, int width, int height, int startAngle, int arcAngle);
Рисование сегмента
drawBytes
Рисование текста из массива байт
public void drawBytes(byte data[], int offset, int length, int x, int y);
drawChars
Рисование текста из массива символов
public void drawChars(char data[], int offset, int length, int x, int y);
drawImage
Рисование растрового изображения
public abstract boolean drawImage(Image img, int x, int y, Color bgcolor, ImageObserver observer);
public abstract boolean drawImage(Image img, int x, int y, ImageObserver observer);
public abstract boolean drawImage(Image img, int x, int y, int width, int height, Color bgcolor, ImageObserver observer);
public abstract boolean drawImage(Image img, int x, int y, int width, int height, ImageObserver observer);
drawLine
Рисование линии
public abstract void drawLine(int x1, int y1, int x2, int y2);
drawOval
Рисование овала
public abstract void drawOval(int x, int y, int width, int height);
drawPolygon
Рисование многоугольника
public abstract void drawPolygon( int xPoints[], int yPoints[], int nPoints);
public void drawPolygon(Polygon p);
drawRect
Рисование прямоугольника
public void drawRect(int x, int y, int width, int height);
equals
Сравнение шрифтов
public boolean equals(Object obj);
getFamily
Определение названия семейства шрифтов
public String getFamily();
getFont
Получение шрифта по его характеристикам
public static Font getFont(String nm); public static Font getFont(String nm, Font font);
getName
Определение названия шрифта
public String getName();
getSize
Определение размера шрифта
public int getSize();
getStyle
Определение стиля шрифта
public int getStyle();
hashCode
Получение хэш-кода шрифта
public int hashCode();
isBold
Определение жирности шрифта
public boolean isBold();
isItalic
Проверка, является ли шрифт наклонным
public boolean isItalic();
isPlain
Проверка, есть ли шрифтовое выделение
public boolean isPlain();
toString
Получение текстовой строки для объекта
public String toString();
Создавая шрифт конструктором Font, вы должны указать имя, стиль и размер шрифта.
В качестве имени можно указать, например, такие строки как Helvetica или Courier. Учтите, что в системе удаленного пользователя, загрузившего ваш аплет, может не найтись шрифта с указанным вами именем. В этом случае браузер заменит его на наиболее подходящий (с его точки зрения).
Стиль шрифта задается масками BOLD, ITALIC и PLAIN, которые можно комбинировать при помощи логической операции "ИЛИ":
| Маска | Описание |
| BOLD | Утолщенный шрифт |
| ITALIC | Наклонный шрифт |
| PLAIN | Шрифтовое выделение не используется |
Что же касается размера шрифта, то он указывается в пикселах.
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
addPoint
Добавление вершины
public void addPoint(int x, int y);
getBoundingBox
Получение координат охватывающего прямоугольника
public Rectangle getBoundingBox();
inside
Проверка, находится ли точка внутри многоугольника
public boolean inside(int x, int y);
Ниже мы показали фрагмент кода, в котором создается многоугольник, а затем в него добавляется несколько точек. Многоугольник рисуется методом drawPolygon:
Polygon p = new Polygon(); p.addPoint(270, 239); p.addPoint(350, 230); p.addPoint(360, 180); p.addPoint(390, 160); p.addPoint(340, 130); p.addPoint(270, 239); g.drawPolygon(p);
Если вам нужно нарисовать заполненный многоугольник (рис. 7), то для этого вы можете воспользоваться методами, приведенными ниже:
public abstract void fillPolygon( int xPoints[], int yPoints[], int nPoints);
public void fillPolygon(Polygon p);
Первый из этих методов рисует многоугольник, координаты вершин которого заданы в массивах, второй - получая объект класса Polygon в качестве параметра.

Рис. 7. Многоугольник, нарисованный методом fillPolygon
Методы класса Graphics
В качестве базового для класса Graphics (полное название класса java.awt.Graphics) выступает класс java.lang.Object.
Прежде всего мы приведем прототипы конструктора этого класса и его методов с краткими комментариями. Полное описание вы сможете найти в электронной документации, которая входит в комплект Java WorkShop.
Далее мы рассмотрим назначение основных методов, сгруппировав их по выполняемым функциям.
Многоугольники
Для рисования многоугольников в классе Graphics предусмотрено четыре метода, два из которых рисуют незаполненные многоугольники, а два - заполненные.
Первый метод рисует незаполненный многоугольник, заданный массивами координат по осям X и Y:
public abstract void drawPolygon( int xPoints[], int yPoints[], int nPoints);
Через параметры xPoints и yPoints передаются, соответственно, ссылки на массивы координат по оис X и Y. Параметр nPoints задает количество точек в массивах.
На рис. 6 показан многоугольник, нарисованный методом drawPolygon.

Рис. 6. Многоугольник, нарисованный методом drawPolygon
В этом многоугольнике шесть вершин с координатами от (x0,y0) до (x5, y5), причем для того чтобы он стал замкнутым, координаты первой и последней вершины совпадают.
Второй метод также рисует незаполненный многоугольник, однако в качестве параметра методу передается ссылка на объект Polygon:
public void drawPolygon(Polygon p);
Класс Polygon достаточно прост. Приведем описание его полей, конструкторов и методов:
Объекты и правила работы с ними
Объект (object) – это экземпляр некоторого класса, или экземпляр массива. Массивы будут подробно рассматриваться в соответствующей лекции. Класс – это описание объектов одинаковой структуры, и если в программе такой класс используется, то описание присутствует в единственном экземпляре. Объектов этого класса может не быть вовсе, а может быть создано сколь угодно много.
Объекты всегда создаются с использованием ключевого слова new, причем одно слово new порождает строго один объект (или вовсе ни одного, если происходит ошибка). После ключевого слова указывается имя класса, от которого мы собираемся породить объект. Создание объекта всегда происходит через вызов одного из конструкторов класса (их может быть несколько), поэтому в заключение ставятся скобки, в которых перечислены значения аргументов, передаваемых выбранному конструктору. В приведенных выше примерах, когда создавались объекты типа Point, выражение new Point (3,5) означало обращение к конструктору класса Point, у которого есть два аргумента типа int. Кстати, обязательное объявление такого конструктора в упрощенном объявлении класса отсутствовало. Объявление классов рассматривается в следующих лекциях, однако приведем правильное определение Point:
class Point { int x, y;
/** * Конструктор принимает 2 аргумента, * которыми инициализирует поля объекта. */ Point (int newx, int newy){ x=newx; y=newy; } }
Если конструктор отработал успешно, то выражение new возвращает ссылку на созданный объект. Эту ссылку можно сохранить в переменной, передать в качестве аргумента в какой-либо метод или использовать другим способом. JVM всегда занимается подсчетом хранимых ссылок на каждый объект. Как только обнаруживается, что ссылок больше нет, такой объект предназначается для уничтожения сборщиком мусора (garbage collector). Восстановить ссылку на такой "потерянный" объект невозможно.
Point p=new Point(1,2); // Создали объект, получили на него ссылку Point p1=p; // теперь есть 2 ссылки на точку (1,2) p=new Point(3,4); // осталась одна ссылка на точку (1,2) p1=null;
Ссылок на объект-точку (1,2) больше нет, доступ к нему утерян и он вскоре будет уничтожен сборщиком мусора.
Любой объект порождается только с применением ключевого слова new. Единственное исключение – экземпляры класса String. Записывая любой строковый литерал, мы автоматически порождаем объект этого класса. Оператор конкатенации +, результатом которого является строка, также неявно порождает объекты без использования ключевого слова new.
Рассмотрим пример:
"abc"+"def"
При выполнении этого выражения будет создано три объекта класса String. Два объекта порождаются строковыми литералами, третий будет представлять результат конкатенации.
Операция создания объекта – одна из самых ресурсоемких в Java. Поэтому следует избегать ненужных порождений. Поскольку при работе со строками их может создаваться довольно много, компилятор, как правило, пытается оптимизировать такие выражения. В рассмотренном примере, поскольку все операнды являются константами времени компиляции, компилятор сам осуществит конкатенацию и вставит в код уже результат, сократив таким образом количество создаваемых объектов до одного.
Кроме того, в версии Java 1.1 была введена технология reflection, которая позволяет обращаться к классам, методам и полям, используя лишь их имя в текстовом виде. С ее помощью также можно создать объект без ключевого слова new, однако эта технология довольно специфична, применяется в редких случаях, а кроме того, довольно проста и потому в данном курсе не рассматривается. Все же приведем пример ее применения:
Point p = null; try { // в следующей строке, используя лишь // текстовое имя класса Point, порождается // объект без применения ключевого слова new p=(Point)Class.forName("Point").newInstance();
} catch (Exception e) { // обработка ошибок System.out.println(e); }
Объект всегда "помнит", от какого класса он был порожден. С другой стороны, как уже указывалось, можно ссылаться на объект, используя ссылку другого типа. Приведем пример, который будем еще много раз использовать. Сначала опишем два класса, Parent и его наследник Child:
// Объявляем класс Parent class Parent { }
// Объявляем класс Child и наследуем // его от класса Parent class Child extends Parent { }
Пока нам не нужно определять какие-либо поля или методы. Далее объявим переменную одного типа и проинициализируем ее значением другого типа:
Parent p = new Child();
Теперь переменная типа Parent указывает на объект, порожденный от класса Child.
Над ссылочными значениями можно производить следующие операции:
обращение к полям и методам объектаоператор instanceof (возвращает булевское значение)операции сравнения == и != (возвращают булевское значение)оператор приведения типовоператор с условием ? : оператор конкатенации со строкой +
Обращение к полям и методам объекта можно назвать основной операцией над ссылочными величинами. Осуществляется она с помощью символа . (точка). Примеры ее применения будут приводиться.
Используя оператор instanceof, можно узнать, от какого класса произошел объект. Этот оператор имеет два аргумента. Слева указывается ссылка на объект, а справа – имя типа, на совместимость с которым проверяется объект. Например:
Parent p = new Child(); // проверяем переменную p типа Parent // на совместимость с типом Child print(p instanceof Child);
Результатом будет true. Таким образом, оператор instanceof опирается не на тип ссылки, а на свойства объекта, на который она ссылается. Но этот оператор возвращает истинное значение не только для того типа, от которого был порожден объект. Добавим к уже объявленным классам еще один:
// Объявляем новый класс и наследуем // его от класса Child class ChildOfChild extends Child { }
Теперь заведем переменную нового типа:
Parent p = new ChildOfChild(); print(p instanceof Child);
В первой строке объявляется переменная типа Parent, которая инициализируется ссылкой на объект, порожденный от ChildOfChild. Во второй строке оператор instanceof анализирует совместимость ссылки типа Parent с классом Child, причем задействованный объект не порожден ни от первого, ни от второго класса. Тем не менее, оператор вернет true, поскольку класс, от которого этот объект порожден, наследуется от Child.
Добавим еще один класс:
class Child2 extends Parent { }
И снова объявим переменную типа Parent:
Parent p=new Child(); print(p instanceof Child); print(p instanceof Child2);
Переменная p имеет тип Parent, а значит, может ссылаться на объекты типа Child или Child2. Оператор instanceof помогает разобраться в ситуации:
true false
Для ссылки, равной null, оператор instanceof всегда вернет значение false.
С изучением свойств объектной модели Java мы будем возвращаться к алгоритму работы оператора instanceof.
Операторы сравнения == и != проверяют равенство (или неравенство) объектных величин именно по ссылке. Однако часто требуется альтернативное сравнение – по значению. Сравнение по значению имеет дело с понятием состояние объекта. Сам смысл этого выражения рассматривается в ООП, что же касается реализации в Java, то состояние объекта хранится в его полях. При сравнении по ссылке ни тип объекта, ни значения его полей не учитываются, true возвращается только в том случае, если обе ссылки указывают на один и тот же объект.
Point p1=new Point(2,3); Point p2=p1; Point p3=new Point(2,3); print(p1==p2); print(p1==p3);
Результатом будет:
true false
Первое сравнение оказалось истинным, так как переменная p2 ссылается на тот же объект, что и p1. Второе же сравнение ложно, несмотря на то, что переменная p3 ссылается на объект-точку с точно такими же координатами. Однако это другой объект, который был порожден другим выражением new.
Если один из аргументов оператора = равен null, а другой – нет, то значение такого выражения будет false. Если же оба операнда null, то результат будет true.
Для корректного сравнения по значению существует специальный метод equals, который будет рассмотрен позже. Например, строки надо сравнивать следующим образом:
String s = "abc"; s=s+1; print(s.equals("abc1"));
Операция с условием ? : работает как обычно и может принимать второй и третий аргументы, если они оба одновременно ссылочного типа. Результат такого оператора также будет иметь объектный тип.
Как и простые типы, ссылочные величины можно складывать со строкой. Если ссылка равна null, то к строке добавляется текст "null". Если же ссылка указывает на объект, то у него вызывается специальный метод (он будет рассмотрен ниже, его имя toString()) и текст, который он вернет, будет добавлен к строке.
Определение атрибутов контекста отображения
Назад Вперед
Ряд методов класса Graphics позволяет определить различные атрибуты контекста отображения, например, цвет, выбранный в контекст отображения или метрики текущего шрифта, которым выполняется рисование текста.
Рассмотрим методы, позволяющие определить атрибуты контекста отображения.
Определение цвета, выбранного в контекст отображения
Метод getColor возвращает ссылку на объект класса Color, представляющий текущий цвет, выбранный в контекст отображения:
public abstract Color getColor();
Определение границ области ограничения вывода
С помощью метода clipRect, о котором мы расскажем чуть позже, вы можете определить в окне аплета область ограничения вывода прямоугольной формы. Вне этой области рисование графических изображений и текста не выполняется.
Метод getClipRect позволяет вам определить координаты текущей области ограничения, заданной в контексте отображения:
public abstract Rectangle getClipRect();
Метод возвращает ссылку на объект класса Rectangle, который, в частности, имеет поля класса с именами x, y, height и width. В этих полях находится, соответственно, координаты верхнего левого угла, высота и ширина прямоугольной области.
Определение метрик текущего шрифта
Несмотря на то что вы можете заказать шрифт с заданным именем и размером, не следует надеяться, что навигатор выделит вам именно такой шрифт, какой вы попросите. Для правильного размещения текста и других изображений в окне аплета вам необходимо знать метрики реального шрифта, выбранного навигатором в контекст отображения.
Метрики текущего шрифта в контексте отображения вы можете узнать при помощи метода getFontMetrics, прототип которого приведен ниже:
public FontMetrics getFontMetrics();
Метод getFontMetrics возвращает ссылку на объект класса FontMetrics. Ниже мы привели список наиболее важных методов этого класса, предназначенных для получения отдельных параметров шрифта:
| Метод | Описание | |
| public Font getFont(); | Определение шрифта, который описывается данной метрикой | |
| public int bytesWidth(byte data[], int off, int len); | Метод возвращает ширину строки символов, расположенных в массиве байт data. Параметры off и len задают, соответственно, смещение начала строки в массиве и ее длину | |
| public int charsWidth(char data[], int off, int len); | Метод возвращает ширину строки символов, расположенных в массиве символов data. Параметры off и len задают, соответственно, смещение начала строки в массиве и ее длину | |
| public int charWidth(char ch); | Метод возвращает ширину заданного символа | |
| public int charWidth(int ch); | Метод возвращает ширину заданной строки символов | |
| public int getAscent(); | Определение расстояния от базовой линии до верхней выступающей части символов | |
| public int getDescent(); | Определение расстояния от базовой линии до нижней выступающей части символов | |
| public int getLeading(); | Расстояние между строками текста | |
| public int getHeight(); | Определение полной высоты символов, выполняется по формуле:
getLeading() + getAscent() + getDescent() | |
| public int getMaxAdvance(); | Максимальная ширина символов в шрифте | |
| public int getMaxAscent(); | Максимальное расстояние от базовой линии до верхней выступающей части символов для символов данного шрифта | |
| public int getMaxDescent(); | Максимальное расстояние от базовой линии до нижней выступающей части символов для символов данного шрифта | |
| public int[] getWidths(); | Массив, в котором хранятся значения ширины первых 256 символов в шрифте | |
| public int stringWidth(String str); | Ширина строки, передаваемой методу в качестве параметра | |
| public String toString(); | Текстовая строка, представляющая данную метрику шрифта |
Обратите внимание на метод stringWidth, позволяющий определить ширину текстовой строки. Заметим, что без этого метода определение ширины текстовой строки было бы непростой задачей, особенно если шрифт имеет переменную ширину символов.
Для определения полной высоты строки символов вы можете воспользоваться методом getHeight.
Определение метрик заданного шрифта
Метод getFontMetrics с параметром типа Font позволяет определить метрики любого шрифта, передаваемого ему в качестве параметра:
public abstract FontMetrics getFontMetrics(Font f);
В отличие от нее метод getFontMetrics без параметров возвращает метрики текущего шрифта, выбранного в контекст отображения.
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Определение шрифта, выбранного в контекст отображения
С помощью метода getFont, возвращающего ссылку на объект класса Font, вы можете определить текущий шрифт, выбранный в контекст отображения:
public abstract Font getFont();
Овалы и круги
Для рисования окружностей и овалов вы можете воспользоваться методом drawOval:
public abstract void drawOval( int x, int y,
int width, int height);
Параметры этого методы задают координаты и размеры прямоугольника, в который вписывается рисуемый овал (рис. 8).

Рис. 8. Рисование овала
Метод fillOval предназначен для рисования заполненного овала (рис. 9). Назначение его параметров аналогично назначению параметров метода drawOval:
public abstract void fillOval( int x, int y, int width, int height);

Рис. 9. Рисование заполненного овала
Переменные
Переменные используются в программе для хранения данных. Любая переменная имеет три базовых характеристики:
имя;тип;значение.
Имя уникально идентифицирует переменную и позволяет обращаться к ней в программе. Тип описывает, какие величины может хранить переменная. Значение – текущая величина, хранящаяся в переменной на данный момент.
Работа с переменной всегда начинается с ее объявления (declaration). Конечно, оно должно включать в себя имя объявляемой переменной. Как было сказано, в Java любая переменная имеет строгий тип, который также задается при объявлении и никогда не меняется. Значение может быть указано сразу (это называется инициализацией), а в большинстве случаев задание начальной величины можно и отложить.
Некоторые примеры объявления переменных примитивного типа int с инициализаторами и без таковых:
int a; int b = 0, c = 3+2; int d = b+c; int e = a = 5;
Из примеров видно, что инициализатором может быть не только константа, но и арифметическое выражение. Иногда это выражение может быть вычислено во время компиляции (такое как 3+2), тогда компилятор сразу записывает результат. Иногда это действие откладывается на момент выполнения программы (например, b+c). В последнем случае нескольким переменным присваивается одно и то же значение, однако объявляется лишь первая из них (в данном примере е), остальные уже должны существовать.
Резюмируем: объявление переменных и возможная инициализация при объявлении описываются следующим образом. Сначала указывается тип переменной, затем ее имя и, если необходимо, инициализатор, который может быть константой или выражением, вычисляемым во время компиляции или исполнения программы. В частности, можно пользоваться уже объявленными переменными. Далее можно поставить запятую и объявить новую переменную точно такого же типа.
После объявления переменная может применяться в различных выражениях, в которых будет браться ее текущее значение. Также в любой момент можно изменить значение, используя оператор присваивания, примерно так же, как это делалось в инициализаторах.
Кроме того, при объявлении переменной может быть использовано ключевое слово final. Его указывают перед типом переменной, и тогда ее необходимо сразу инициализировать и уже больше никогда не менять ее значение. Таким образом, final-переменные становятся чем-то вроде констант, но на самом деле некоторые инициализаторы могут вычисляться только во время исполнения программы, генерируя различные значения.
Простейший пример объявления final-переменной:
final double pi=3.1415;
Поля класса
name
protected String name;
size
protected int size;
style
protected int style;
Получение значения параметров
До сих пор наши аплеты не получали параметров из документов HTML, в которые мы их встраивали.
Конечно, все константы, текстовые строки, адреса URL и другую информацию можно закодировать непосредственно в исходном тексте аплета, однако, очевидно, это очень неудобно.
Пользуясь операторами <PARAM>, расположенными в документе HTML сразу после оператора <APPLET>, можно передать аплету произвольное количество параметров, например, в виде текстовых строк:
<applet code=MyApplet.class id=MyApplet . . . width=320 height=240 > <param name=ParamName1 value="Value 1"> <param name=ParamName2 value="Value 2"> <param name=ParamName3 value="Value 3"> <param name=ParamName4 value="Value 4"> . . . </applet>
Здесь через параметр NAME оператора <PARAM> передается имя параметра аплета, а через параметр VALUE - значение соответствующего параметра.
Как параметр может получить значение параметров?
Для получения значения любого параметра аплет должен использовать метод getParameter. В качестве единственного параметра этому методу передается имя параметра аплета в виде строки типа String, например:
parm_TestString = getParameter("TestString");
Обычно в аплете также определяется метод getParameterInfo, возвращающий информацию о параметрах. Вот исходный текст этого метода для нашего аплета Draw:
public String[][] getParameterInfo() { String[][] info = { { "TestString", "String", "Test string" } }; return info; }
Метод getParameterInfo возвращает массив массивов текстовых строк. Первая строка указывает имя параметра, вторая - тип передаваемых через него данных, а третья - значение параметра по умолчанию.
Примитивные и ссылочные типы данных
Теперь на примере переменных можно проиллюстрировать различие между примитивными и ссылочными типами данных. Рассмотрим пример, когда объявляются две переменные одного типа, приравниваются друг другу, а затем значение одной из них изменяется. Что произойдет со второй переменной?
Возьмем простой тип int:
int a=5; // объявляем первую переменную и // инициализируем ее int b=a; // объявляем вторую переменную и // приравниваем ее к первой a=3; // меняем значение первой print(b); // проверяем значение второй
Здесь и далее мы считаем, что функция print(...) позволяет нам некоторым (неважно, каким именно) способом узнать значение ее аргумента (как правило, для этого используют функцию из стандартной библиотеки System.out.println(...), которая выводит значение на системную консоль).
В результате мы увидим, что значение переменной b не изменилось, оно осталось равным 5. Это означает, что переменные простого типа хранят непосредственно свои значения и при приравнивании двух переменных происходит копирование данного значения. Чтобы еще раз подчеркнуть эту особенность, приведем еще один пример:
byte b=3; int a=b;
В данном примере происходит преобразование типов (оно подробно рассматривается в соответствующей лекции). Для нас сейчас важно констатировать, что переменная b хранит значение 3 типа byte, а переменная a – значение 3 типа int. Это два разных значения, и во второй строке при присваивании произошло копирование.
Теперь рассмотрим ссылочный тип данных. Переменные таких типов всегда хранят ссылки на некоторые объекты. Рассмотрим для примера класс, описывающий точку на координатной плоскости с целочисленными координатами. Описание класса – это отдельная тема, но в нашем простейшем случае оно тривиально:
class Point { int x, y; }
Теперь составим пример, аналогичный приведенному выше для int-переменных, считая, что выражение new Point(3,5) создает новый объект-точку с координатами (3,5).
Point p1 = new Point(3,5); Point p2=p1; p1.x=7; print(p2.x);
В третьей строке мы изменили горизонтальную координату точки, на которую ссылалась переменная p1, и теперь нас интересует, как это сказалось на точке, на которую ссылается переменная p2. Проведя такой эксперимент, можно убедиться, что в этот раз мы увидим обновленное значение. То есть объектные переменные после приравнивания остаются "связанными" друг с другом, изменения одной сказываются на другой.
Таким образом, примитивные переменные являются действительными хранилищами данных. Каждая переменная имеет значение, не зависящее от остальных. Ссылочные же переменные хранят лишь ссылки на объекты, причем различные переменные могут ссылаться на один и тот же объект, как это было в нашем примере. В этом случае их можно сравнить с наблюдателями, которые с разных позиций смотрят на один и тот же объект и одинаково видят все происходящие с ним изменения. Если же один наблюдатель сменит объект наблюдения, то он перестает видеть и изменения, происходящие с прежним объектом:
Point p1 = new Point(3,5); Point p2=p1; p1 = new Point(7,9); print(p2.x);
В этом примере мы получим 3, то есть после третьей строки переменные p1 и p2 ссылаются на различные объекты и поэтому имеют разные значения.
Теперь легко понять смысл литерала null. Такое значение может принять переменная любого ссылочного типа. Это означает, что ее ссылка никуда не указывает, объект отсутствует. Соответственно, любая попытка обратиться к объекту через такую переменную (например, вызвать метод или взять значение поля) приведет к ошибке.
Также значение null можно передать в качестве любого объектного аргумента при вызове функций (хотя на практике многие методы считают такое значение некорректным).
Память в Java с точки зрения программиста представляется не нулями и единицами или набором байтов, а как некое виртуальное пространство, в котором существуют объекты. И доступ к памяти осуществляется не по физическому адресу или указателю, а лишь через ссылки на объекты. Ссылка возвращается при создании объекта и далее может быть сохранена в переменной, передана в качестве аргумента и т.д. Как уже говорилось, допускается наличие нескольких ссылок на один объект. Возможна и противоположная ситуация – когда на какой-то объект не существует ни одной ссылки. Такой объект уже недоступен программе и является "мусором", то есть без толку занимает аппаратные ресурсы. Для их освобождения не требуется никаких усилий. В состав любой виртуальной машины обязательно входит автоматический сборщик мусора garbage collector – фоновый процесс, который как раз и занимается уничтожением ненужных объектов.
Очень важно помнить, что объектная переменная, в отличие от примитивной, может иметь значение другого типа, не совпадающего с типом переменной. Например, если тип переменной – некий класс, то переменная может ссылаться на объект, порожденный от наследника этого класса. Все случаи подобного несовпадения будут рассмотрены в следующих разделах курса.
Теперь рассмотрим примитивные и ссылочные типы данных более подробно.
Примитивные типы
Как уже говорилось, существует 8 простых типов данных, которые делятся на целочисленные (integer), дробные (floating-point) и булевские (boolean).
Прямоугольники и квадраты
Среди методов класса Graphics есть несколько, предназначенных для рисования прямоугольников. Первый из них, с именем drawRect, позволяет нарисовать прямоугольник, заданный координатами своего левого верхнего угла, шириной и высотой:
public void drawRect(int x, int y, int width, int height);
Параметры x и y задают, соответственно, координаты верхнего левого угла, а параметры width и height - высоту и ширину прямоугольника (рис. 2).

Рис. 2. Рисование прямоугольника
В отличие от метода drawRect, рисующего только прямоугольную рамку, метод fillRect рисует заполненный прямоугольник. Для рисования и заполнения прямоугольника используется цвет, выбранный в контекст отображения (рис. 3).

Рис. 3. Рисование заполненного прямоугольника
Прототип метода fillRect приведен ниже:
public abstract void fillRect(int x, int y, int width, int height);
Метод drawRoundRect позволяет нарисовать прямоугольник с закругленными углами:
public abstract void drawRoundRect(int x, int y, int width, int height, int arcWidth, int arcHeight);
Параметры x и y определяют координаты верхнего левого угла прямоугольника, параметры width и height задают, соответственно его ширину и высоту.
Размеры эллипса, образующего закругления по углам, вы можете задать с помощью параметров arcWidth и arcHeight. Первый из них задает ширину эллипса, а второй - высоту (рис. 4).

Рис. 4. Рисование прямоугольника с закругленными углами
Метод fillRoundRect позволяет нарисовать заполненный прямоугольник с закругленными углами (рис. 5).

Рис. 5. Рисование заполненного прямоугольника с закругленными углами
Назначение параметров этого метода аналогично назначению параметров только что рассмотренного метода drawRoundRect:
public abstract void fillRoundRect(int x, int y, int width, int height, int arcWidth, int arcHeight);
Метод fill3Drect предназначен для рисования выступающего или западающего прямоугольника:
public void fill3DRect(int x, int y, int width, int height, boolean raised);
Если значение параметра raised равно true, рисуется выступающий прямоугольник, если false - западающий. Назначение остальных параметров аналогично назначению параметров метода drawRect.
Проект для аплета Draw
Назад Вперед
Подготовьте файлы проекта аплета Draw, скопировав их из предыдущего раздела в какой-нибудь каталог. Затем запустите мастер проектов и в соответствующей диалоговой панели укажите путь к этому каталогу (рис. 12).
 |
Рис. 12. Указание пути к каталогу с исходными файлами
Для того чтобы увидеть рисунок в увеличенном виде, сделайте щелчок мышью по изображению |
Так как в каталоге уже есть файлы, вы должны включить переключатель Yes и затем нажать кнопку Next.
После этого вы увидите на экране диалоговую панель, показанную на рис. 13.
 |
Рис. 13. Добавление к проекту существующих файлов
Для того чтобы увидеть рисунок в увеличенном виде, сделайте щелчок мышью по изображению |
Здесь вам нужно нажать кнопку Add All in Directory. Как только вы это сделаете, в списке файлов Project Files появится имя файла draw.java, подготовленного вами заранее.
На следующем шаге вам опять нужно нажать кнопку Next и проследить, чтобы имя главного класса аплета, отображаемое в диалоговой панели, показанной на рис. 14, было draw.
 |
Рис. 14. Задание имени главного класса
Для того чтобы увидеть рисунок в увеличенном виде, сделайте щелчок мышью по изображению |
Нажав кнопку Finish, вы можете завершить формирование проекта.
Hаш аплет принимает из документа HTML один параметр с именем TestString. Для добавления параметров вам нужно открыть окно менеджера проектов, выбрав из меню Project строку Show Project Manager. В этом окне проект draw должен быть текущим.
Выделите его курсором мыши в окне Java WorkShop Project Manager и из меню Project этого окна выберите строку Edit. Вы увидите блокнот Project Edit, с помощью которого можно изменять различные параметры проекта. Откройте в этом блокноте страницу Run (рис. 15).
 |
Рис. 15. Добавление параметра TestString
Для того чтобы увидеть рисунок в увеличенном виде, сделайте щелчок мышью по изображению |
В полях Name и Value введите, соответственно, имя параметра и значение параметра по умолчанию, а затем нажмите кнопку Add. Добавленный вами параметр появится в списке Parameters. Теперь вам осталось только нажать кнопку OK.
Рисование геометрических фигур
Назад Вперед
В этом разделе мы опишем методы класса Graphics, предназначенные для рисования элементарных геометрических фигур, таких как линии, прямоугольники, окружности и так далее.
Рисование в окне аплета
Назад Вперед
В предыдущем разделе мы привели простейший пример аплета, который выполняет рисование текстовой строки в своем окне. Теперь мы расскажем вам о том, что и как может рисовать аплет.
Способ, которым аплет выполняет рисование в своем окне, полностью отличается от того, которым пользуются программы MS-DOS. Вместо того чтобы обращаться напрямую или через драйвер к регистрам видеоконтроллера, аплет пользуется методами из класса Graphics. Эти методы инкапсулируют все особенности аппаратуры, предоставляя в распоряжение программиста средство рисования, которое пригодно для любой компьютерной платформы.
Для окна аплета создается объект класса Graphics, ссылка на который передается методу paint. Раньше мы уже пользовались этим объектом, вызывая для него метод drawString, рисующий в окне текстовую строку. Объект, ссылка на который передается методу paint, и есть контекст отображения. Сейчас мы займемся контекстом отображения вплотную.
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Сегменты
Метод drawArc предназначен для рисования незаполненного сегмента (рис. 10). Прототип этого метода приведен ниже:
public abstract void drawArc( int x, int y, int width, int height, int startAngle, int arcAngle);

Рис. 10. Рисование незаполненного сегмента
Параметры x, y, width и height задают координаты прямоугольника, в который вписан сегмент.
Параметры startAngle и arcAngle задаются в градусах. Они определяют, соответственно, начальный угол и угол разворота сегмента.
Для того чтобы нарисовать заполненный сегмент, вы можете воспользоваться методом fillArc:
public abstract void fillArc(int x, int y, int width, int height, int startAngle, int arcAngle);
Ссылочные типы
Итак, выражение ссылочного типа имеет значение либо null, либо ссылку, указывающую на некоторый объект в виртуальной памяти JVM.
ToString()
Этот метод позволяет получить текстовое описание любого объекта. Создавая новый класс, данный метод можно переопределить и возвращать более подробное описание. Для класса Object и его наследников, не переопределивших toString(), метод возвращает следующее выражение:
getClass().getName()+"@"+hashCode()
Метод getName() класса Class уже приводился в пример, а хэш-код еще дополнительно обрабатывается специальной функцией для представления в шестнадцатеричном формате.
Например:
print(new Object());
Результатом будет:
java.lang.Object@92d342
В результате этот метод позволяет по текстовому описанию понять, от какого класса был порожден объект и, благодаря хеш-коду, различать разные объекты, созданные от одного класса.
Именно этот метод вызывается при конвертации объекта в текст, когда он передается в качестве аргумента оператору конкатенации строк.
Установка атрибутов контекста отображения
Назад Вперед
Изменяя атрибуты контекста отображения, приложение Java может установить цвет для рисования графических изображений, таких как линии и многоугольники, шрифт для рисования текста, режим рисования и маску. Возможен также сдвиг начала системы координат.
Java является строго типизированным языком.
Java является строго типизированным языком. Это означает, что любая переменная и любое выражение имеют известный тип еще на момент компиляции. Такое строгое правило позволяет выявлять многие ошибки уже во время компиляции. Компилятор, найдя ошибку, указывает точное место (строку) и причину ее возникновения, а динамические "баги" (от английского bugs) необходимо сначала выявить с помощью тестирования (что может потребовать значительных усилий), а затем найти место в коде, которое их породило. Поэтому четкое понимание модели типов данных в Java очень помогает в написании качественных программ.
Все типы данных разделяются на две группы. Первую составляют 8 простых, или примитивных (от английского primitive), типов данных. Они подразделяются на три подгруппы:
целочисленные byteshortintlongchar (также является целочисленным типом)
дробные floatdouble
булевский boolean
Вторую группу составляют объектные, или ссылочные (от английского reference), типы данных. Это все классы, интерфейсы и массивы. В стандартных библиотеках первых версий Java находилось несколько сот классов и интерфейсов, сейчас их уже тысячи. Кроме стандартных, написаны многие и многие классы и интерфейсы, составляющие любую Java-программу.
Иллюстрировать логику работы с типами данных проще всего на примере переменных.
Выбор цвета
Изменение цвета, выбранного в контекст отображения, выполняется достаточно часто. В классе Graphics для изменения цвета определен метод setColor, прототип которого представлен ниже:
public abstract void setColor(Color c);
В качестве параметра методу setColor передается ссылка на объект класса Color, с помощью которого можно выбрать тот или иной цвет.
Как задается цвет?
Для этого можно использовать несколько способов.
Прежде всего, вам доступны статические объекты, определяющие фиксированный набор основных цветов:
| Объект | Цвет |
| public final static Color black; | черный |
| public final static Color blue; | голубой |
| public final static Color cyan; | циан |
| public final static Color darkGray; | темно-серый |
| public final static Color gray; | серый |
| public final static Color green; | зеленый |
| public final static Color lightGray; | светло-серый |
| public final static Color magenta; | малиновый |
| public final static Color orange; | оранжевый |
| public final static Color pink; | розовый |
| public final static Color red; | красный |
| public final static Color white; | белый |
| public final static Color yellow; | желтый |
Этим набором цветов пользоваться очень просто:
public void paint(Graphics g) { g.setColor(Color.yellow); g.drawString("Hello, Java world!", 10, 20); . . . }
Здесь мы привели фрагмент исходного текста метода paint, в котором в контексте отображения устанавливается желтый цвет. После этого метод drawString выведет текстовую строку " Hello, Java world!" желтым цветом.
Если необходима более точная установка цвета, вы можете воспользоваться одним из трех конструкторов объекта Color:
public Color(float r, float g, float b); public Color(int r, int g, int b); public Color(int rgb);
Первые два конструктора позволяют задавать цвет в виде совокупности значений трех основных цветовых компонент - красной, желтой и голубой (соответственно, параметры r, g и b). Для первого конструктора диапазон возможных значений компонент цвета находится в диапазоне от 0.0 до 1.0, а для второго - в диапазоне от 0 до 255.
Выбор шрифта
С помощью метода setFont из класса Graphics вы можете выбрать в контекст отображения шрифт, который будет использоваться методами drawString, drawBytes и drawChars для рисования текста. Вот прототип метода setFont:
public abstract void setFont(Font font);
В качестве параметра методу setFont следует передать объект класса Font.
Задание области ограничения
Если для окна аплета задать область ограничения, то рисование будет возможно только в пределах этой области. Область ограничения задается методом clipRect, прототип которого мы привели ниже:
public abstract void clipRect( int x, int y, int width, int height);
Параметры x, y, width и height задают координаты прямоугольной области ограничения.
одна из ключевых тем курса.
Типы данных – одна из ключевых тем курса. Невозможно написать ни одной программы, не используя их. Вот список некоторых операций, где применяются типы:
объявление типов;создание объектов;при объявлении полей – тип поля;при объявлении методов – входные параметры, возвращаемое значение;при объявлении конструкторов – входные параметры;оператор приведения типов;оператор instanceof;объявление локальных переменных;многие другие – обработка ошибок, import-выражения и т.д.
Принципиальные различия между примитивными и ссылочными типами данных будут рассматриваться и дальше по ходу курса. Изучение объектной модели Java даст основу для более подробного изложения объектных типов – обычных и абстрактных классов, интерфейсов и массивов. После приведения типов будут описаны связи между типом переменной и типом ее значения.
В обсуждении будущей версии Java 1.5 упоминаются темплейты (templates), которые существенно расширят понятия типа данных, если действительно войдут в стандарт языка.
В лекции было рассказано о том, что Java является строго типизированным языком, то есть тип всех переменных и выражений определяется уже компилятором. Это позволяет существенно повысить надежность и качество кода, а также делает необходимым понимание программистами объектной модели.
Все типы в Java делятся на две группы – фиксированные простые, или примитивные, типы (8 типов) и многочисленная группа объектных типов (классов). Примитивные типы действительно являются хранилищами данных своего типа. Ссылочные переменные хранят ссылку на некоторый объект совместимого типа. Они также могут принимать значение null, не указывая ни на какой объект. JVM подсчитывает количество ссылок на каждый объект и активизирует механизм автоматической сборки мусора для удаления неиспользуемых объектов.
Были рассмотрены переменные. Они характеризуются тремя основными параметрами – имя, тип и значение. Любая переменная должна быть объявлена и при этом может быть инициализирована. Возможно использование модификатора final.
Примитивные типы состоят из пяти целочисленных, включая символьный тип, двух дробных и одного булевского. Целочисленные литералы имеют ограничения, связанные с типами данных. Были рассмотрены все операторы над примитивными типами, тип возвращаемого значения и тонкости их использования.
Затем изучались объекты, способы их создания и операторы, выполняющие над ними различные действия, в частности принцип работы оператора instanceof. Далее были рассмотрены самые главные классы в Java – Object, Class, String.
